
【项目复现上新】突破推理瓶颈!LightLLM轻量化部署新范式,打造高性能法律智能体
当前大语言模型(LLM)虽能力突飞猛进,却难逃“知识静态滞后”与“专业内容幻觉”两大痛点。在法律、医疗等强合规场景中,这几乎是“致命缺陷。而RAG(检索增强生成)框架虽能通过融合外部知识库破解此困,却在落地时遭遇新瓶颈:有限硬件资源下,如何实现高效、低延迟推理?
在此背景下,以LightLLM为代表的高效推理框架展现出关键价值:其聚焦于轻量化部署与推理优化,通过高效内存管理与算子融合技术,显著提升模型运行速度,并具备良好的扩展性以支持多种模型规模与量化策略。
掌握LightLLM不仅有助于深入理解RAG中检索与生成的协同机制,更可培养在资源受限环境下优化、部署AI系统的核心能力,为教学实验、中小企业及个人开发者提供稳定、高效的底层支持,具有重要的实践必要性与应用前景。
今天,我们就以大模型实验室Lab4AI为载体,揭秘如何用LightLLM+LlamaIndex快速搭建 “实时检索+精准推理” 的 法律智能体,让AI在专业场景真正“能用且好用”。
为何选择LightLLM?
作为纯Python开发的大语言模型推理与服务框架,LightLLM堪称“集百家之长”——整合了FasterTransformer、vLLM、FlashAttention等开源方案的优势,却以“轻量、易扩、高性能”站稳脚跟,成为开发者眼中的“高效推理利器”。
其核心特性,每一个都精准戳中部署痛点:
- 多进程协同: 输入文本编码、语言模型推理、视觉模型推理、输出解码等工作异步进行,大幅提高GPU利用率。
- 跨进程请求对象共享: 通过共享内存,实现跨进程请求对象共享,降低进程间通信延迟。
- 高效的调度策略: 带预测的峰值显存调度策略,最大化GPU显存利用率的同时,降低请求逐出。
- 高性能的推理后端: 高效的算子实现,多种并行方式支持(张量并行,数据并行以及专家并行),动态kv缓存,丰富的量化支持(int8,fp8,int4),结构化输出以及多结果预测。
零配置速玩!LightLLM的3步实战
GitHub仓库提供了LightLLM项目的源代码,并且给出了项目所需的所有Python依赖包。除此之外,Conda环境中还需要安装LlamaIndex库用于构建基于私有数据的检索增强生成(RAG)应用,安装Streamlit库用于快速创建交互式数据可视化网页应用,安装LightLLM运行所需的计算机视觉处理库和WebSocket通信支持依赖包,安装LlamaIndex框架对HuggingFace本地嵌入模型的支持包。
乍一听,有这么多前期工作需要准备。您别慌,大模型实验室Lab4AI已为你备好全套依赖,直接“拎包上车”体验LightLLM的强悍!
