B站视频刷播放量-练习版
视频地址: https://www.bilibili.com/video/BV1WR4y1F7gH
第一步:找到哪个请求会涨播放。
怎么找?打开视频按下F12后,清除网络连接请求,再点击播放后,会发送很多请求,分析这些请求,哪些像是在涨播放。
看下面的这三个请求可能就是我们需要的请求:
请求一 now:
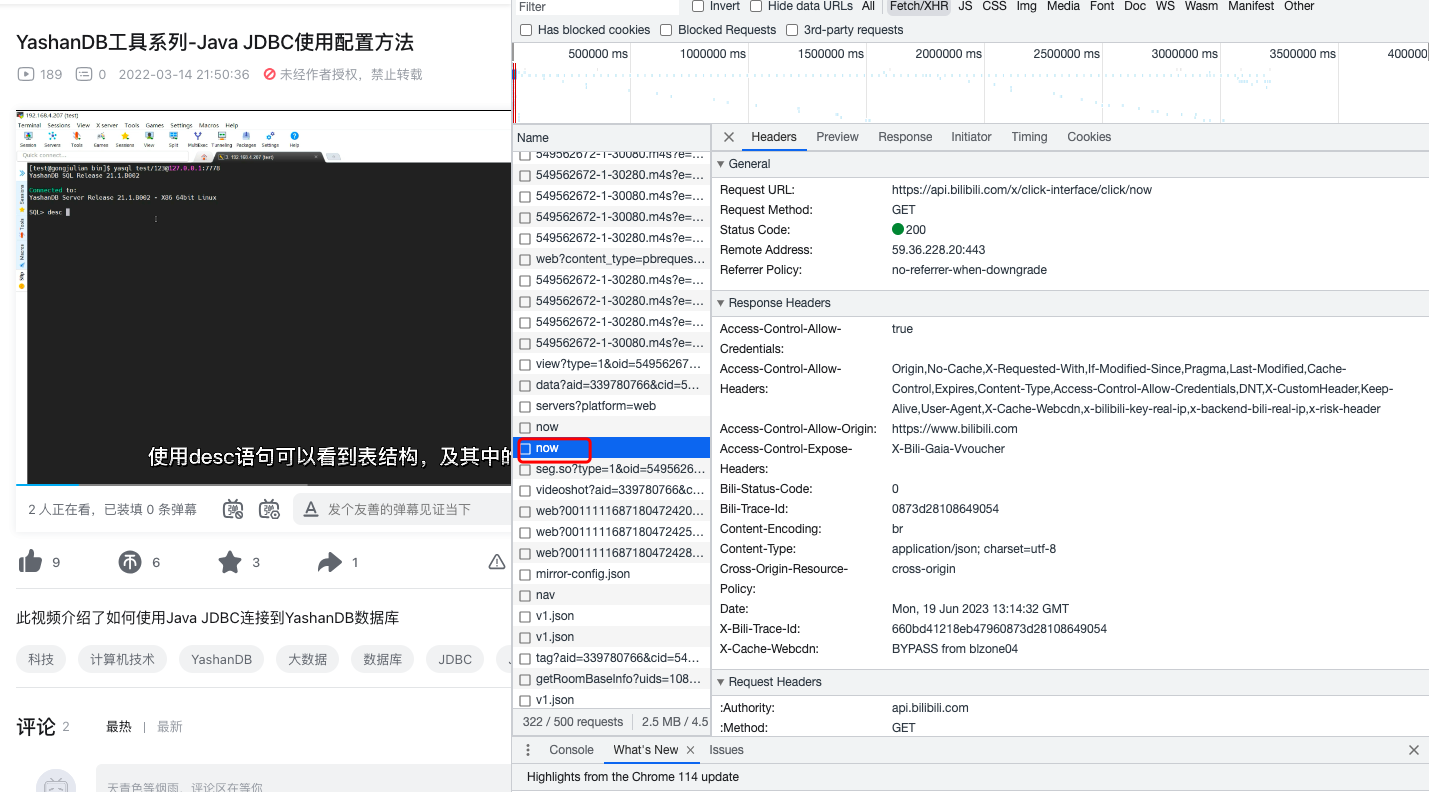
请求二 heartbeat:
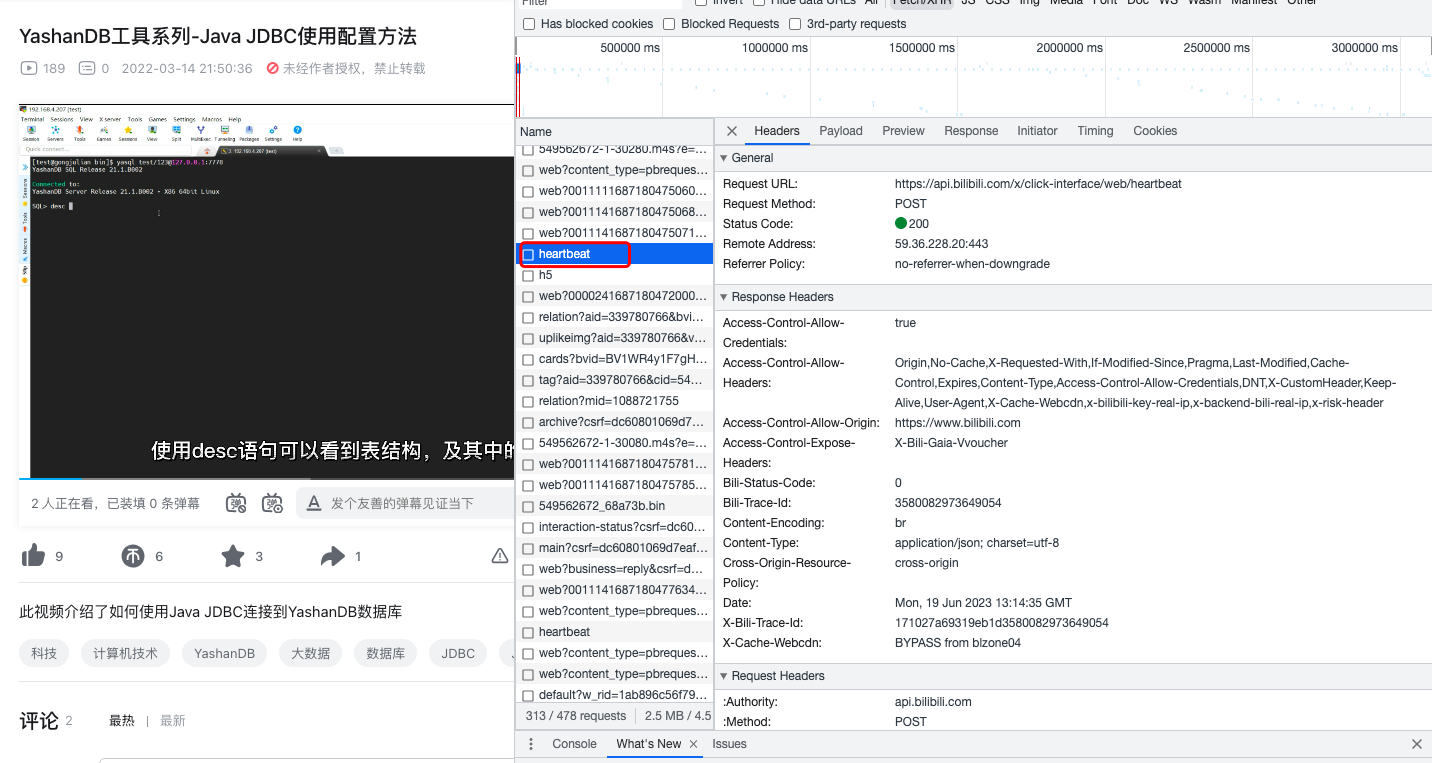
请求三 h5:
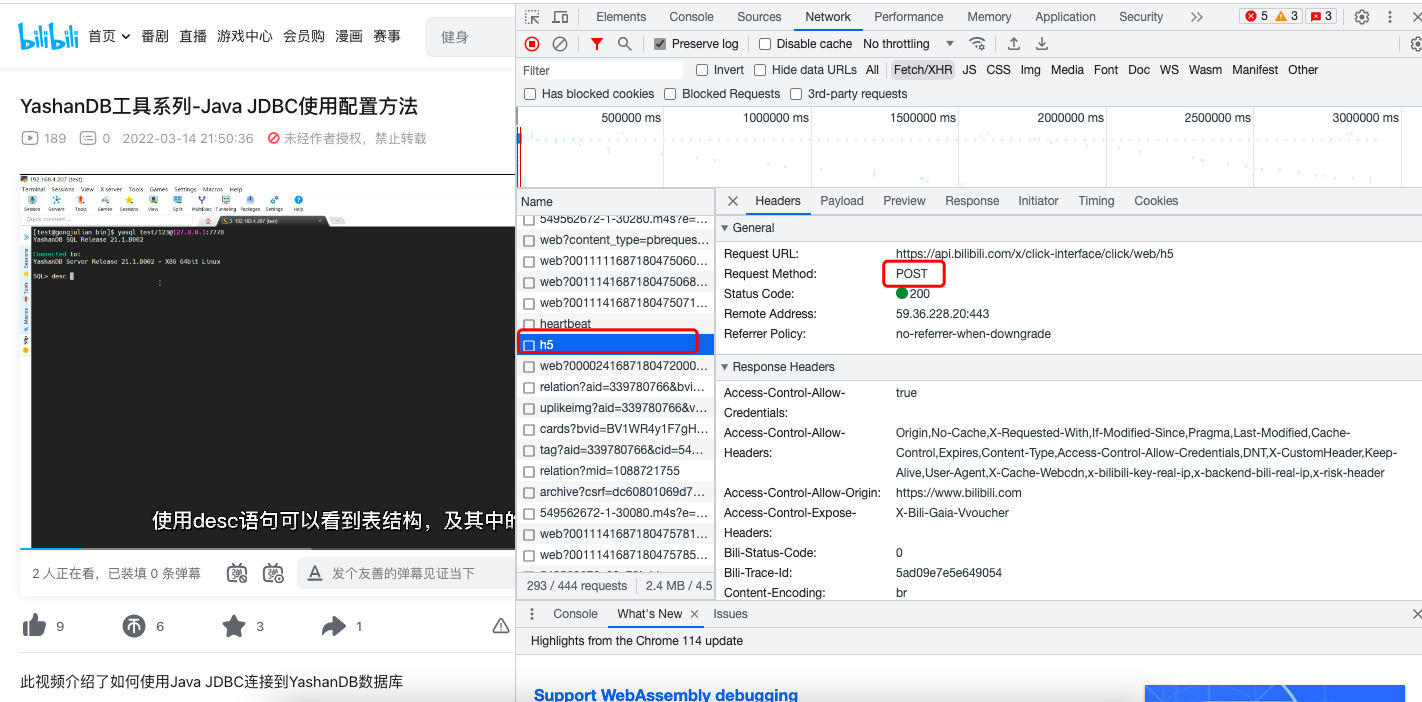
然后通过代码模拟,模拟之后发现播放是涨的。
最后发现 h5的请求是会涨播放量的,链接: https://api.bilibili.com/x/click-interface/click/web/h5
扩展知识:
(1)h5,涨播放量。 ==> 这是我们要解决的。
(2)heartbeat,涨播放量 + 播放时长(每15s发送一次请求) ==> 这不是我们要解决的。然后再做减法:去除掉依然是涨的,说明不是核心的,再去掉,再去掉,最后发现最终指定的N个,最后我们只需要搞那N个就可以了。
第二步:分析URL https://www.bilibili.com/video/BV1WR4y1F7gH
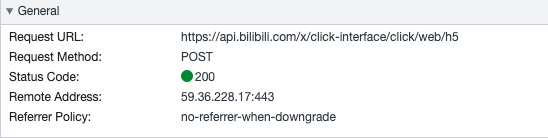
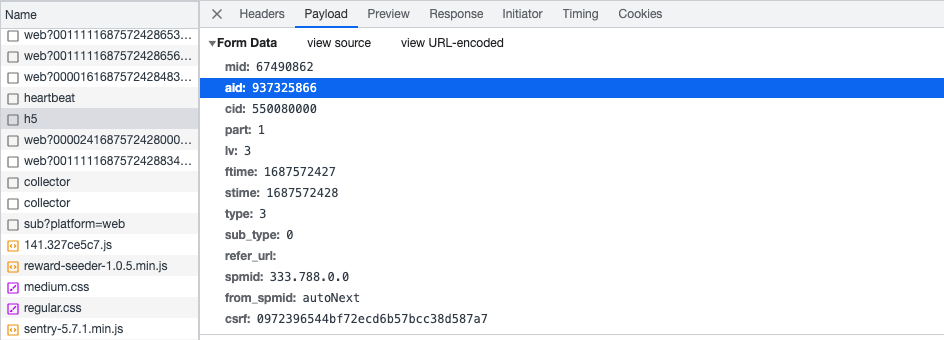
- 地址:https://api.bilibili.com/x/click-interface/click/web/h5
- URL参数:无
- 请求头:无
对于请求体:
- aid:
- cid:
上面这两个值aid和cid猜想:
(下面引出爬虫和逆向的一个重要思想:很多时候都是要靠不断的猜想和验证,不断的寻找;如果寻找到了,验证到是他了,那么就是他;如果验证失败,那就继续找,继续验证)
猜想一:之前请求返回COOKIE,这些请求携带。(之前请求模拟)
猜想二:响应体中返回
JSON
HTML
猜想三:其他请求响应头
猜想四:内部通过js代码生成
猜想五:直接百度搜索“bilibili aid cid”,别人已经做过了
拿着aid 的值去在下面的搜索框搜索
需要看的是h5 请求之前的,并且是那种返回回来的数据,而不是发送请求的时候携带的数据。所以需要一个一个的找。
比如下面的就不是,下面的是在请求URL中携带的。
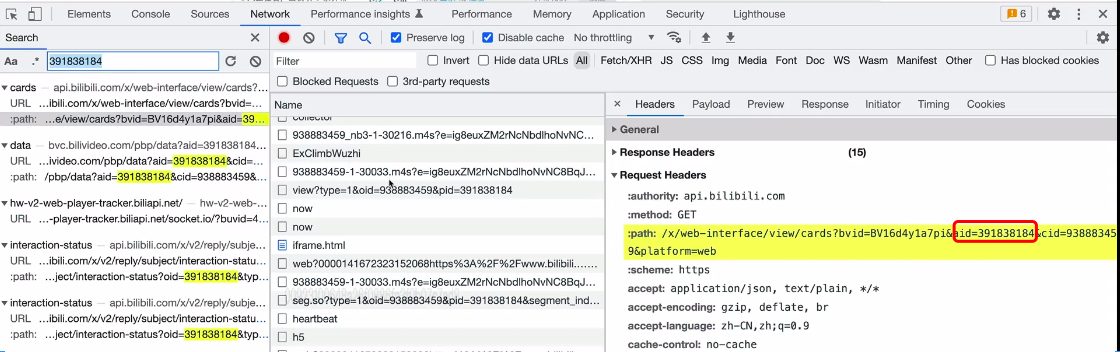
下面的aid才是我们需要的,aid的值嵌套到页面返回了。
