

验证码:图鉴、超级鹰
图鉴
官方地址: http://www.ttshitu.com/
通用图片识别接口:(详见: http://www.ttshitu.com/docs/python.html#pageTitle )
typeid
一、图片文字类型(默认 3 数英混合):
1 : 纯数字
1001:纯数字2
2 : 纯英文
1002:纯英文2
3 : 数英混合
1003:数英混合2
4 : 闪动GIF
7 : 无感学习(独家)
11 : 计算题
1005: 快速计算题
16 : 汉字
32 : 通用文字识别(证件、单据)
66: 问答题
49 :recaptcha图片识别
二、图片旋转角度类型:
29 : 旋转类型
三、图片坐标点选类型:
19 : 1个坐标
20 : 3个坐标
21 : 3 ~ 5个坐标
22 : 5 ~ 8个坐标
27 : 1 ~ 4个坐标
48 : 轨迹类型
四、缺口识别
18 : 缺口识别(需要2张图 一张目标图一张缺口图)
33 : 单缺口识别(返回X轴坐标 只需要1张图)
五、拼图识别
53:拼图识别
使用:
找到验证码图片地址:
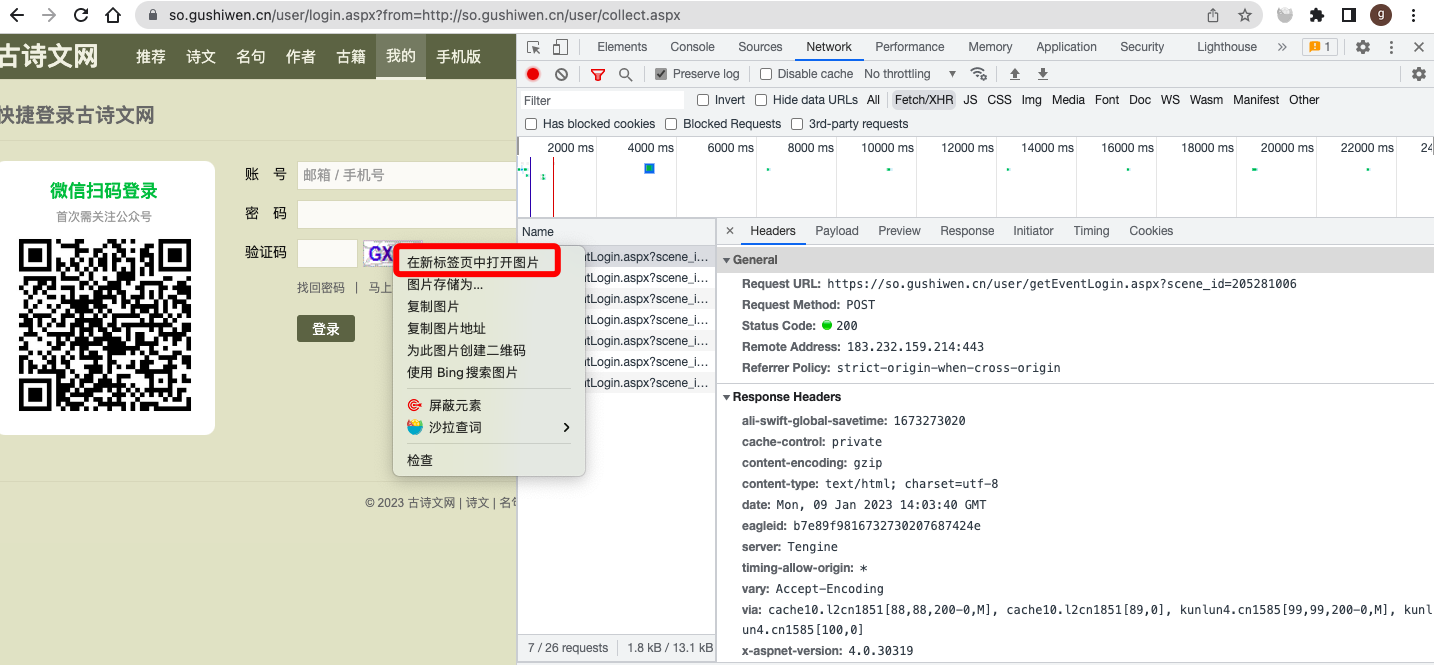
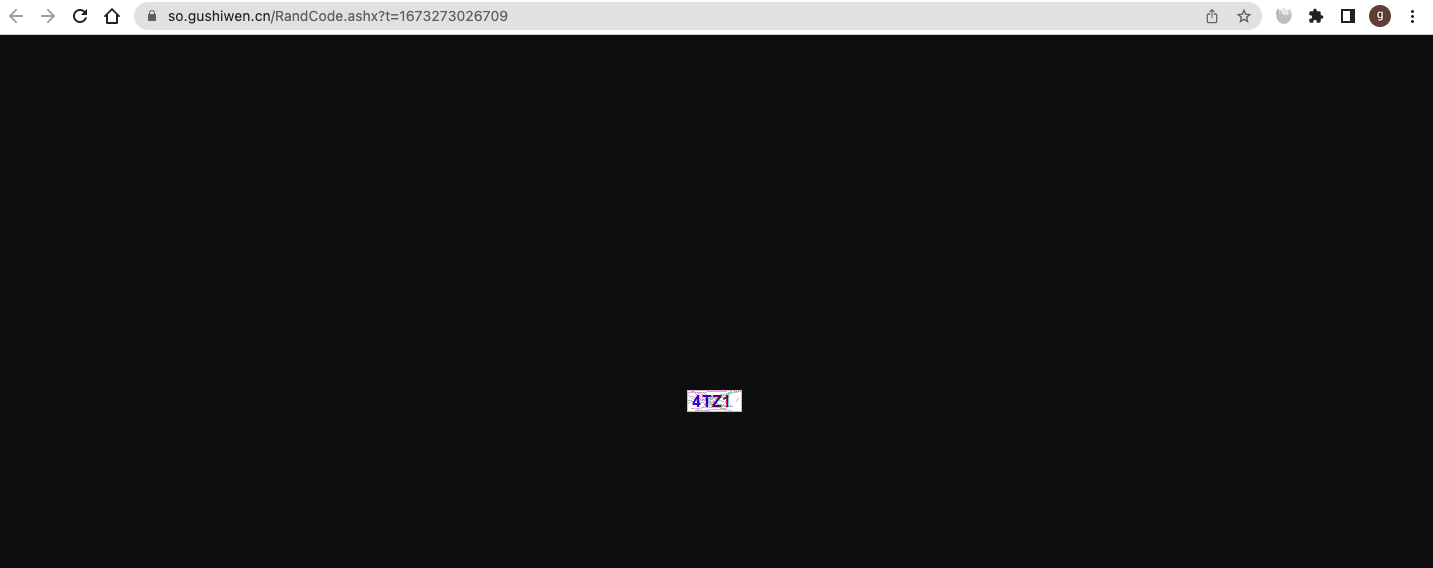
得到验证码的地址是: https://so.gushiwen.cn/RandCode.ashx?t=1673273026709
去掉后面不需要的字符,得到: https://so.gushiwen.cn/RandCode.ashx
故而代码如下:
import base64
import json
import requests
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
if __name__ == "__main__":
# 下载验证码图片
# img_url = 'https://so.gushiwen.cn/RandCode.ashx'
# res = requests.get(img_url)
# with open('yzm.jpg', 'wb') as f:
# f.write(res.content)
img_path = "yzm.jpg"
result = base64_api(uname='luckyboyxlg', pwd='17346570232', img=img_path, typeid=3)
