

【python数据分析课程设计】大数据分析——共享单车使用量可视化分析
一、选题的背景
共享单车在当今社会中扮演着重要角色,对城市交通、环境、个人出行习惯等方面产生了显著影响。通过分析这些数据,可以了解共享单车对城市生活的影响,对交通拥堵、空气质量改善、促进健康出行提供便利。通过分析共享单车数据,可以了解技术创新在这一领域的应用情况,探索改进现有技术或者开发新技术的可能性。
数据分析目标:单车使用量,游客用户和注册用户数量,假期和工作日使用情况的差异,每个季节的单车使用情况。
数据来源:http://www.idatascience.cn/dataset-detail?table_id=100102
数据集:gongxiang.csv
二、大数据分析设计方案
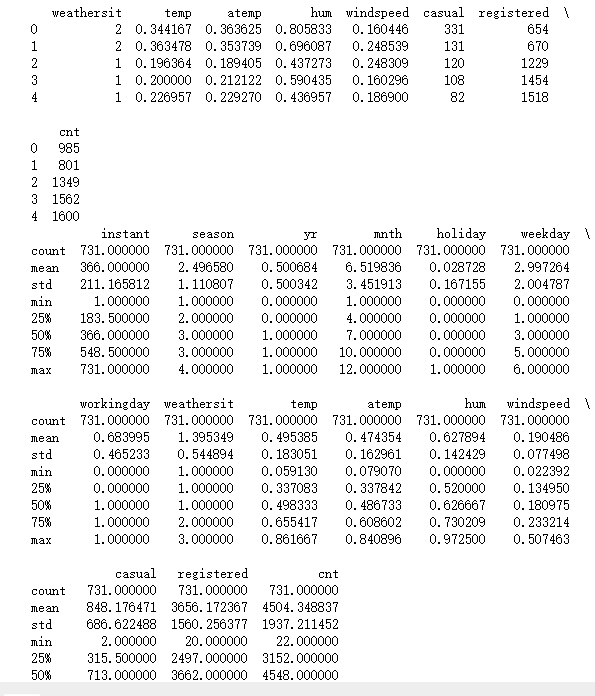
数据内容与数据特征分析总共16个字段:

数据分析的课程设计方案概述:
获取共享单车数据集,并使用数据清洗处理缺失值、异常值、重复项,确保数据质量,然后对数据进行可视化分析。
实现思路:使用Python的Pandas库进行数据清洗、整合和初步探索,并使用Plotly库进行数据可视化分析。
技术难点:处理大规模数据时可能遇到内存和计算资源限制;分析出来的图像模型的准确性相差太多,需要适当优化。
三、大数据分析实验
数据源:采用的爱数科上开放的数据集http://www.idatascience.cn/dataset-detail?table_id=100102
数据集清洗
先读取数据集共享单车需求数据集 ,数据集包含在共享系统中出租的共享单车的数量,以及相应的天气数据,工作日和假日信息,在处理缺失值、异常值、重复项,确保数据质量。
import pandas as pd
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 查看数据
print(df.head())
# 输出数据的基本统计信息
print(df.describe())
# 将清洗后的数据保存到新的CSV文件中
df.to_csv('new_gongxiang.csv', index=False)实验效果:
四、可视化分析
利用直方图组件分析共享单车使用量
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'cnt' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制单车使用量分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['cnt'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Cnt Distribution')
plt.xlabel('Cnt')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()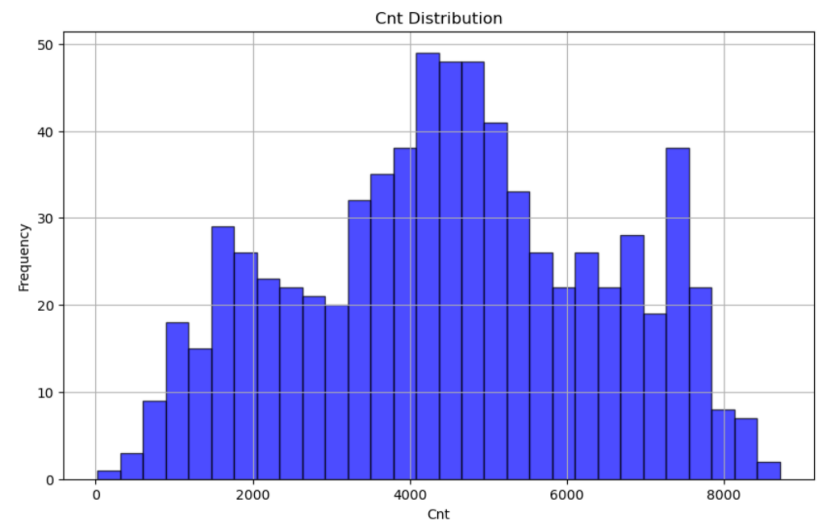
由上图可以看到,租车数量在4000-5000这个区间最多。
分析温度分布直方图
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'temp' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制温度分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['temp'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Temp Distribution')
plt.xlabel('Temp')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()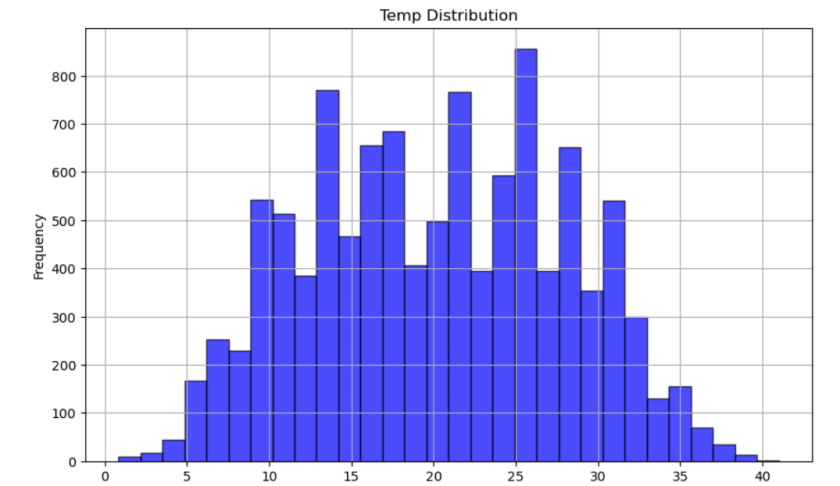
由上图可知,租车时的温度多集中在14-27摄氏度这个区间内。
分析查看风速分布直方图
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'cnt' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制风速分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['windspeed'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Windspeed Distribution')
plt.xlabel('windspeed')
plt.ylabel('Frequency')
plt.grid(True)
plt.show(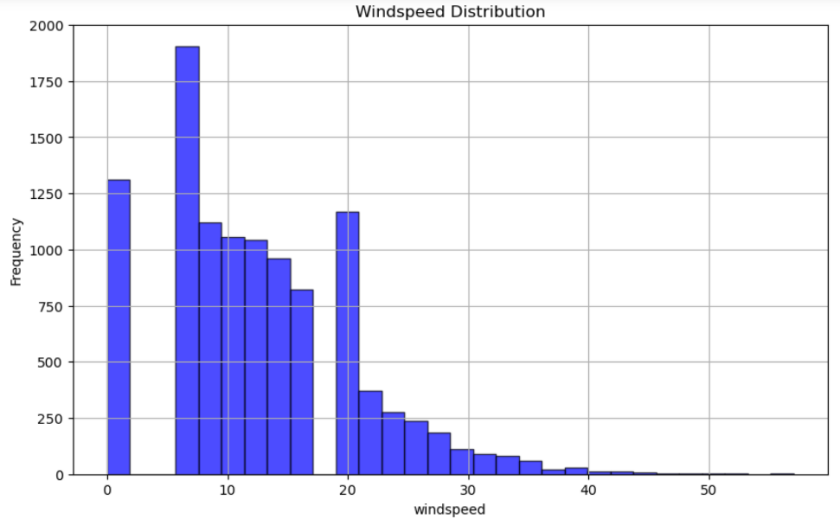
由上图可知,风速达到20m/s时,租车数量开始明显减少。
使用散点图分析温度与单车使用量之间的关系
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保温度和单车使用量是数值类型
df['atemp'] = pd.to_numeric(df['atemp'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制温度与单车使用量的散点图
plt.scatter(df['atemp'], df['cnt'])
plt.xlabel('atemp')
plt.ylabel('Cnt')
plt.title('atemp vs Cnt')
plt.show()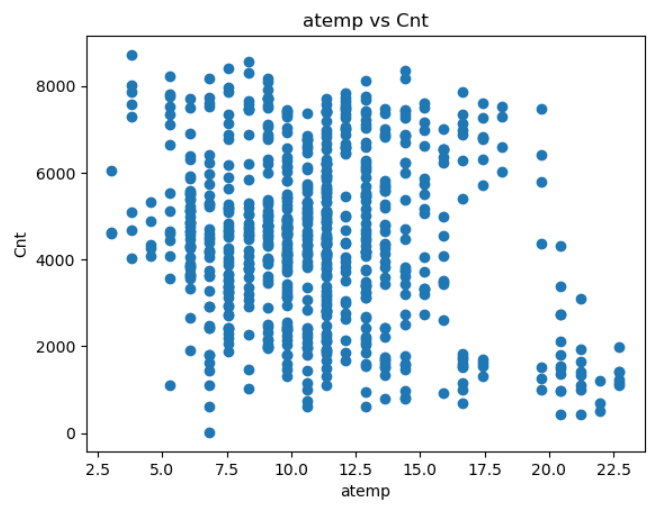
从上图中可以看到随着温度的升高租车量越来越少。
利用散点图分析探索湿度与单车使用量之间的关系