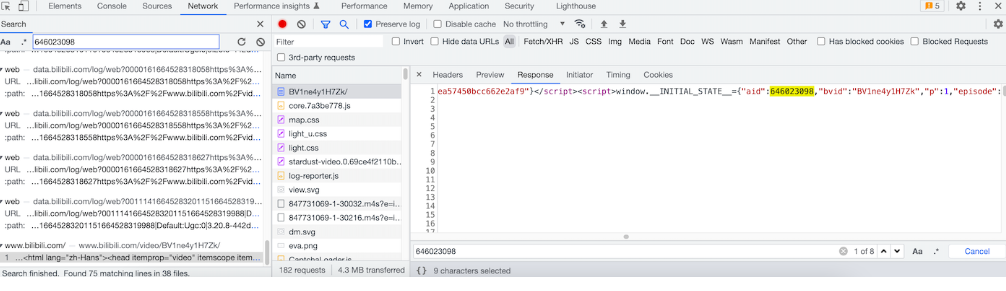
同时也通过上面发现了cid的值也可以获取到。
所以aid和cid的值可以通过下面的代码获取到:
import requests
import json
import re
res = requests.get("https://www.bilibili.com/video/BV1ne4y1H7Zk")
# ["",]
data_list = re.findall(r'__INITIAL_STATE__=(.+);\(function', res.text)
data_dict = json.loads(data_list[0])
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
print(aid)
print(cid)对于Cookie:
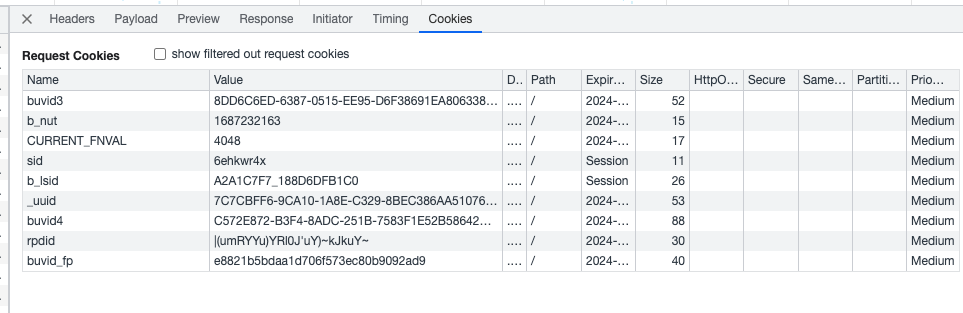
怎么知道上面哪些参数是不是必须的:去除掉播放量依然是涨的,其他不带也能涨,那就不带,说明不是核心的,可以再去掉。
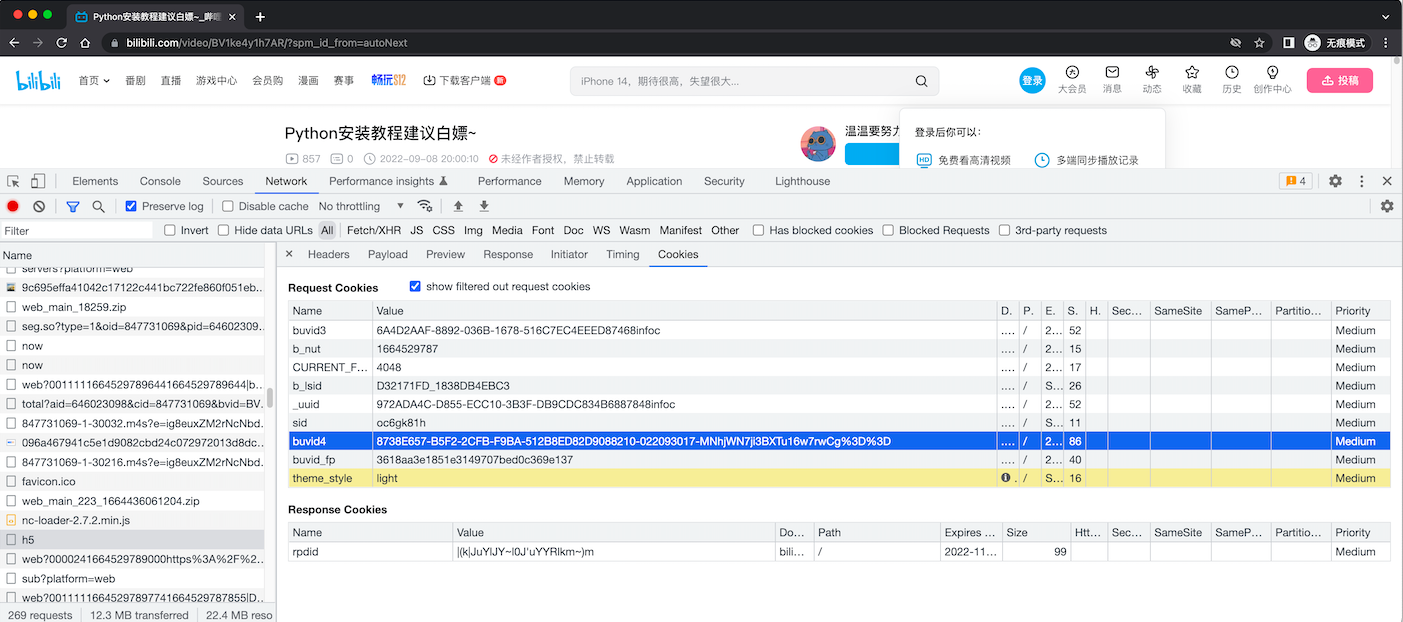
- buvid3
- CURRENT_FNVAL
- b_lsid
- _uuid
- sid
- buvid4
cookie的来源:
-
固定值
-
其他请求返回
-
cookie
-
body
-
header
-
-
js算法生成
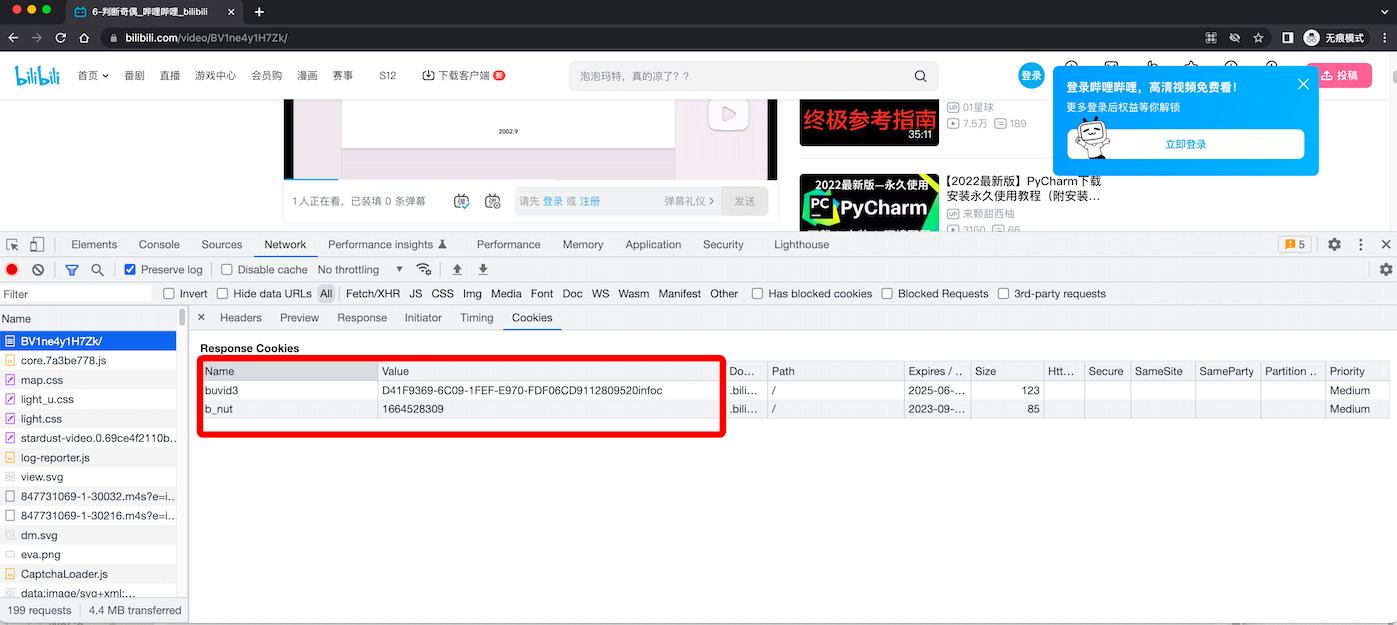
import requests
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
})
video_url = "https://www.bilibili.com/video/BV1ne4y1H7Zk/"
res = session.get(video_url)
print(res.cookies.get_dict())
# {'b_nut': '1664528708', 'buvid3': 'E4C54B76-FFC4-CF38-190E-0A9A184C02C908456infoc'}
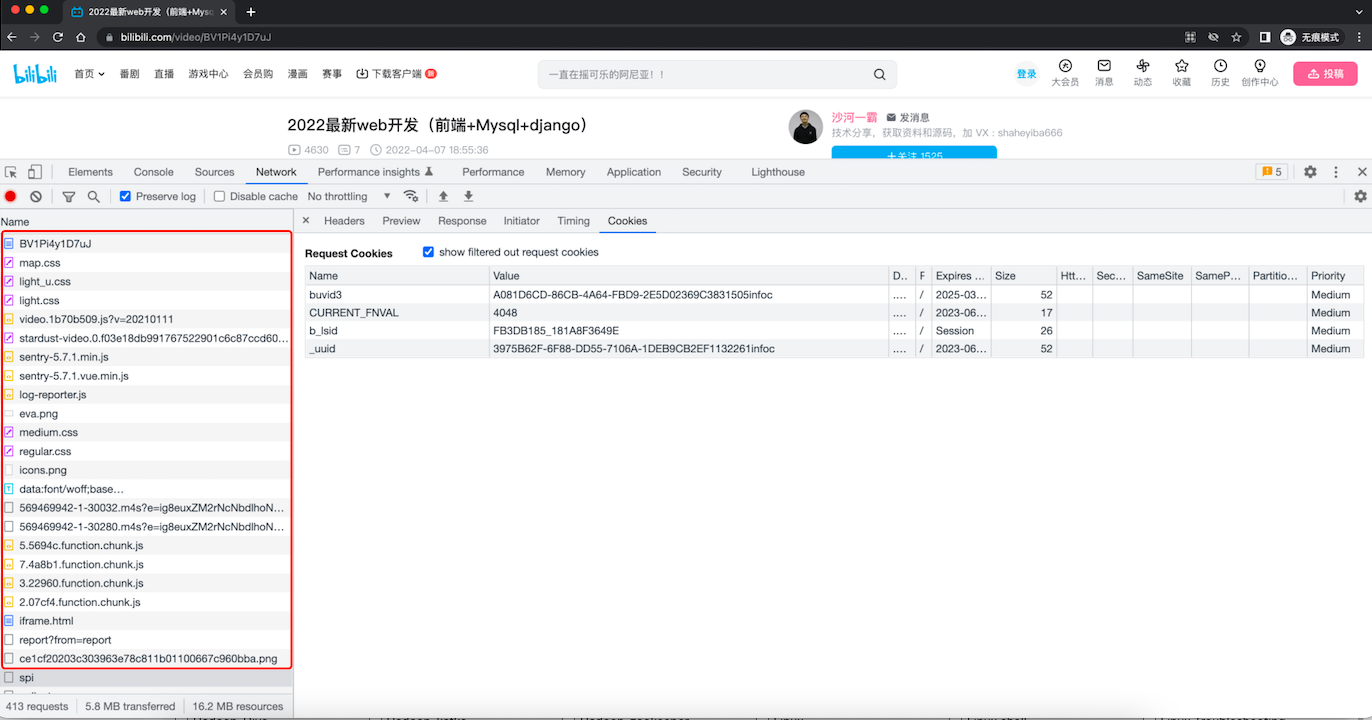
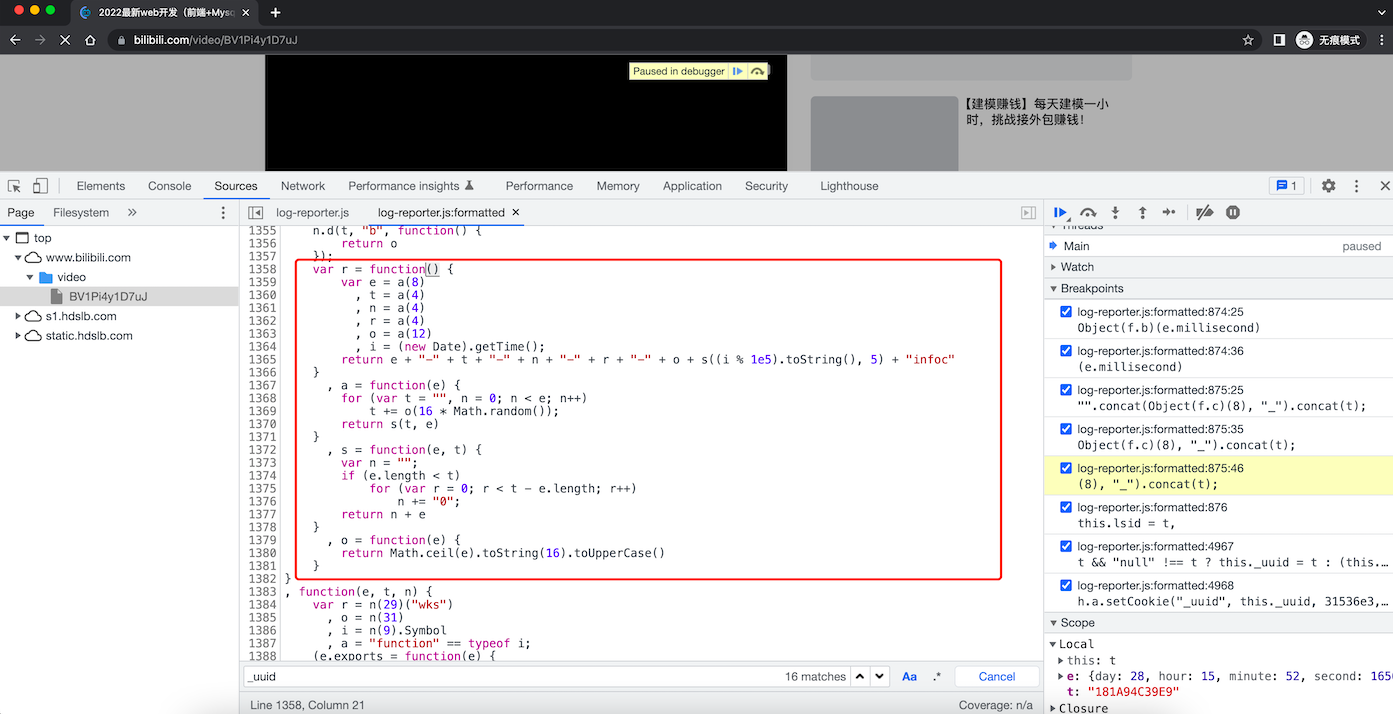
在spi请求之前,未发现有返回 b_lsid和_uuid的位置,那么就可能是js算法生成。
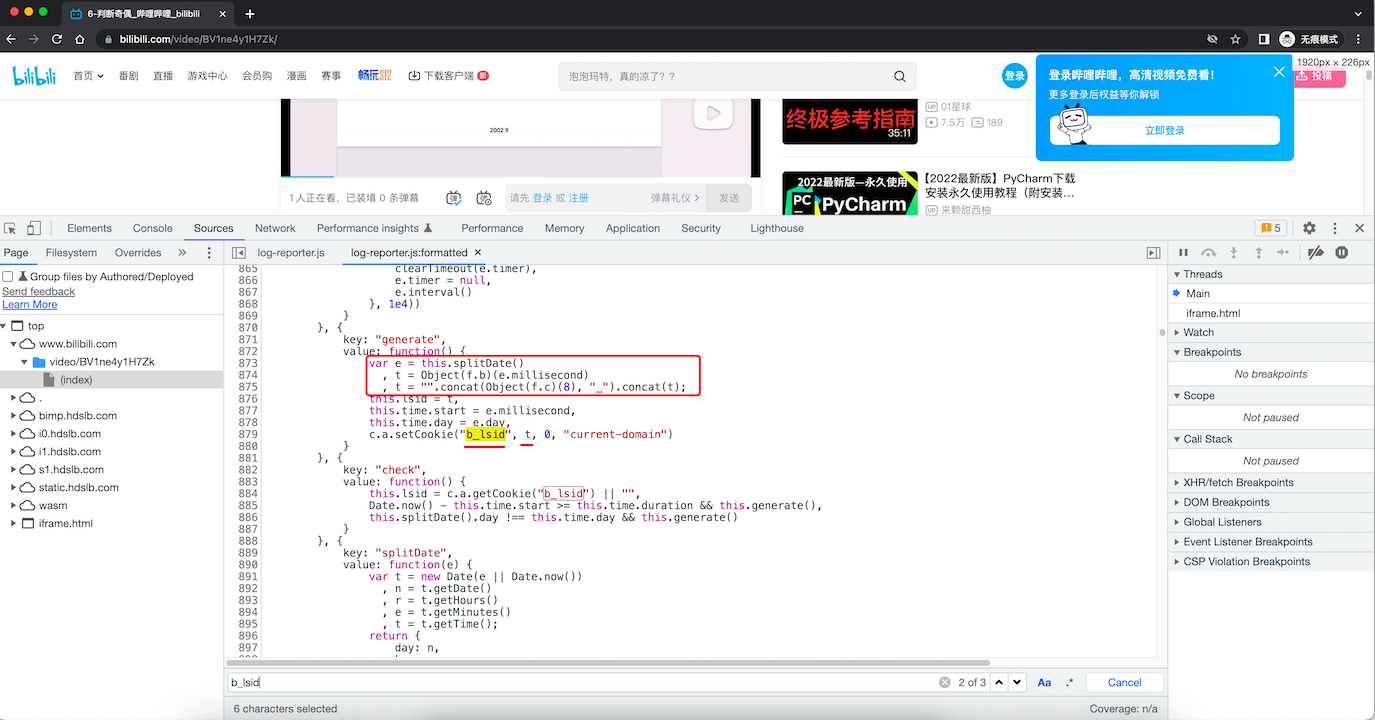
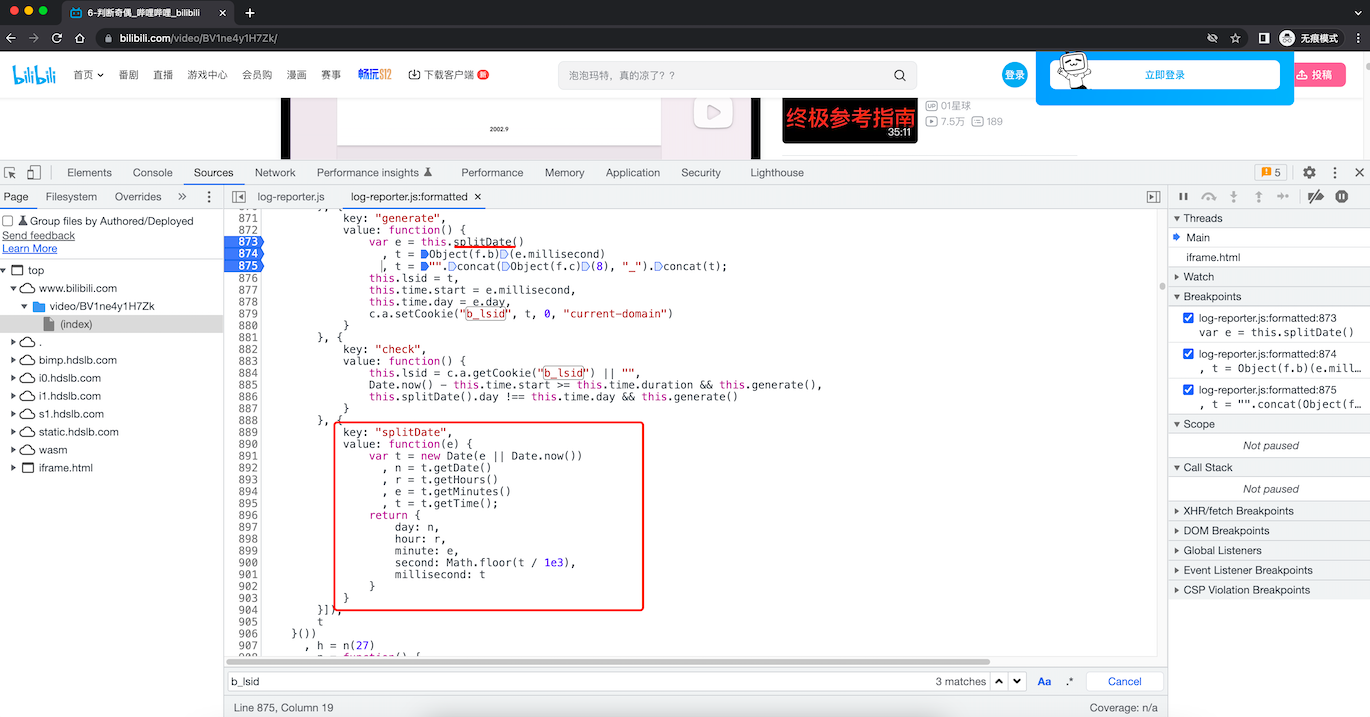
var e = this.splitDate();