print(result)登陆处理:
import base64
import json
import requests
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
def get_yzm(yzm_img_url):
session = requests.Session()
res = session.get(yzm_img_url)
with open('yzm.jpg', 'wb') as f:
f.write(res.content)
img_path = "yzm.jpg"
result = base64_api(uname='liang545621', pwd='chengce243', img=img_path, typeid=3)
return result
yzm_result = get_yzm('https://so.gushiwen.cn/RandCode.ashx')
# 登陆代码处理
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'referer': 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx',
}
data = {
'__VIEWSTATE': 'uXQtaTWF6vDTOrzMA1FWo3+hhUpxpOu91JftTTOlak/BaTntPx1NpI8um+bJQYOsz5q1jtBZ6aJ4N4SP5fXKCz6KfQG4eRXmJEc5pqjFMPUBvdavDCn6wzExU0fDtMsIRzySYpBgixzVyO/LP2FTrPsModg=',
'__VIEWSTATEGENERATOR': 'C93BE1AE',
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '793390457@qq.com',
'pwd': 'xlg17346570232',
'code': yzm_result,
'denglu': '登录',
}
session = requests.Session()
res = session.post(url, data=data, headers=headers)
print(res.text)
超级鹰
在进行爬虫抓取的时候遇到验证码怎么办? 这个问题其实一直都很蛋疼. 怎么解决呢?