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保湿度和单车使用量是数值类型
df['hun'] = pd.to_numeric(df['hum'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制湿度与单车使用量的散点图
plt.scatter(df['hum'], df['cnt'])
plt.xlabel('Hum')
plt.ylabel('Cnt')
plt.title('Hum vs Cnt')
plt.show()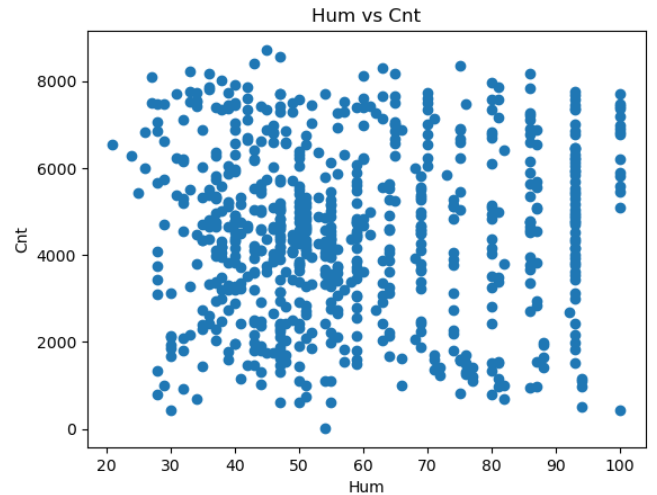
由上图可知,随着湿度的上升或下降,单车租用数量没有明显的变化趋势。
使用散点图分析探索风速与单车使用量之间的关系
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保风速和单车使用量是数值类型
df['windspeed'] = pd.to_numeric(df['windspeed'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制风速与单车使用量的散点图
plt.scatter(df['windspeed'], df['cnt'])
plt.xlabel('Windspeed')
plt.ylabel('Cnt')
plt.title('Windspeed vs Cnt')
plt.show() 
由上图可知,在风速达到20m/s之前,随着风速的增加,租车数量有着先增加后减少的趋势,但是当风速达到30m/s后,租车数量急剧减少。
利用柱状图查看分析假期分布情况
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 表示假期天数
vacation_days = df['holiday']
# 统计每个假期天数的频率
frequency = vacation_days.value_counts()
# 绘制柱状图
plt.bar(frequency.index, frequency.values)
plt.xlabel('HoliDay')
plt.ylabel('No HoliDay')
plt.title('No HoliDay of HoliDay')
plt.show()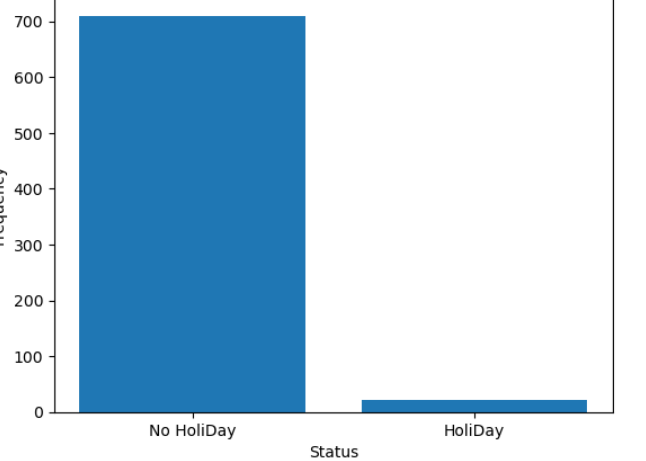
由上图可以知道非节假日的时候共享单车的使用量明显高于节假日,可初步判断共享单车的适用人群多为工作者。
使用柱状图分析季节分布情况
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
season_column = 'season'
# 创建一个季节映射字典,将数字映射为季节名称
season_mapping = {1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'}
# 将季节列的数字映射为对应的季节名称
df['season_name'] = df[season_column].map(season_mapping)
# 统计每个季节的频率
frequency = df['season_name'].value_counts()
# 绘制柱状图
plt.bar(frequency.index, frequency.values)
plt.xlabel('Season')
plt.ylabel('Frequency')
plt.title('Season Distribution')
plt.xticks(rotation=0) # 设置X轴标签的旋转角度为0(水平显示)
plt.show()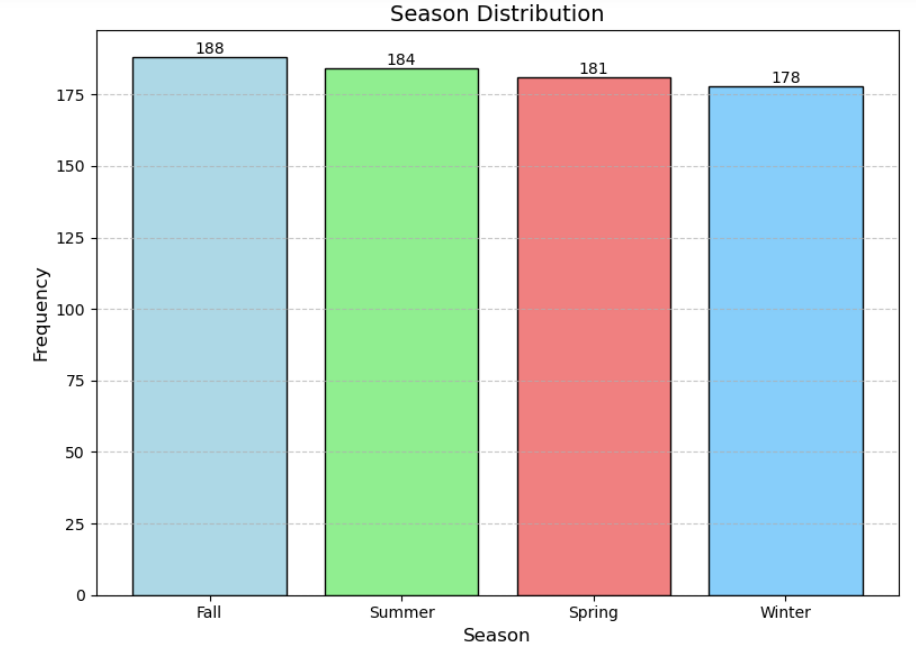
由上图可以得知共享单车的使用总量几乎不受季节的影响。
利用箱线图分析假期与单车使用量的关系。特征列选择 Cnt,分组列选择Holiday
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
holiday_column = 'holiday'
bike_usage_column = 'cnt'
# 映射假期列的值为对应的描述性标签
df['holiday'] = df[holiday_column].map({1: 'Holiday', 0: 'No Holiday'})
# 创建两个数据集,分别对应假日和非假日的单车使用量
no_holiday_data = df[df['holiday'] == 'No Holiday'][bike_usage_column]
holiday_data = df[df['holiday'] == 'Holiday'][bike_usage_column]
# 设置箱线图的样式和颜色
boxprops = dict(linestyle='-', linewidth=2, color='blue')
whiskerprops = dict(linestyle='--', linewidth=1.5, color='black')
medianprops = dict(linestyle='-', linewidth=2, color='red')
capprops = dict(linestyle='-', linewidth=1, color='black')
plt.figure(figsize=(8, 6))
# 绘制箱线图
plt.boxplot([no_holiday_data, holiday_data], labels=['No Holiday', 'Holiday'], boxprops=boxprops,
whiskerprops=whiskerprops, medianprops=medianprops, capprops=capprops)