t = Object(f.b)(e.millisecond)
t = "".concat(Object(f.c)(8), "_").concat(t);
清除cookie,断点调试:
e = new Date(Date.now()).getTime()import time
e = int(time.time()*1000)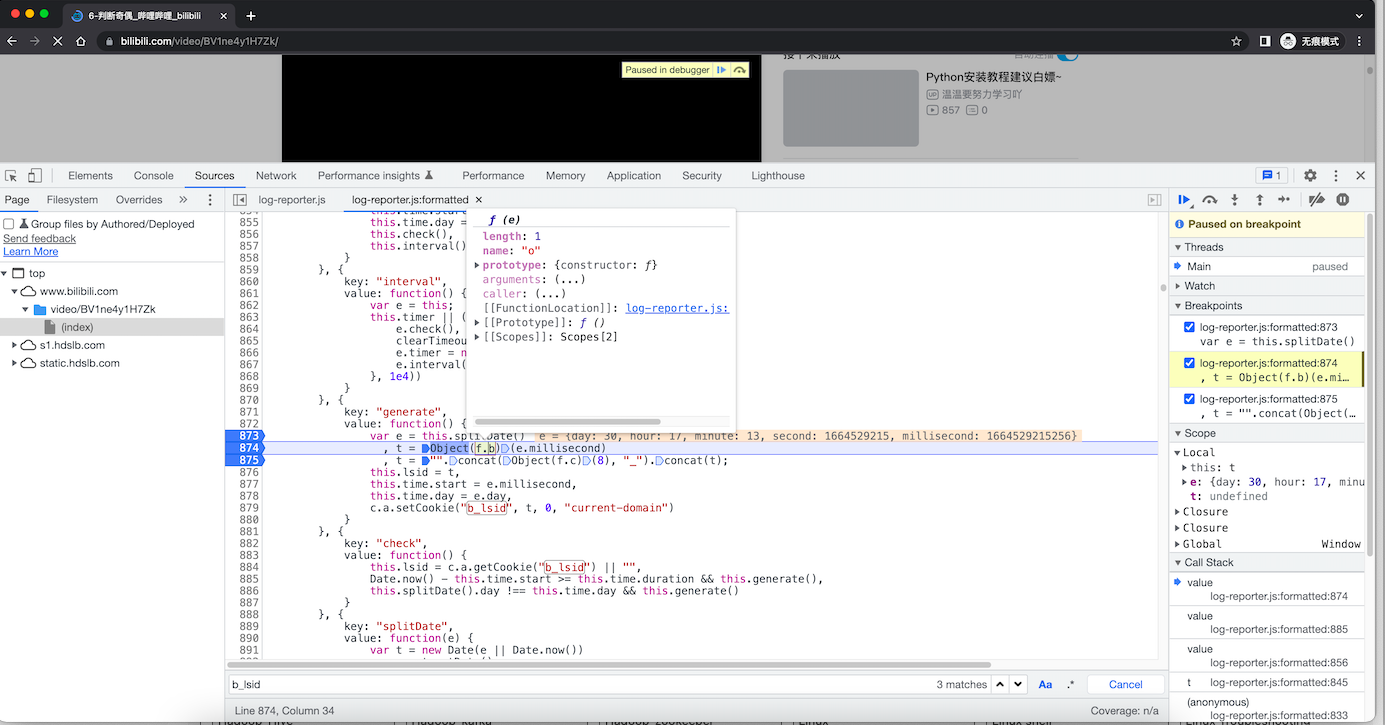
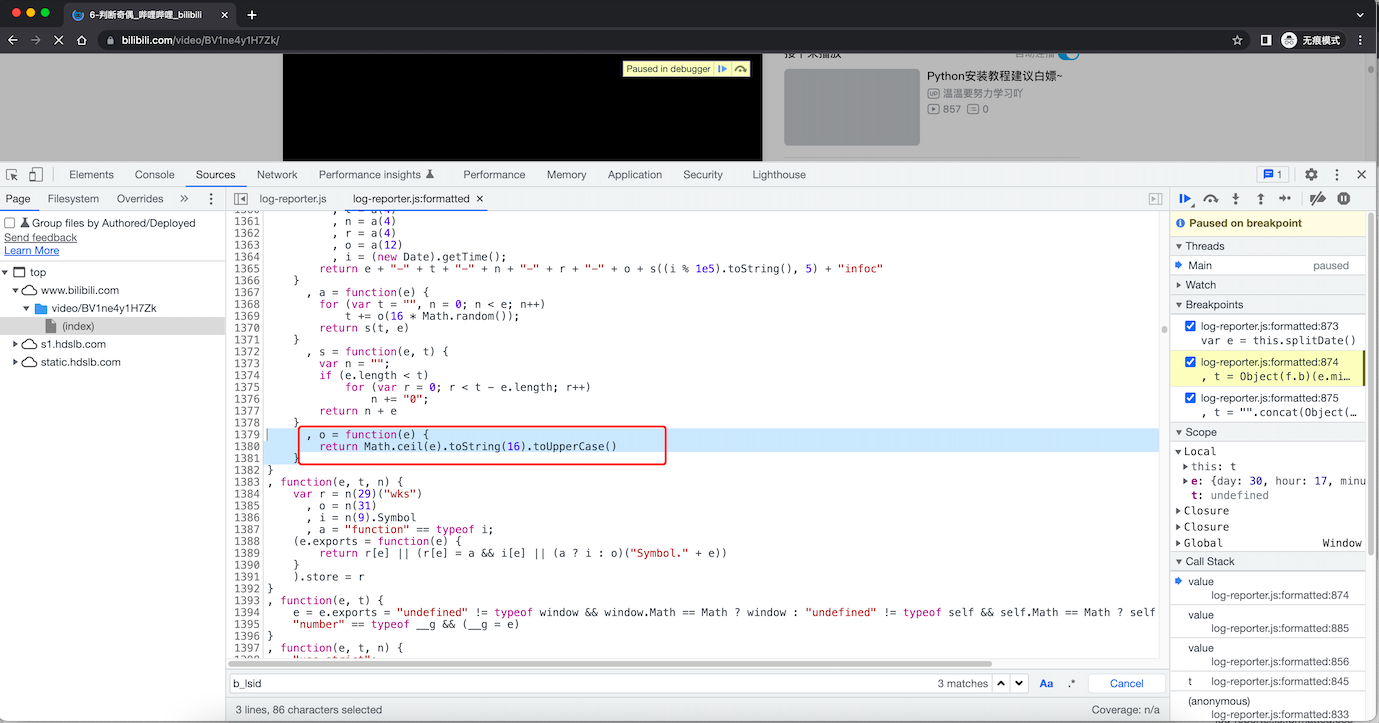
Math.ceil 方法用于对数值向上取整,即得到大于或等于该数值的最小整数import time
e = int(time.time()*1000)
t = hex(e)[2:].upper()
print(t)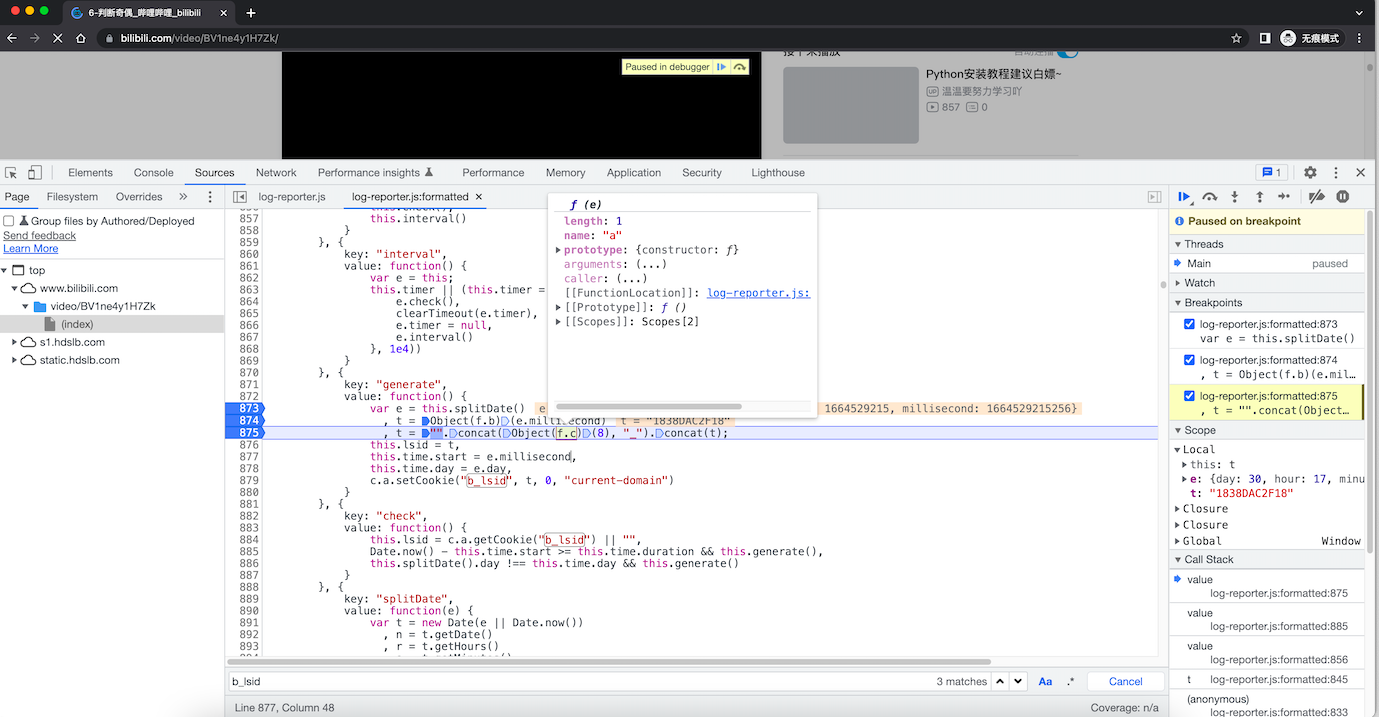
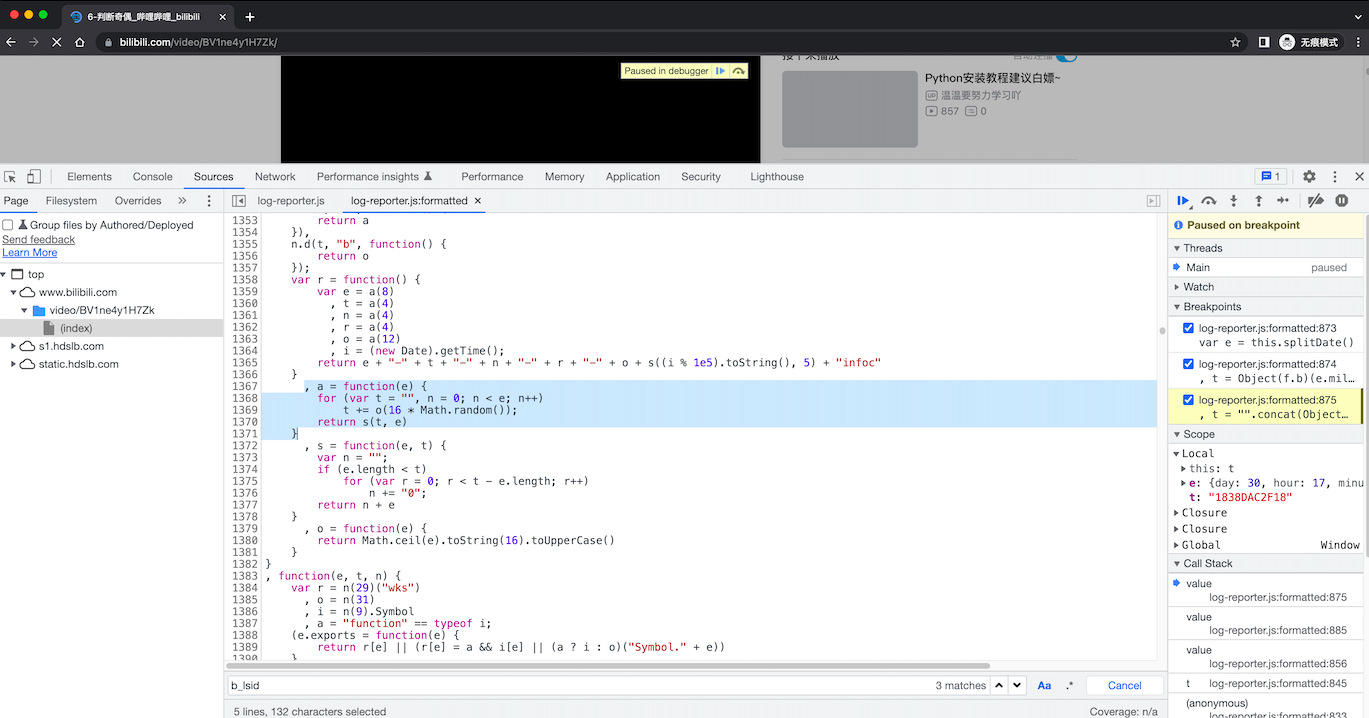
e = 8
, a = function(e) {
for (var t = "", n = 0; n < e; n++)
t += o(16 * Math.random()); // 生成 16*随机小数 -> 十六进制
// t
return s(t, e)
}
// 长度小于8,则在前面补0
, s = function(e, t) {
var n = "";
if (e.length < t)
for (var r = 0; r < t - e.length; r++)
n += "0";
return n + e
}
, o = function(e) {
return Math.ceil(e).toString(16).toUpperCase()
}import math
import random
data = ""
for i in range(8):
v1 = math.ceil(16 * random.uniform(0, 1))
v2 = hex(v1)[2:].upper()
data += v2
result = data.rjust(8, "0")
print(result)
import time
import math
import random
data = ""
for i in range(8):
v1 = math.ceil(16 * random.uniform(0, 1))
v2 = hex(v1)[2:].upper()
data += v2
result = data.rjust(8, "0")
e = int(time.time()*1000)
t = hex(e)[2:].upper()
b_lsid = "{}_{}".format(result,t)
