

第二次软工作业
论文查重系统
课程信息
作业目标
个人项目实现、测试报告等书写和总结
GitHub链接
PSP表格
| PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning | 30 | 30 |
| Estimate | 30 | 30 |
| Development | ||
| - Analysis | 300 | 300 |
| - Design Spec | 20 | 30 |
| - Design Review | 20 | 30 |
| - Coding Standard | 30 | 30 |
| - Design | 20 | 40 |
| - Coding | 140 | 180 |
| - Code Review | 20 | 30 |
| - Test | 250 | 200 |
| Reporting | ||
| - Test Report | 40 | 50 |
| - Size Measurement | 40 | 60 |
| - Postmortem & Process Improvement Plan | 40 | 30 |
| 合计 | 950 | 1010 |
计算模块接口设计与实现
该系统实现了一个简单但功能完整的中文文本相似度检测,核心是通过余弦相似度算法衡量文本相似度。代码结构清晰,模块化设计合理,具备一定的健壮性和扩展性。适用于小规模文本的相似度检测任务。
函数关系
plagiarism_checker.py (主程序)
├── 导入模块层
│ ├── jieba (中文分词)
│ ├── math (数学计算)
│ └── collections.Counter (词频统计)
├── 文本预处理层
│ └── preprocess() # 进行中文文本分词及停用词过滤
├── 相似度计算层
│ └── cosine_similarity() # 计算两个文本的余弦相似度