plt.title('Box Plot of Bike Usage by Holiday Status', fontsize=16)
plt.xlabel('Holiday Status', fontsize=12)
plt.ylabel('Bike Count', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加水平网格线,调整透明度
plt.tight_layout()
plt.show()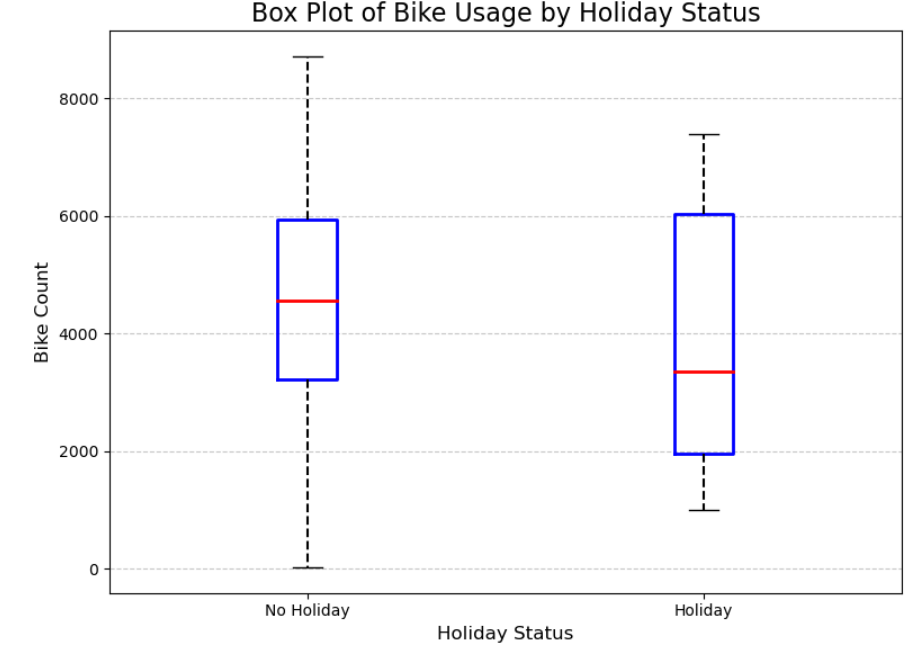
由上图可知,无节假日时候的使用量高于节假日时的使用量。
利用箱线图分析探究季节与单车使用量的关系。特征列选择 Cnt,分组列选择Season
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
season_column = 'season'
bike_usage_column = 'cnt'
# 将季节列的数字映射为春夏秋冬四个季节值
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
df['season_name'] = df[season_column].map(dict(zip(range(1, 5), seasons)))
# 创建每个季节对应的单车使用量数据集
seasonal_data = [df[df['season_name'] == season][bike_usage_column] for season in seasons]
# 设置箱线图的样式和颜色
boxprops = dict(linestyle='-', linewidth=2, color='blue')
whiskerprops = dict(linestyle='--', linewidth=1.5, color='black')
medianprops = dict(linestyle='-', linewidth=2, color='red')
capprops = dict(linestyle='-', linewidth=1, color='black')
plt.figure(figsize=(8, 6))
# 绘制箱线图
plt.boxplot(seasonal_data, labels=seasons, boxprops=boxprops,
whiskerprops=whiskerprops, medianprops=medianprops, capprops=capprops)
plt.title('Box Plot of Bike Usage by Season', fontsize=16)
plt.xlabel('Season', fontsize=12)
plt.ylabel('Bike Count', fontsize=12)
plt.xticks(rotation=45) # 设置X轴标签的旋转角度为45度
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加水平网格线,调整透明度
plt.tight_layout()
plt.show()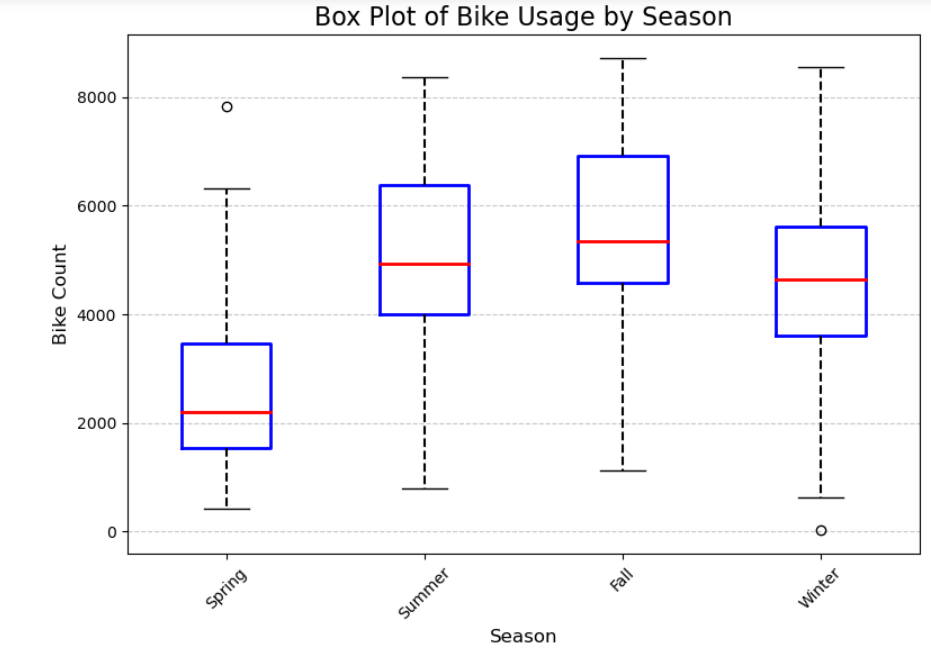
由上图可以看出夏季和秋季的共享单车的趋势用车量要大于冬季和春季。
根据天气情况分析游客用户的共享单车使用量
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
visitor_type_column = 'weathersit'
# 创建映射字典将数字值映射为描述性标签
weather_mapping = {1: 'Sunny', 2: 'Cloudy', 3: 'Light Rain'}
# 将数据中的数字值替换为描述性标签
df[visitor_type_column] = df[visitor_type_column].map(weather_mapping)
# 绘制饼状图,展示游客类型分布情况
plt.figure(figsize=(10, 7))
plt.pie(df[visitor_type_column].value_counts(), labels=df[visitor_type_column].unique(), autopct='%1.1f%%')
plt.title('Visitor Type Distribution')
plt.show()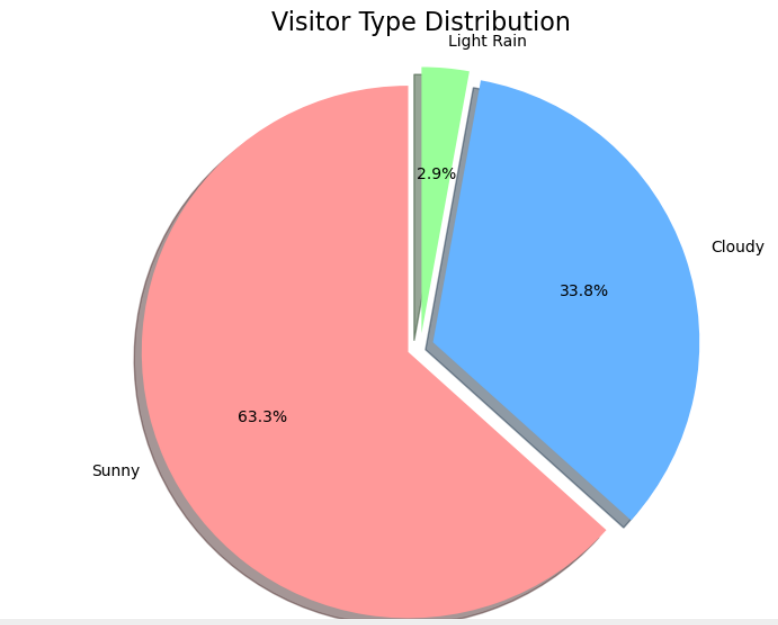
由上图可知晴天游客的使用量最多为63.3%,而阴天的情况占33.8%,雨天占2.9%,可以看出下雨天几乎不用共享单车。
利用点图分析用户在工作日共享单车的使用量
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
if not df['weekday'].dtype == 'int64':
raise ValueError("'weekday'列的数据类型不是整数类型")
# 提取周一到周六的租车量数据
df_weekdays = df[df['weekday'] < 6] # 假设1代表周一,2代表周二,以此类推,6代表周六
# 计算每天的租车量总和
total_rentals = df_weekdays['casual'].sum()
print(f"周一到周六的共享单车租车总量为:{total_rentals}辆")
# 设置图形大小为10x5英寸
plt.figure(figsize=(10, 5))
# 为每个星期的数据设置不同颜色的线条
plt.plot(df_weekdays[df_weekdays['weekday'] == 1]['weekday'], df_weekdays[df_weekdays['weekday'] == 1]['casual'], marker='o', label='Weekday 1', color='red')