print(b_lsid)
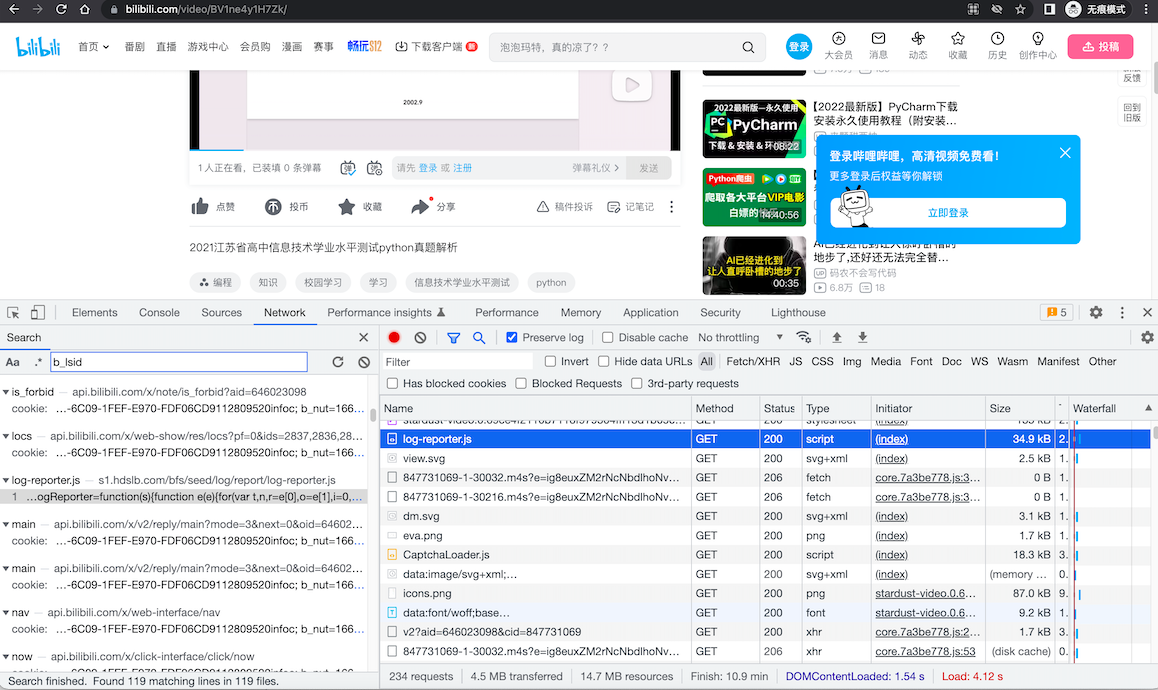
再在当前页面继续搜索 _uuid
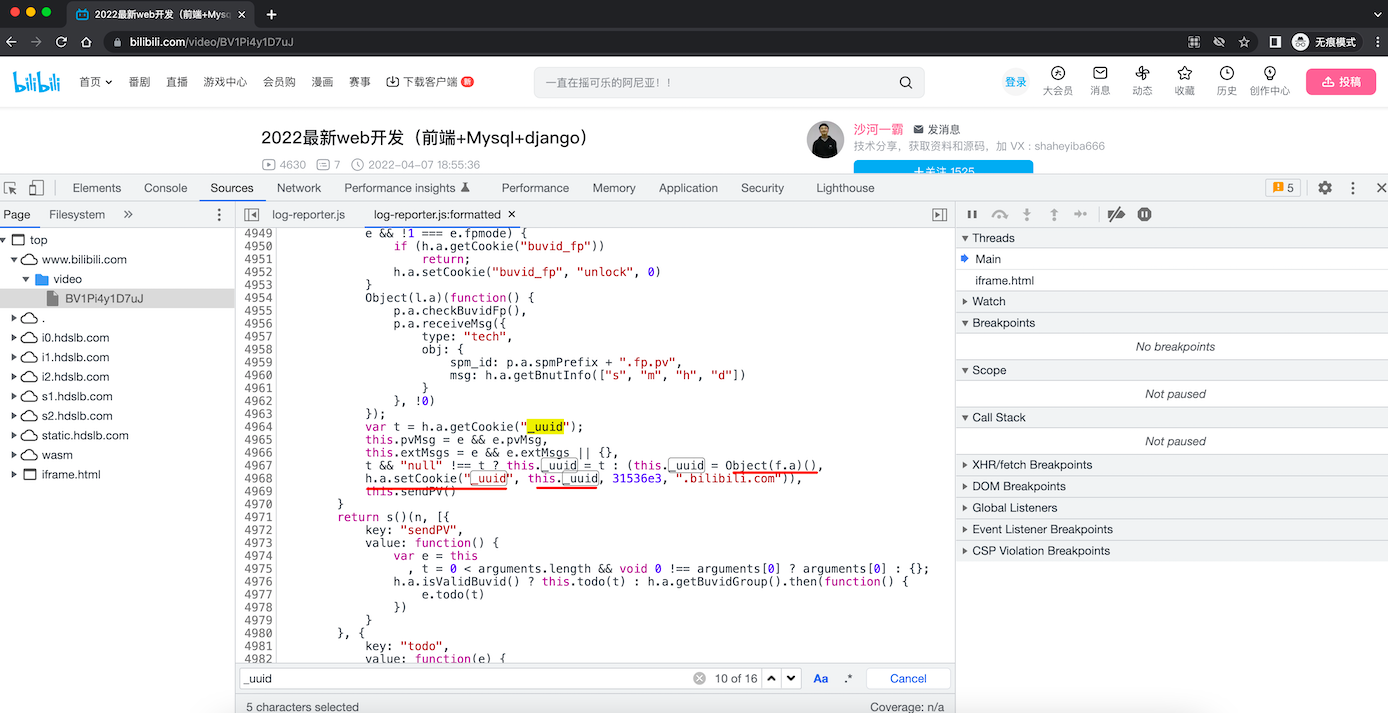
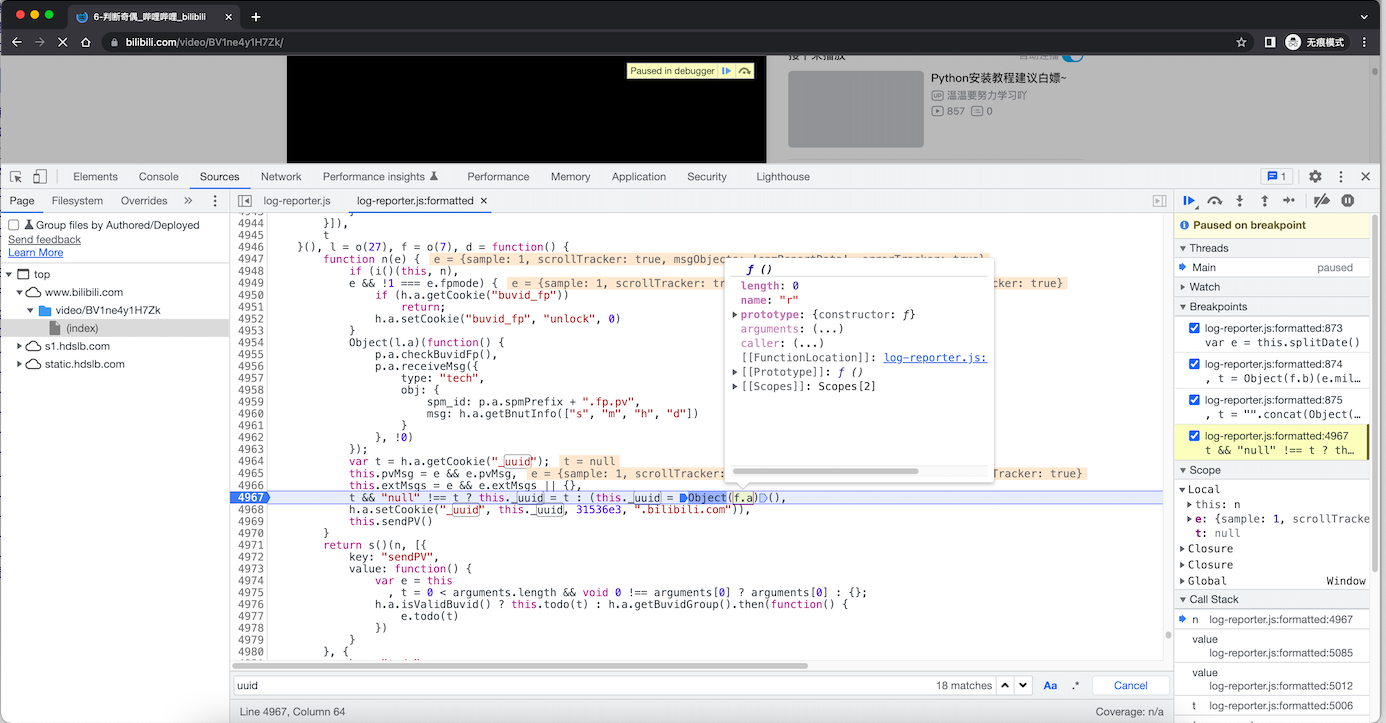
import time
import uuid
def gen_uuid():
uuid_sec = str(uuid.uuid4())
time_sec = str(int(time.time() * 1000 % 1e5))
time_sec = time_sec.rjust(5, "0")
return "{}{}infoc".format(uuid_sec, time_sec)
_uuid = gen_uuid()
print(_uuid)
buvid4
import math
import random
import time
import uuid
import requests
import re
import json
def gen_uuid():
uuid_sec = str(uuid.uuid4())
time_sec = str(int(time.time() * 1000 % 1e5))
time_sec = time_sec.rjust(5, "0")
return "{}{}infoc".format(uuid_sec, time_sec)
def gen_b_lsid():
data = ""
for i in range(8):
v1 = math.ceil(16 * random.uniform(0, 1))
v2 = hex(v1)[2:].upper()
data += v2
result = data.rjust(8, "0")
e = int(time.time() * 1000)
t = hex(e)[2:].upper()
b_lsid = "{}_{}".format(result, t)
return b_lsid
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
})
video_url = "https://www.bilibili.com/video/BV1Pi4y1D7uJ"
res = session.get(video_url)
_uuid = gen_uuid()
session.cookies.set('_uuid', _uuid)
b_lsid = gen_b_lsid()
session.cookies.set('b_lsid', b_lsid)
session.cookies.set("CURRENT_FNVAL", "4048")