这也是大模型实验室Lab4AI的优势和特色:通过低门槛实践场景+算力无缝衔接,形成“算力+实验平台+社区”的深度融合模式,帮助您节省80%环境配置时间,让您专注于创新。
今天,我们将基于大模型实验室Lab4AI,构建LightLLM+LlamaIndex法律的智能体。
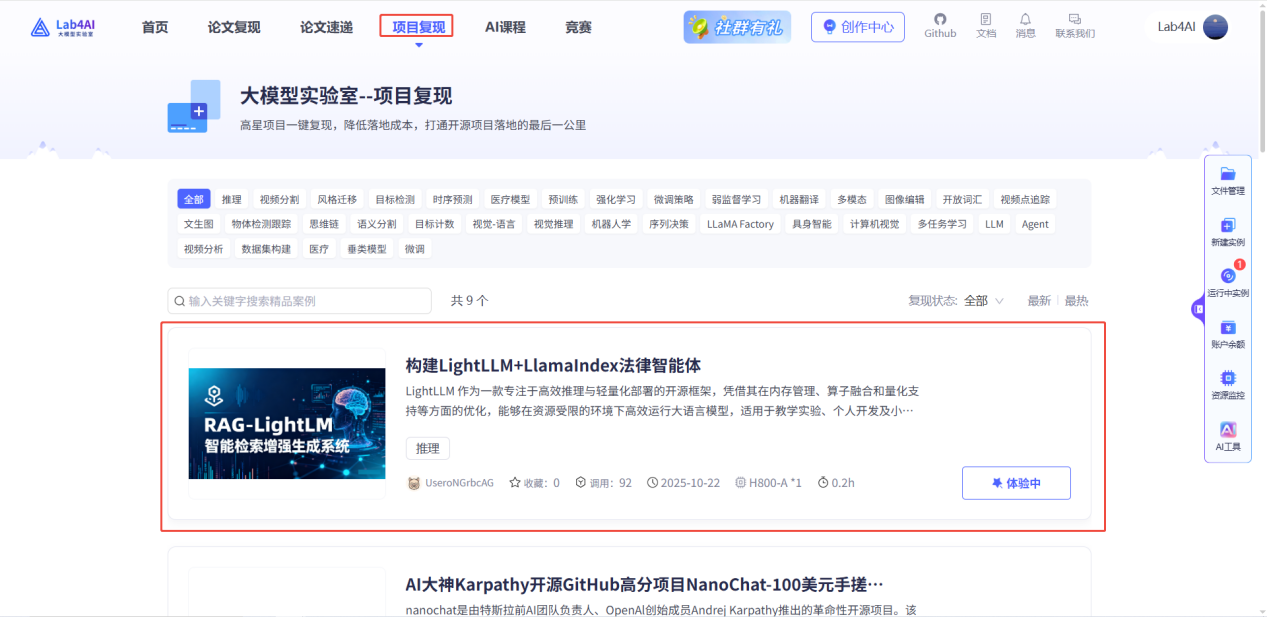
登录Lab4AI.cn。
在“项目复现”中找到“构建LightLLM+LlamaIndex法律智能体”。
Step1:部署LLM服务
基于现有的lightllm环境创建一个完全相同的副本环境lightllm-exp,并执行部署命令:
%%script bash
mkdir-p./output_dirs/logs
LOG_FILE="./output_dirs/logs/lightllm_$(date+'%Y%m%d_%H%M%S').log"
nohup python -m lightllm.server.api_server --enable_fa3 --model_dir /workspace/codelab/基于LightLLM结合LlamaIndex构建法律智能体/model/Qwen3-8B > "$LOG_FILE" 2>&1 &
部署是否正常,服务正常启动页面例如下图所示。
curl-XPOST"http://localhost:8000/v1/chat/completions"\
-H"Content-Type:application/json"\