plt.plot(df_weekdays[df_weekdays['weekday'] == 2]['weekday'], df_weekdays[df_weekdays['weekday'] == 2]['casual'], marker='o', label='Weekday 2', color='blue')
plt.plot(df_weekdays[df_weekdays['weekday'] == 3]['weekday'], df_weekdays[df_weekdays['weekday'] == 3]['casual'], marker='o', label='Weekday 3', color='green')
plt.plot(df_weekdays[df_weekdays['weekday'] == 4]['weekday'], df_weekdays[df_weekdays['weekday'] == 4]['casual'], marker='o', label='Weekday 4', color='orange')
plt.plot(df_weekdays[df_weekdays['weekday'] == 5]['weekday'], df_weekdays[df_weekdays['weekday'] == 5]['casual'], marker='o', label='Weekday 5', color='purple')
plt.title('Daily Bike Rentals') # 设置标题
plt.xlabel('Weekday') # 设置x轴标签
plt.ylabel('Rentals') # 设置y轴标签
plt.legend() # 添加图例显示每条线对应的星期
plt.show()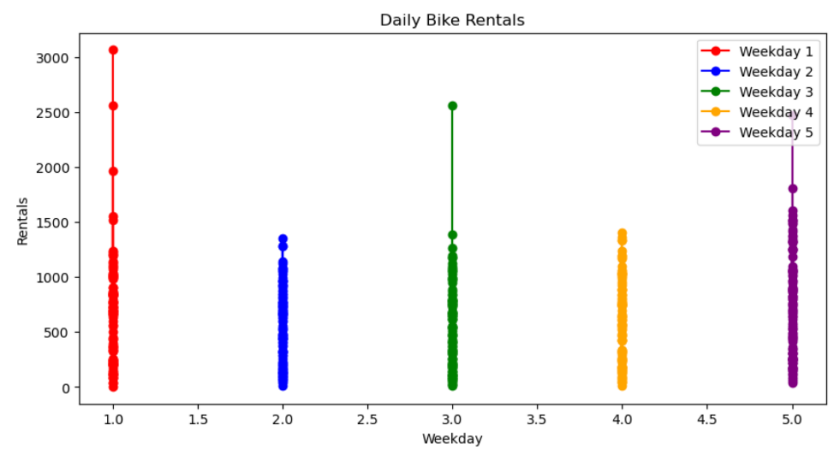
通过上图可以看出周一和周五的需求量最高,而其他三天偏少。
用盒图分析租车人数在各分类变量下情况
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取 CSV 文件
df = pd.read_csv('gongxiang.csv')
# 转换 'datetime' 列的格式
df['instant'] = pd.to_datetime(df['instant'])
# 设置 'datetime' 列为索引
df = df.set_index("instant")
# 提取时间信息
df['hour'] = df.index.hour
df['week'] = df.index.weekday
df['month'] = df.index.month
df['year'] = df.index.year
# 创建季节标签列
df['season_label'] = df['season'].map({1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'})
# 创建天气状况标签列
df['weathersit_label'] = df['weathersit'].map({1: 'Sunny', 2: 'Cloudy', 3: 'Rainly', 4: 'bad-day'})
# 绘制盒图
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(12, 10)
sns.boxplot(data=df, y="cnt", orient="v", ax=axes[0][0])
sns.boxplot(data=df, y="cnt", x="season", orient="v", ax=axes[0][1])
sns.boxplot(data=df, y="cnt", x="hour", orient="v", ax=axes[1][0])
sns.boxplot(data=df, y="cnt", x="workingday", orient="v", ax=axes[1][1])
axes[0][0].set(ylabel="Cnt", title="Box Plot On Cnt")
axes[0][1].set(xlabel='Season', ylabel='Cnt', title="Box Plot On Cnt Across Season")
axes[1][0].set(xlabel='Hour Of The Day', ylabel='Cnt', title="Box Plot On Cnt Across Hour Of The Day")
axes[1][1].set(xlabel='Working Day', ylabel='Cnt', title="Box Plot On Cnt Across Working Day")
plt.show()
从图1和图3可以看出租车量主要分布在3000-6000之间,从图2可以看出秋季的租车量达到最高,而图4可以看出节假日和工作日的租车人数是相同的。
用折线图分析需求量最大的夏季每小时平均租车人数
# 导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
# 读取 CSV 文件到 DataFrame 对象中
df = pd.read_csv('gongxiang.csv')
df['instant'] = pd.to_datetime(df[''])
df['season'] = df['instant'].dt.quarter
# 根据 'season' 和小时数对数据进行分组,计算季节每小时的 'cnt' 列的平均值,并将结果展平为一个 DataFrame
seasonal_hourly_data = df.groupby(['season', df['instant'].dt.hour])['cnt'].mean().unstack()
plt.figure(figsize=(12, 6))