res = session.get("https://api.bilibili.com/x/frontend/finger/spi")
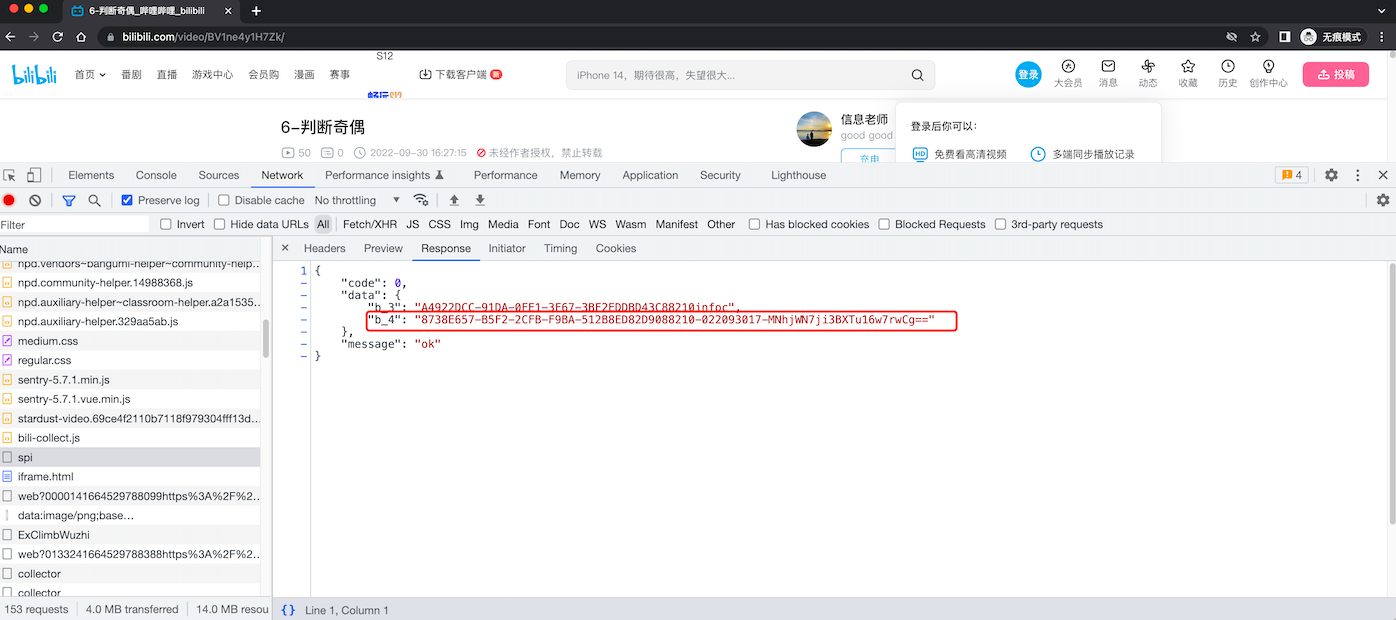
buvid4 = res.json()['data']['b_4']
print(buvid4)

import math
import random
import time
import uuid
import requests
import re
import json
def gen_uuid():
uuid_sec = str(uuid.uuid4())
time_sec = str(int(time.time() * 1000 % 1e5))
time_sec = time_sec.rjust(5, "0")
return "{}{}infoc".format(uuid_sec, time_sec)
def gen_b_lsid():
data = ""
for i in range(8):
v1 = math.ceil(16 * random.uniform(0, 1))
v2 = hex(v1)[2:].upper()
data += v2
result = data.rjust(8, "0")
e = int(time.time() * 1000)
t = hex(e)[2:].upper()
b_lsid = "{}_{}".format(result, t)
return b_lsid
video_url = "https://www.bilibili.com/video/BV1Pi4y1D7uJ"
bvid = video_url.rsplit("/")[-1]
session = requests.Session()
session.headers.update({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
})
res = session.get(video_url)
data_list = re.findall(r'__INITIAL_STATE__=(.+);\(function', res.text)
data_dict = json.loads(data_list[0])
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
_uuid = gen_uuid()
session.cookies.set('_uuid', _uuid)
b_lsid = gen_b_lsid()
session.cookies.set('b_lsid', b_lsid)