├── 核心算法层
│ └── main() # 程序入口,负责解析命令行参数,读取文件并计算相似度
├── 测试层
│ ├── test_identical_texts() # 测试完全相同文本的相似度
│ ├── test_completely_different_texts() # 测试完全不同文本的相似度
│ ├── test_partial_overlap_texts() # 测试部分重叠文本的相似度
│ ├── test_empty_and_non_empty_texts() # 测试空文本与非空文本的相似度
│ ├── test_single_word_match() # 测试相同单词文本的相似度
│ └── test_numeric_text_similarity() # 测试包含数字的文本的相似度
└── 文件I/O层
├── 读取文件操作 (在 main 函数中)
└── 写入结果操作 (在 main 函数中)
代码结构
- 依赖库导入:
jieba:用于对中文文本进行分词处理math:提供数学计算支持,主要用于计算向量的模argparse:用于解析命令行输入的参数collections.Counter:用于统计文本中的词频分布
- 全局常量:
stop_words:定义了一个停用词集合,用于去除文本中常见的无意义词语
- 文本预处理函数
preprocess:- 负责将输入的文本进行分词,并过滤掉停用词
- 余弦相似度计算函数
cosine_similarity:- 计算两个输入文本的余弦相似度,衡量它们的相似程度
- 主函数
main:- 负责解析命令行传入的参数,读取文本文件,调用相似度计算函数并输出结果
- 错误处理机制:
- 在文件读取和写入过程中,捕获并处理可能出现的异常(如
FileNotFoundError等)
- 在文件读取和写入过程中,捕获并处理可能出现的异常(如
关键设计点
- 分词与停用词过滤:
- 使用
jieba进行中文分词,确保文本处理的准确性 - 通过停用词列表过滤无意义词汇,减少噪声对相似度计算的影响
- 使用
- 余弦相似度计算:
- 将文本转换为词频向量,利用向量空间模型计算相似度
- 处理了向量模长为零的情况,避免除以零错误
- 命令行参数解析:
- 使用
argparse实现灵活的文件路径输入和输出
- 使用
性能分析
使用 snakeviz 生成性能分析报告。
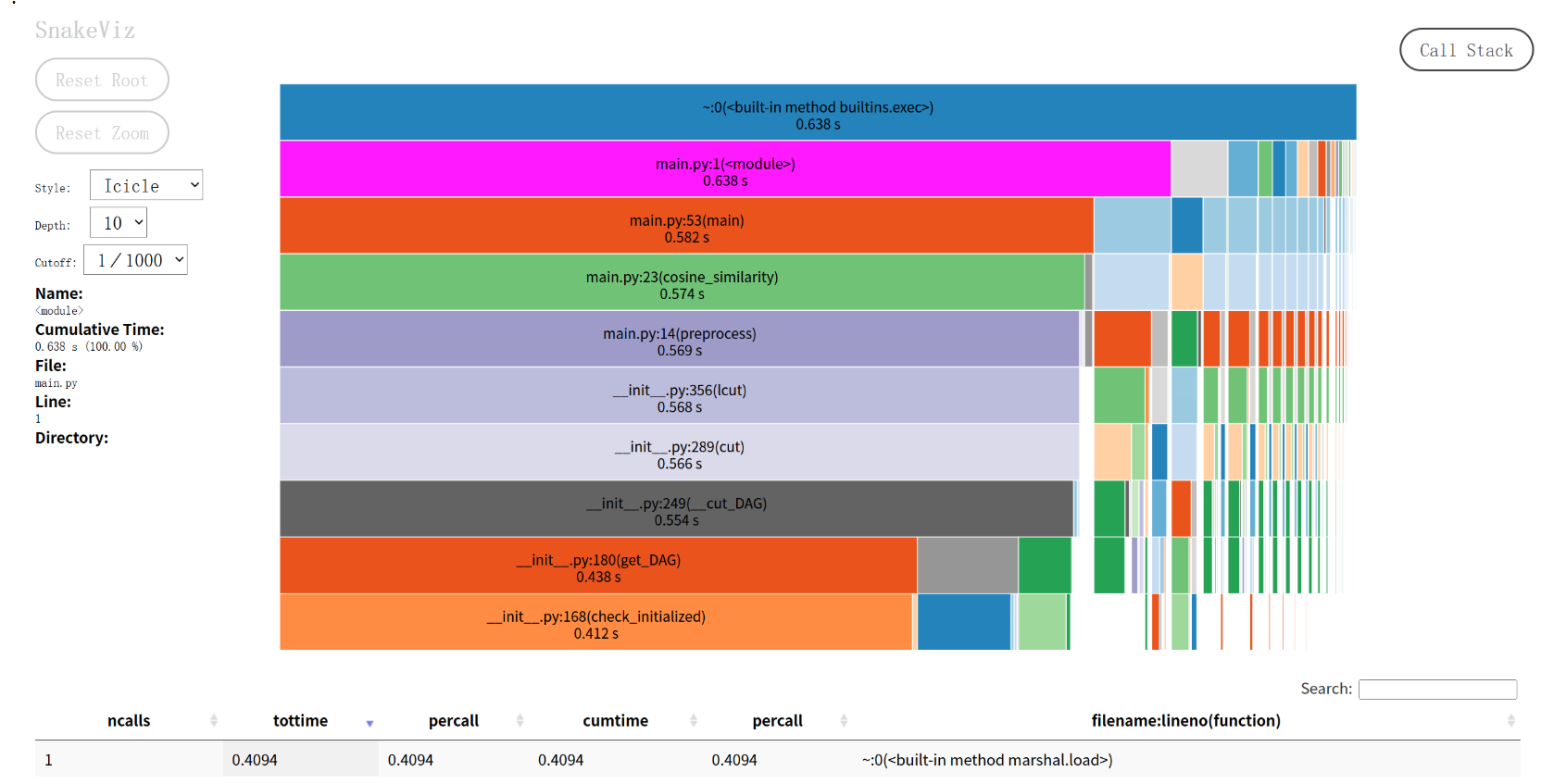
改进建议
- 优化分词过程
- 优化向量化过程
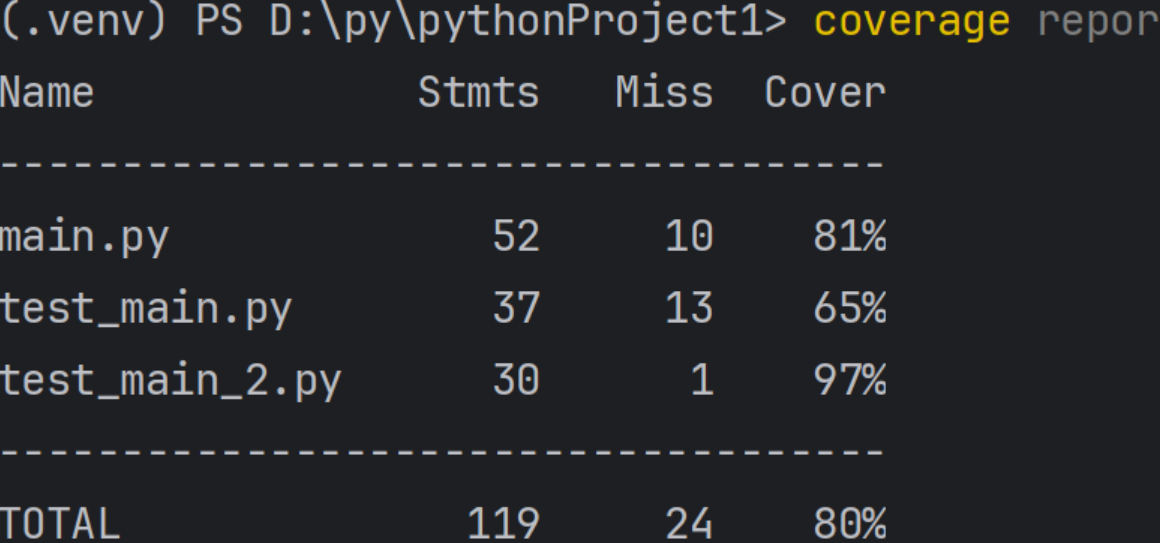
单元测试
单元测试覆盖率
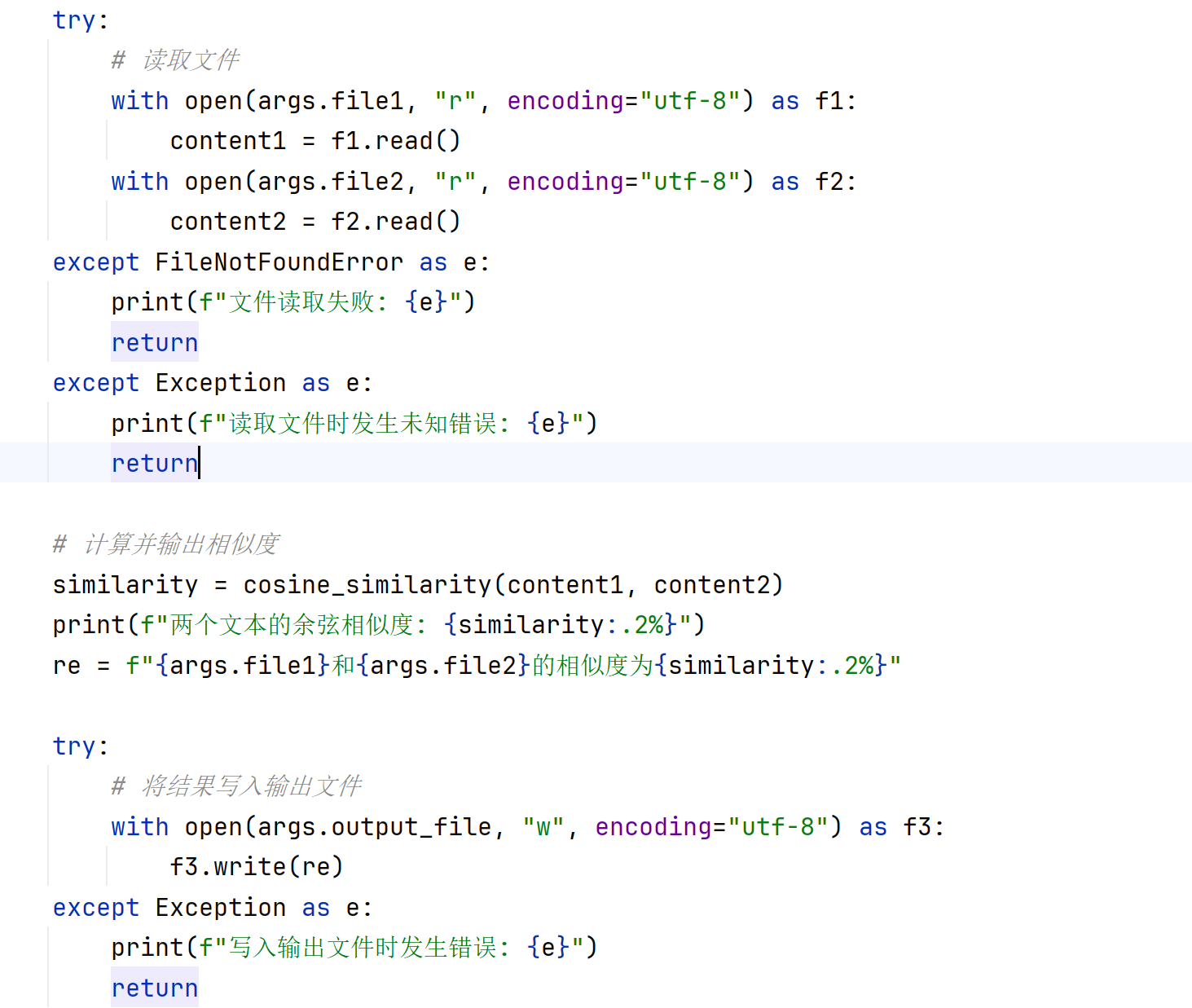
部分代码展示
部分异常处理:
部分单元测试代码:
def test_single_word_match(self):
"""测试完全相同的单词文本的相似度是否为 1"""
text1 = "Python"
text2 = "Python"
similarity = cosine_similarity(text1, text2)
self.assertEqual(similarity, 1.0)
def test_numeric_text_similarity(self):
"""测试包含数字的文本的相似度"""
text1 = "Python 3.9 发布了"
text2 = "Python 3.10 发布了"
similarity = cosine_similarity(text1, text2)
self.assertGreater(similarity, 0.0)
self.assertLess(similarity, 1.0)\`\`\`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号