# 将展平后的 DataFrame 进行转置,并绘制图形,使用 'o' 作为标记
seasonal_hourly_data.T.plot(marker='o')
plt.xlabel('Hour ')
plt.ylabel('Average Cnt')
plt.title('Average Cnt per Hour for Different Seasons')
plt.legend(title='Season', labels=['Spring',], bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()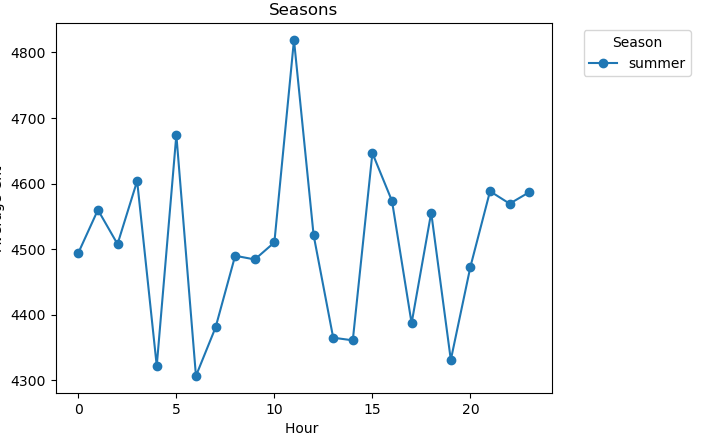
从图中可以看出共享单车需求量最大的时候达到5000+。
数据分析所有源代码:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 查看数据
print(df.head())
# 输出数据的基本统计信息
print(df.describe())
# 将清洗后的数据保存到新的CSV文件中
df.to_csv('new_gongxiang.csv', index=False)
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'atemp' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制温度分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['temp'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Temp Distribution')
plt.xlabel('Temp')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'cnt' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制单车使用量分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['cnt'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Cnt Distribution')
plt.xlabel('Cnt')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'hum' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制湿度分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['hum'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Hum Distribution')
plt.xlabel('Hum')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
file_name = 'gongxiang.csv'
data = pd.read_csv(file_name)
if 'cnt' not in data.columns:
print(f"Error: Column 'temperature' not found in {file_name}")
else:
# 绘制风速分布的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['windspeed'], bins=30, edgecolor='black', color='blue', alpha=0.7)
plt.title('Windspeed Distribution')
plt.xlabel('windspeed')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保温度和单车使用量是数值类型
df['atemp'] = pd.to_numeric(df['atemp'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制温度与单车使用量的散点图
plt.scatter(df['atemp'], df['cnt'])
plt.xlabel('atemp')
plt.ylabel('Cnt')
plt.title('atemp vs Cnt')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保湿度和单车使用量是数值类型
df['hun'] = pd.to_numeric(df['hum'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制湿度与单车使用量的散点图
plt.scatter(df['hum'], df['cnt'])
plt.xlabel('Hum')
plt.ylabel('Cnt')
plt.title('Hum vs Cnt')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 确保风速和单车使用量是数值类型
df['windspeed'] = pd.to_numeric(df['windspeed'], errors='coerce')
df['cnt'] = pd.to_numeric(df['cnt'], errors='coerce')
# 绘制风速与单车使用量的散点图
plt.scatter(df['windspeed'], df['cnt'])
plt.xlabel('Windspeed')
plt.ylabel('Cnt')