session.cookies.set("CURRENT_FNVAL", "4048")
res = session.get("https://api.bilibili.com/x/frontend/finger/spi")
buvid4 = res.json()['data']['b_4']
session.cookies.set("CURRENT_BLACKGAP", "0")
session.cookies.set("blackside_state", "0")
res = session.get(
url='https://api.bilibili.com/x/player/v2',
params={
"cid": cid,
"aid": aid,
"bvid": bvid,
}
)
print(res.cookies.get_dict())
实现刷播放
隧道代理
推荐:享95折
注册连接:https://www.qg.net/?sale=viltf
代码示例
import time
import math
import random
import time
import uuid
import requests
import re
import json
def get_tunnel_proxies():
proxy_host = "tunnel2.qg.net:17955"
proxy_username = "xxxxxxx"
proxy_pwd = "xxxxxxxxxxx"
return {
"http": "http://{}:{}@{}".format(proxy_username, proxy_pwd, proxy_host),
"https": "http://{}:{}@{}".format(proxy_username, proxy_pwd, proxy_host),
}
def gen_uuid():
uuid_sec = str(uuid.uuid4())
time_sec = str(int(time.time() * 1000 % 1e5))
time_sec = time_sec.rjust(5, "0")
return "{}{}infoc".format(uuid_sec, time_sec)
def gen_b_lsid():
data = ""
for i in range(8):
v1 = math.ceil(16 * random.uniform(0, 1))
v2 = hex(v1)[2:].upper()
data += v2
result = data.rjust(8, "0")
e = int(time.time() * 1000)
t = hex(e)[2:].upper()
b_lsid = "{}_{}".format(result, t)
