实验五 文件应用编程
实验任务一
task1-1
实验源码
'''
统计文件data1.txt行数(不包括空白行)
data1.txt中的空白行包括由空格、Tab键(\t)、换行(\n)构成的空白行
'''
with open('data1.txt', 'r', encoding = 'utf-8') as f:
data = f.readlines()
n = 0
for line in data:
if not line.strip() == '':
n += 1
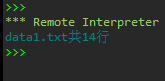
print(f'data1.txt共{n}行')
实验截图
task1-2
实验源码
'''
统计文件data1.txt行数(不包括空白行)
data1.txt中的空白行包括由空格、Tab键(\t)、换行(\n)构成的空白行
'''
with open('data1.txt', 'r', encoding = 'utf-8') as f:
n = 0
for line in f:
if not line.strip() == '':
n += 1
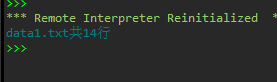
print(f'data1.txt共{n}行')
实验截图
task1-3
实验源码
'''
统计文件data1.txt行数(不包括空白行)
data1.txt中的空白行包括由空格、Tab键(\t)、换行(\n)构成的空白行
'''
with open('data1.txt', 'r', encoding = 'utf-8') as f:
n = 0
for line in f:
if not line.isspace():
n += 1
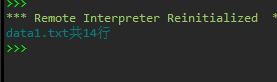
print(f'data1.txt共{n}行')
实验截图
实验任务二
实验源码
'''
统计数据文件data2.txt中独特行的行数
并打印输出独特行
'''
with open('data2.txt', 'r', encoding = 'utf-8') as f:
data = f.read().split('\n')
unique_line_lst = []
for line in data:
if data.count(line) == 1:
unique_line_lst.append(line)
n = len(unique_line_lst)
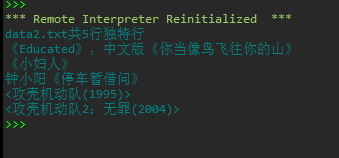
print(f'data2.txt共{n}行独特行')
for line in unique_line_lst:
print(line)
实验截图
实验任务三
task3-1
实验源码
'''
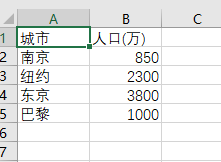
把城市、人口信息写入数据文件city1.csv
使用python内置的文件操作实现
'''
title = ['城市', '人口(万)']
info = [['南京', '850'],
['纽约', '2300'],
['东京', '3800'],
['巴黎', '1000']]
with open('city1.csv', 'w', encoding = 'gbk') as f:
f.write(','.join(title) + '\n') # 写入标题行
for item in info: # 分行写入info
f.write(','.join(
实验截图
task3-2
实验源码
'''
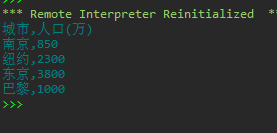
从文件city1.csv读取城市、人口信息,打印输出到屏幕
使用python内置的文件读写操作实现
'''
with open('city1.csv', 'r', encoding = 'gbk') as f:
data = f.read()
print(data.rstrip('\n'))
实验截图
task3-3
实验源码
'''
从文件city1.csv读取城市、人口信息,将其保存到里列表对象,保存形式诸如:
info = [ ['城市', '人口(万)'],
['南京', '850'],
['纽约', '2300'],
['东京', '3800'],
['巴黎', '1000'] ]
在屏幕上打印输出列表对象
使用python内置的文件读写操作实现
'''
with open('city1.csv', 'r', encoding = 'gbk') as f:
data = f.readlines()
# 打印中间处理结果(供查看)
print('data: ')
print(data)
info = [line.strip('\n').split(',') for line in data]
print('info:')
print(info)
实验截图

task3-4
实验源码
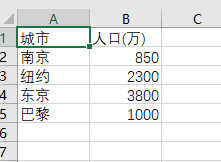
import csv
title = ['城市', '人口(万)']
info = [['南京', '850'],
['纽约', '2300'],
['东京', '3800'],
['巴黎', '1000']]
with open('city2.csv', 'w', encoding = 'gbk', newline = '') as f:
f_writer = csv.writer(f) # 为文件对象f创建一个writer对象
f_writer.writerow(title) # 通过writer对象的方法writerow()写入一行(标题行)
f_writer.writerows(info) # 通过writer对象的方法writerows()写入多行
task3-5
实验源码
'''
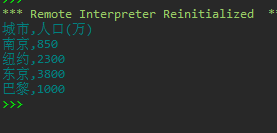
从文件city2.csv读取城市、人口信息,在屏幕上打印输出
使用python标准模块csv实现
'''
import csv
with open('city2.csv', 'r', encoding = 'gbk') as f:
f_reader = csv.reader(f) # 为文件对象f创建一个reader对象
for line in f_reader:
print(line)
实验截图
实验任务四
实验源码
'''
列出当前目录下所有.py文件
'''
import os, sys
print(os.path.basename(os.getcwd()))
# 将当前路径下所有.py文件名保存到py_file_lst中
py_file_lst = [file for file in os.listdir() if file.endswith('.py')]
# 遍历输出
for number, file in enumerate(py_file_lst, 1):
print(f'{number:-3d}. {file}')
实验截图
实验任务五
实验截图
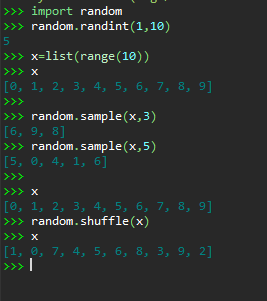
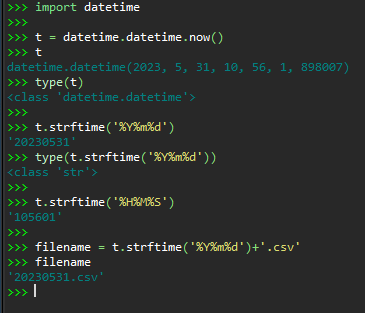
实验任务六
实验源码
with open('data6.csv','r',encoding='gbk') as f:
data = f.readlines()
data1=[str(eval(data[i])) for i in range(1,len(data))]
data2=[str(int(eval(data[i])+0.5)) for i in range(1,len(data))]
info=[[data1[i],data2[i]] for i in range(len(data1)) ]
title = ['原始数据','四舍五入后数据']
with open('data6_processed.csv', 'w', encoding = 'gbk') as f:
f.write(','.join(title) + '\n') # 写入标题行
for item in info:
f.write(','.join(item) + '\n')
ls1 = []
ls2 = []
with open('data6_processed.csv', 'r', encoding = 'gbk') as f:
data3=f.readlines()
for i in range(1,len(data3)):
data4=data3[i].split(',')
ls1.append(data4[0].strip())
ls2.append(data4[1].strip())
print('原始数据')
print(ls1)
print('四舍五入后数据')
print(ls2)
实验截图

实验任务七
task7-1
实验源码
#实验五
#实验任务七
with open('data7.csv','r',encoding='gbk') as f:
data1 = f.read().split('\n')
del data1[0]
lsta = []
lstm = []
for i in data1:
lst1 = i.split(',')
if lst1[2] == 'Acting':
lsta.append(lst1)
else:lstm.append(lst1)
lstm.sort(key=lambda x:x[-1],reverse = True)
lsta.sort(key=lambda x:x[-1],reverse = True)
info = lsta + lstm
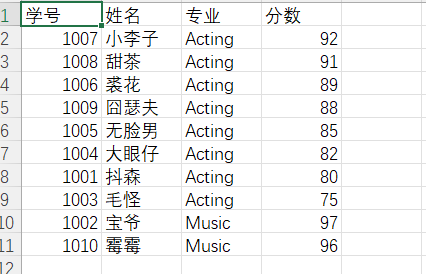
title = ['学号','姓名','专业','分数']
with open('data7_processed.csv','w',encoding='utf-8') as f:
f.write(','.join(title)+'\n')
for items in info:
f.write(','.join(items)+'\n')
print('{:<10}'.format(title[0]),'{:<10}'.format(title[1]),'{:<10}'.format(title[2]),'{:<15}'.format(title[3]))
for i in info:
print('{:<10}'.format(i[0]),'{:<10}'.format(i[1]),'{:<10}'.format(i[2]),'{:<15}'.format(i[3]))
实验截图
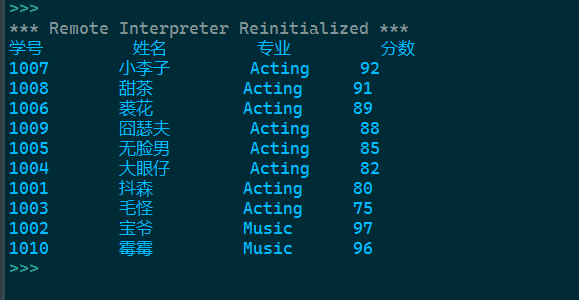
实验任务八
实验源码
lines = 0
words = 0
sum1 = 0
space = 0
with open('hamlet.txt','r',encoding='utf-8') as f:
for line in f:
word = line.split()
lines += 1
words += len(word)
sum1 += len(line)
for i in line:
if i == ' ':
space += 1
else:
pass
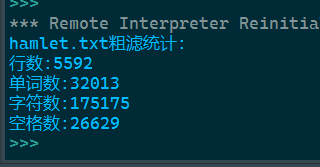
print('hamlet.txt粗滤统计:')
print(f'行数:{lines}')
print(f'单词数:{words}')
print(f'字符数:{sum1}')
print(f'空格数:{space}')
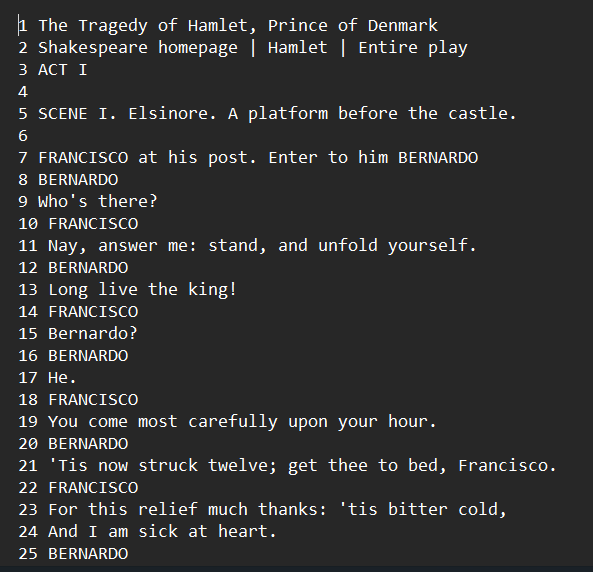
with open('hamlet.txt','r',encoding = 'utf-8') as f:
text = f.readlines()
for i in range(len(text)):
text[i] = str(i+1) + ' ' + text[i]
with open('hamlet_with_line_number.txt','w',encoding = 'utf-8') as f:
f.writelines(text)
实验截图
实验任务九
实验源码
def is_valid(sfz):
if len(sfz) != 18:
return False
elif (sfz[:-1].isnumeric() and sfz[-1] == 'X') or sfz.isnumeric():
return True
else:return False
with open('data9_id.txt','r',encoding='utf-8') as f:
data = f.read().split('\n')
del data[0]
data2 = []
data3 =[]
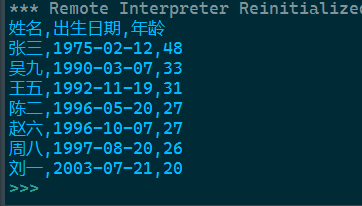
print('姓名,出生日期,年龄')
for i in data:
lst = i.split(',')
data2.append(lst)
lst2 = []
for i in data2:
if is_valid(i[1]) == True:
name = i[0]
btd = i[1][6:14]
age = str(2023 - int(i[1][6:10]))
lst2.append([name,btd,age])
lst2.sort(key=lambda x:x[2],reverse=True)
for i in lst2:
print(i[0],end=',')
print(f'{i[1][:4]}-{i[1][4:6]}-{i[1][6:8]}',end=',')
print(i[2])
实验截图
实验任务十
实验源码
with open('data10_stu.txt','r',encoding='utf-8') as f:
data = f.readlines()
print('{:*^40}'.format('抽点开始'))
n = int(input('输入随机抽点人数:'))
import random
x = []
x2 = ''
counts = 0
while counts < n:
new = random.randint(0, len(data) - 1)
if new in x:
new = random.randint(0, len(data) - 1)
else:
counts +=1
x.append(new)
sum1 = 0
for i in range(n):
print(data[x[i]])
x2 += data[x[i]]
sum1 += n
with open('20230602.txt','w',encoding='utf-8') as f:
f.writelines(x2)
实验截图


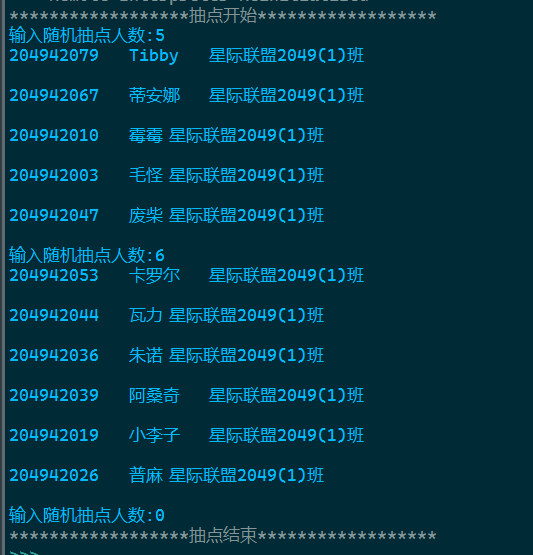
task10-2
实验源码
with open('data10_stu.txt','r',encoding='utf-8') as f:
data = f.readlines()
print('{:*^40}'.format('抽点开始'))
n = int(input('输入随机抽点人数:'))
import random
x = []
sum1 = 0
x2 = ''
while n != 0:
counts = 0
while counts < n:
new = random.randint(0, len(data) - 1)
if new in x:
new = random.randint(0, len(data) - 1)
else:
counts +=1
x.append(new)
for i in range(sum1,sum1+n):
print(data[x[i]])
x2 += data[x[i]]
sum1 += n
n = int(input('输入随机抽点人数:'))
with open('20230602.txt','w',encoding='utf-8') as f:
f.writelines(x2)
print('{:*^40}'.format('抽点结束'))
实验截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号