plt.title('Windspeed vs Cnt')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 表示假期天数
vacation_days = df['holiday']
# 统计每个假期天数的频率
frequency = vacation_days.value_counts()
# 修改x轴的显示值
frequency.index = ['No HoliDay', 'HoliDay']
# 绘制柱状图
plt.bar(frequency.index, frequency.values)
plt.xlabel('Status') # 修改x轴标签为'Status'
plt.ylabel('Frequency') # 修改y轴标签为'Frequency'
plt.title('Frequency of HoliDay Status') # 修改标题为'Frequency of HoliDay Status'
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
season_column = 'season'
# 创建一个季节映射字典,将数字映射为季节名称
season_mapping = {1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'}
# 将季节列的数字映射为对应的季节名称
df['season_name'] = df[season_column].map(season_mapping)
# 统计每个季节的频率
frequency = df['season_name'].value_counts()
# 设置柱状图的颜色和边界颜色
colors = ['lightblue', 'lightgreen', 'lightcoral', 'lightskyblue']
# 绘制柱状图
plt.figure(figsize=(8, 6))
bars = plt.bar(frequency.index, frequency.values, color=colors, edgecolor='black')
# 添加数据标签
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval + 0.05, round(yval, 2), ha='center', va='bottom', fontsize=10)
plt.xlabel('Season', fontsize=12)
plt.ylabel('Frequency', fontsize=12)
plt.title('Season Distribution', fontsize=14)
plt.xticks(rotation=0) # 设置X轴标签的旋转角度为0(水平显示)
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加水平网格线,调整透明度
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
holiday_column = 'holiday'
bike_usage_column = 'cnt'
# 映射假期列的值为对应的描述性标签
df['holiday'] = df[holiday_column].map({1: 'Holiday', 0: 'No Holiday'})
# 创建两个数据集,分别对应假日和非假日的单车使用量
no_holiday_data = df[df['holiday'] == 'No Holiday'][bike_usage_column]
holiday_data = df[df['holiday'] == 'Holiday'][bike_usage_column]
# 设置箱线图的样式和颜色
boxprops = dict(linestyle='-', linewidth=2, color='blue')
whiskerprops = dict(linestyle='--', linewidth=1.5, color='black')
medianprops = dict(linestyle='-', linewidth=2, color='red')
capprops = dict(linestyle='-', linewidth=1, color='black')
plt.figure(figsize=(8, 6))
# 绘制箱线图
plt.boxplot([no_holiday_data, holiday_data], labels=['No Holiday', 'Holiday'], boxprops=boxprops,
whiskerprops=whiskerprops, medianprops=medianprops, capprops=capprops)
plt.title('Box Plot of Bike Usage by Holiday Status', fontsize=16)
plt.xlabel('Holiday Status', fontsize=12)
plt.ylabel('Bike Count', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加水平网格线,调整透明度
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
season_column = 'season'
bike_usage_column = 'cnt'
# 将季节列的数字映射为春夏秋冬四个季节值
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
df['season_name'] = df[season_column].map(dict(zip(range(1, 5), seasons)))