-d'{
"model":"Qwen3-8B",
"messages":[{"role":"user","content":"Hello"}],
"max_tokens":1000
}'

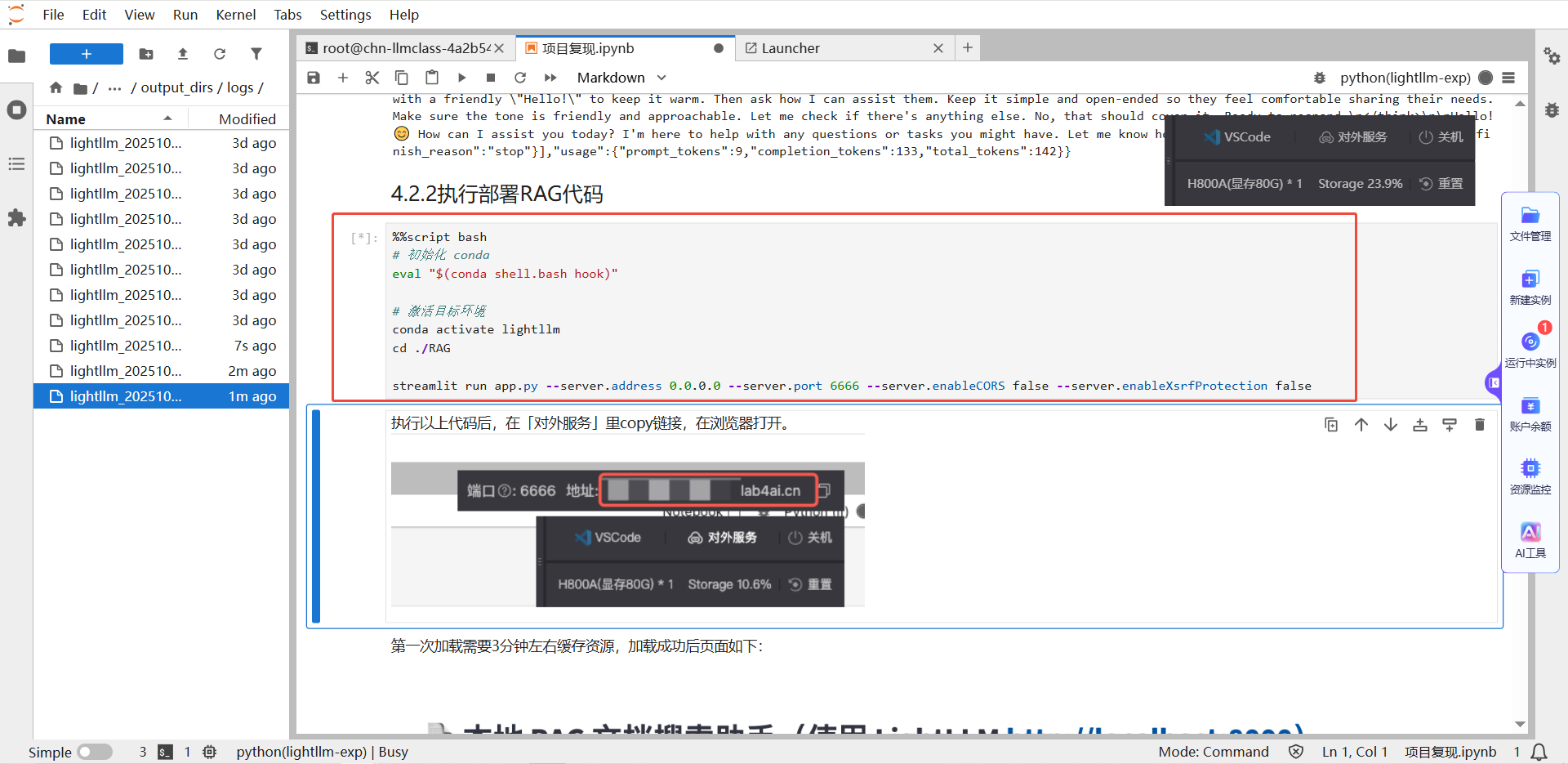
Step2:部署RAG
点击链接下载app.py,下载后将文件拖拽至/workspace/lightllm目录下,然后运行如下所示命令加载RAG服务,加载成功后页面例如下图所示。
streamlitrunapp.py\
--server.address0.0.0.0\
--server.port6666\
--server.enableCORSfalse\
--server.enableXsrfProtectionfalse
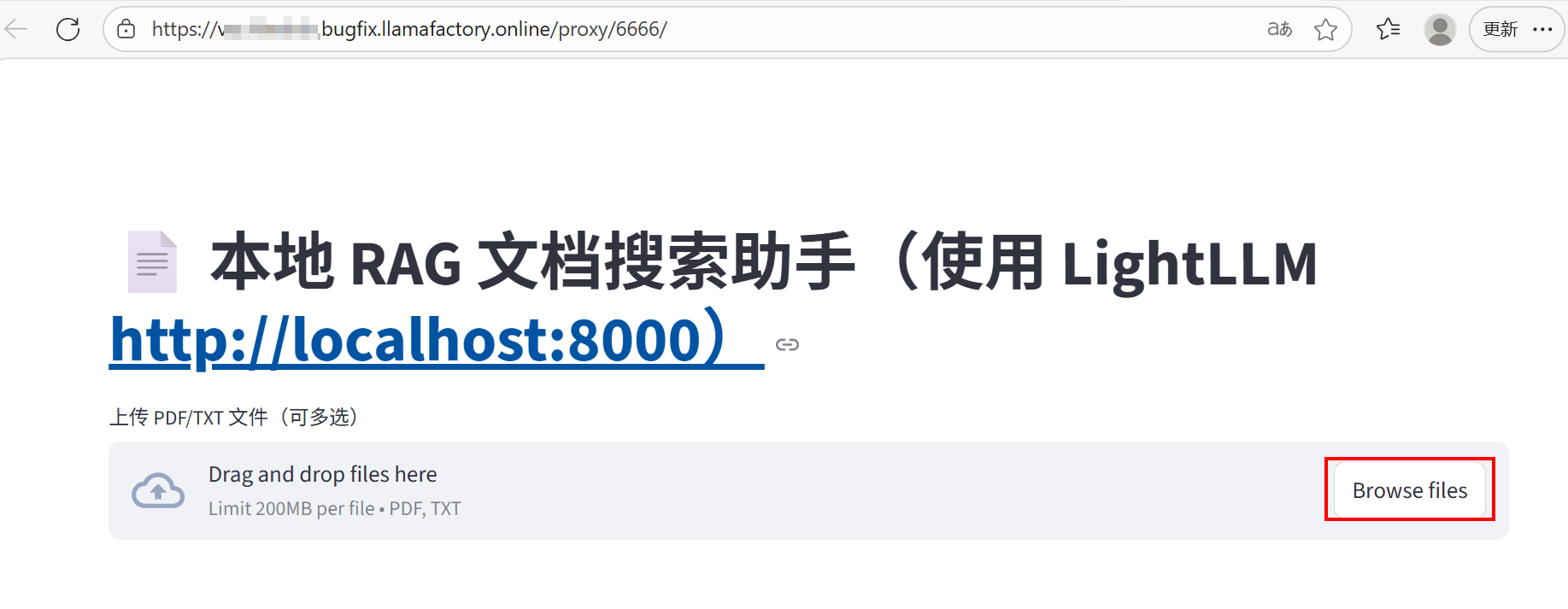
执行以上代码后,在「对外服务」里copy链接,在浏览器打开。点击服务链接,进入本地RAG文档搜索助手页面,例如下图所示。
Step3:应用体验
服务部署完成后,用户可自定义构建知识库,并基于库内信息查询相关问题,快速获取解决方案。
下方是我们上传本地知识库文件后,并输入问题:“我有考勤记录截图和与领导沟通加班的微信记录。劳动合同写的是月薪8000元,但公司一直按基本工资3000元为基数算加班费。我主张最近一年的”。下方是问答效果:

不只是Demo:从验证到落地的全流程支撑