return b_lsid
def play(video_url, proxies):
bvid = video_url.rsplit("/")[-1]
session = requests.Session()
session.proxies = proxies
session.headers.update({
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
})
res = session.get(video_url)
data_list = re.findall(r'__INITIAL_STATE__=(.+);\(function', res.text)
data_dict = json.loads(data_list[0])
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
_uuid = gen_uuid()
session.cookies.set('_uuid', _uuid)
b_lsid = gen_b_lsid()
session.cookies.set('b_lsid', b_lsid)
session.cookies.set("CURRENT_FNVAL", "4048")
res = session.get("https://api.bilibili.com/x/frontend/finger/spi")
buvid4 = res.json()['data']['b_4']
session.cookies.set("buvid4", buvid4)
session.cookies.set("CURRENT_BLACKGAP", "0")
session.cookies.set("blackside_state", "0")
res = session.get(
url='https://api.bilibili.com/x/player/v2',
params={
"cid": cid,
"aid": aid,
"bvid": bvid,
}
)
ctime = int(time.time())
res = session.post(
url="https://api.bilibili.com/x/click-interface/click/web/h5",
data={
"aid": aid,
"cid": cid,
"bvid": bvid,
"part": "1",
"mid": "0",
"lv": "0",
"ftime": ctime - random.randint(100, 500), # 浏览器首次打开时间
"stime": ctime,
"jsonp": "jsonp",