# 创建每个季节对应的单车使用量数据集
seasonal_data = [df[df['season_name'] == season][bike_usage_column] for season in seasons]
# 设置箱线图的样式和颜色
boxprops = dict(linestyle='-', linewidth=2, color='blue')
whiskerprops = dict(linestyle='--', linewidth=1.5, color='black')
medianprops = dict(linestyle='-', linewidth=2, color='red')
capprops = dict(linestyle='-', linewidth=1, color='black')
plt.figure(figsize=(8, 6))
# 绘制箱线图
plt.boxplot(seasonal_data, labels=seasons, boxprops=boxprops,
whiskerprops=whiskerprops, medianprops=medianprops, capprops=capprops)
plt.title('Box Plot of Bike Usage by Season', fontsize=16)
plt.xlabel('Season', fontsize=12)
plt.ylabel('Bike Count', fontsize=12)
plt.xticks(rotation=45) # 设置X轴标签的旋转角度为45度
plt.grid(axis='y', linestyle='--', alpha=0.7) # 添加水平网格线,调整透明度
plt.tight_layout()
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
visitor_type_column = 'weathersit'
# 创建映射字典将数字值映射为描述性标签
weather_mapping = {1: 'Sunny', 2: 'Cloudy', 3: 'Light Rain'}
# 将数据中的数字值替换为描述性标签
df[visitor_type_column] = df[visitor_type_column].map(weather_mapping)
# 设置颜色和阴影
colors = ['#ff9999', '#66b3ff', '#99ff99']
explode = (0.05, 0.05, 0.05) # 突出显示某个部分
# 统计每个标签的数量
label_counts = df[visitor_type_column].value_counts()
# 绘制饼状图,确保标签和数据长度匹配
plt.figure(figsize=(10, 7))
plt.pie(label_counts, labels=label_counts.index, autopct='%1.1f%%',
colors=colors, startangle=90, explode=explode, shadow=True)
plt.title('Visitor Type Distribution', fontsize=16)
# 调整标签字体大小
plt.tick_params(labelsize=12)
plt.axis('equal') # 确保是一个圆形
# 显示图表
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
if not df['weekday'].dtype == 'int64':
raise ValueError("'weekday'列的数据类型不是整数类型")
# 提取周一到周六的租车量数据
df_weekdays = df[df['weekday'] < 6] # 假设1代表周一,2代表周二,以此类推,6代表周六
# 计算每天的租车量总和
total_rentals = df_weekdays['casual'].sum()
print(f"周一到周六的共享单车租车总量为:{total_rentals}辆")
# 设置图形大小为10x5英寸
plt.figure(figsize=(10, 5))
# 为每个星期的数据设置不同颜色的线条
plt.plot(df_weekdays[df_weekdays['weekday'] == 1]['weekday'],
df_weekdays[df_weekdays['weekday'] == 1]['casual'], marker='o',
label='Weekday 1', color='red')
plt.plot(df_weekdays[df_weekdays['weekday'] == 2]['weekday'],
df_weekdays[df_weekdays['weekday'] == 2]['casual'], marker='o',
label='Weekday 2', color='blue')
plt.plot(df_weekdays[df_weekdays['weekday'] == 3]['weekday'],
df_weekdays[df_weekdays['weekday'] == 3]['casual'], marker='o',
label='Weekday 3', color='green')
plt.plot(df_weekdays[df_weekdays['weekday'] == 4]['weekday'],
df_weekdays[df_weekdays['weekday'] == 4]['casual'], marker='o',
label='Weekday 4', color='orange')
plt.plot(df_weekdays[df_weekdays['weekday'] == 5]['weekday'],