本方案验证了“轻量化RAG技术”在实际业务环境中的可行性。通过构建外部文档库、数据库或知识管理系统,让模型在生成答案前先检索最新且权威的资料,将检索到的内容作为上下文输入模型。借助LightLLM的高效推理与扩展能力,我们可在单机环境下支撑起专业级法律智能服务,显著缓解模型“知识滞后”与幻觉问题。这一架构具备高可复用的特点,不仅能用于法律场景,还可快速迁移至金融、医疗、政务等强知识依赖的领域,形成稳定、可解释、可扩展的行业解决方案。
作为算力驱动的AI实践内容生态社区,它不是普通的代码仓库,而是集代码、数据、算力与实验平台于一体的平台,项目中预装虚拟环境,让您彻底告别“环境配置一整天,训练报错两小时”的窘境。
除了提供LightLLM法律智能体的一键复现服务,Lab4AI更构建了“算力+实验平台+社区”的全链条支撑体系,为不同用户群体提供定制化价值:
1.科研党:从“看论文”到“发论文”的全流程支持
每日同步Arxiv前沿论文,提供翻译、导读、分析服务,助力快速追踪行业动态;支持包括LightLLM在内的各类大模型一键复现,更可直接基于平台进行数据集微调,兼容LLaMA-FactoryWebUI微调功能;同时对接投资孵化资源,助力科研创意转化为实际产品。
2.学习者:AI课程支撑您边练边学
提供多样化AI在线课程,含LLaMAFactory官方合作课程等课程,聚焦大模型定制化核心技术,实现理论学习与代码实操同步推进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号