"type": "3",
"sub_type": "0",
"from_spmid": "",
"auto_continued_play": "0",
"refer_url": "",
"bsource": "",
"spmid": ""
}
)
# print(res.text)
def get_video_id_info(video_url, proxies):
session = requests.Session()
bvid = video_url.rsplit('/')[-1]
res = session.get(
url="https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp".format(bvid),
proxies=proxies
)
cid = res.json()['data'][0]['cid']
res = session.get(
url="https://api.bilibili.com/x/web-interface/view?cid={}&bvid={}".format(cid, bvid),
proxies=proxies
)
res_json = res.json()
aid = res_json['data']['aid']
view_count = res_json['data']['stat']['view']
duration = res_json['data']['duration']
print("\n视频 {},平台播放量为:{}".format(bvid, view_count))
session.close()
return aid, bvid, cid, duration, int(view_count)
def run():
proxies = get_tunnel_proxies()
video_url = "https://www.bilibili.com/video/BV1N94y1R7K5"
aid, bvid, cid, duration, view_count = get_video_id_info(video_url, proxies)
while True:
try:
get_video_id_info(video_url, proxies)
play(video_url, proxies)
view_count += 1
print("理论刷的播放量:", view_count)
except Exception as e:
pass
if __name__ == '__main__':
run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号