df_weekdays[df_weekdays['weekday'] == 5]['casual'], marker='o',
label='Weekday 5', color='purple')
plt.title('Daily Bike Rentals') # 设置标题
plt.xlabel('Weekday') # 设置x轴标签
plt.ylabel('Rentals') # 设置y轴标签
plt.legend() # 添加图例显示每条线对应的星期
plt.show()
import pandas as pd
import numpy as np
# 读取CSV文件
df = pd.read_csv('gongxiang.csv')
# 查看数据的前5行
print(df.head())
# 检查缺失值
print("Number of missing values in each column:")
print(df.isnull().sum())
# 我们将缺失值填充为该列的平均值
df.fillna(df.mean(), inplace=True)
# 计算两列的平均值。
average = df[['casual', 'registered']].mean(axis=1)
# 输出平均值
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取 CSV 文件
df = pd.read_csv('gongxiang.csv')
df['instant'] = pd.to_datetime(df['instant'])
df = df.set_index("instant")
# 提取时间信息
df['hour'] = df.index.hour
df['week'] = df.index.weekday
df['month'] = df.index.month
df['year'] = df.index.year
# 创建季节标签列
df['season_label'] = df['season'].map({1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'})
# 创建天气状况标签列
df['weathersit_label'] = df['weathersit'].map({1: 'Sunny', 2: 'Cloudy', 3: 'Rainly', 4: 'bad-day'})
# 绘制盒图
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(12, 10)
sns.boxplot(data=df, y="cnt", orient="v", ax=axes[0][0])
sns.boxplot(data=df, y="cnt", x="season", orient="v", ax=axes[0][1])
sns.boxplot(data=df, y="cnt", x="hour", orient="v", ax=axes[1][0])
sns.boxplot(data=df, y="cnt", x="workingday", orient="v", ax=axes[1][1])
axes[0][0].set(ylabel="Cnt", title=" Cnt")
axes[0][1].set(xlabel='Season', ylabel='Cnt', title=" Season")
axes[1][0].set(xlabel='Hour Of The Day', ylabel='Cnt', title=" Hour Of The Day")
axes[1][1].set(xlabel='Working Day', ylabel='Cnt', title=" Working Day")
plt.show()
# 导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
# 读取 CSV 文件到 DataFrame 对象中
df = pd.read_csv('gongxiang.csv')
df['instant'] = pd.to_datetime(df['instant'])
df['season'] = df['instant'].dt.quarter
# 根据 'season' 和小时数对数据进行分组,计算季节每小时的 'cnt' 列的平均值,并将结果展平为一个 DataFrame
seasonal_hourly_data = df.groupby(['season', df['instant'].dt.hour])['cnt'].mean().unstack()
plt.figure(figsize=(12, 6))
# 将展平后的 DataFrame 进行转置,并绘制图形,使用 'o' 作为标记
seasonal_hourly_data.T.plot(marker='o')
plt.xlabel('Hour ')
plt.ylabel('Average Cnt')
plt.title('Seasons')
plt.legend(title='Season', labels=['summer',], bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
五、大数据分析总结
通过上面的分析结论得出天气和温度对共享单车的使用有显著影响。在晴朗、温度适宜的天气下,共享单车的使用量明显增加。工作日和节假日对共享单车的使用也有影响。在工作日,尤其是工作日且非休息日的时候,共享单车的使用量较大。
这一次对共享单车数据集的深度分析和挖掘,也认识到共享单车的数据分析还有很多潜力可挖,例如可以进一步研究用户的行为习惯、偏好等,以更好地满足用户的需求。未来期望通过更加先进的数据分析和挖掘技术,为共享单车的运营和管理提供更加精准和有效的支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号