-
自己想办法写一套深度学习算法. 有针对的去学习各种验证码的识别方案
-
使用互联网上已经相对成熟的产品进行验证码识别.
理性告诉我, 方案二更适合我.
这里推荐各位可以用超级鹰来做测试. 不同的平台使用的算法可能是不一样的. 但是调用方案几乎都差不太多.
我们来看看超级鹰怎么用. 首先, 登录超级鹰的官网. 然后需要注册. 注册后, 需要我们进入用户中心. 生成一个新的软件ID就可以用了
超级鹰网址: https://www.chaojiying.com/
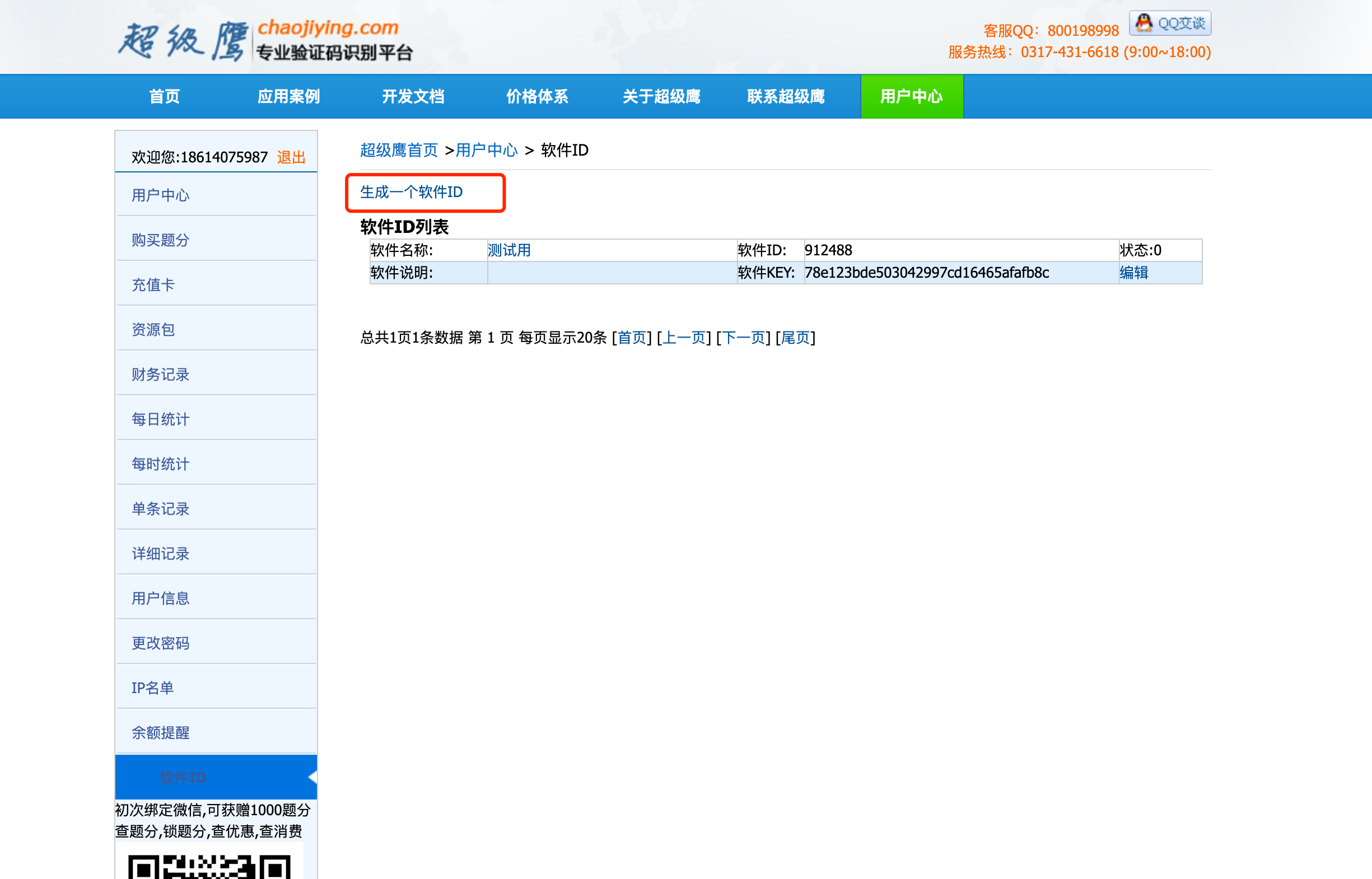
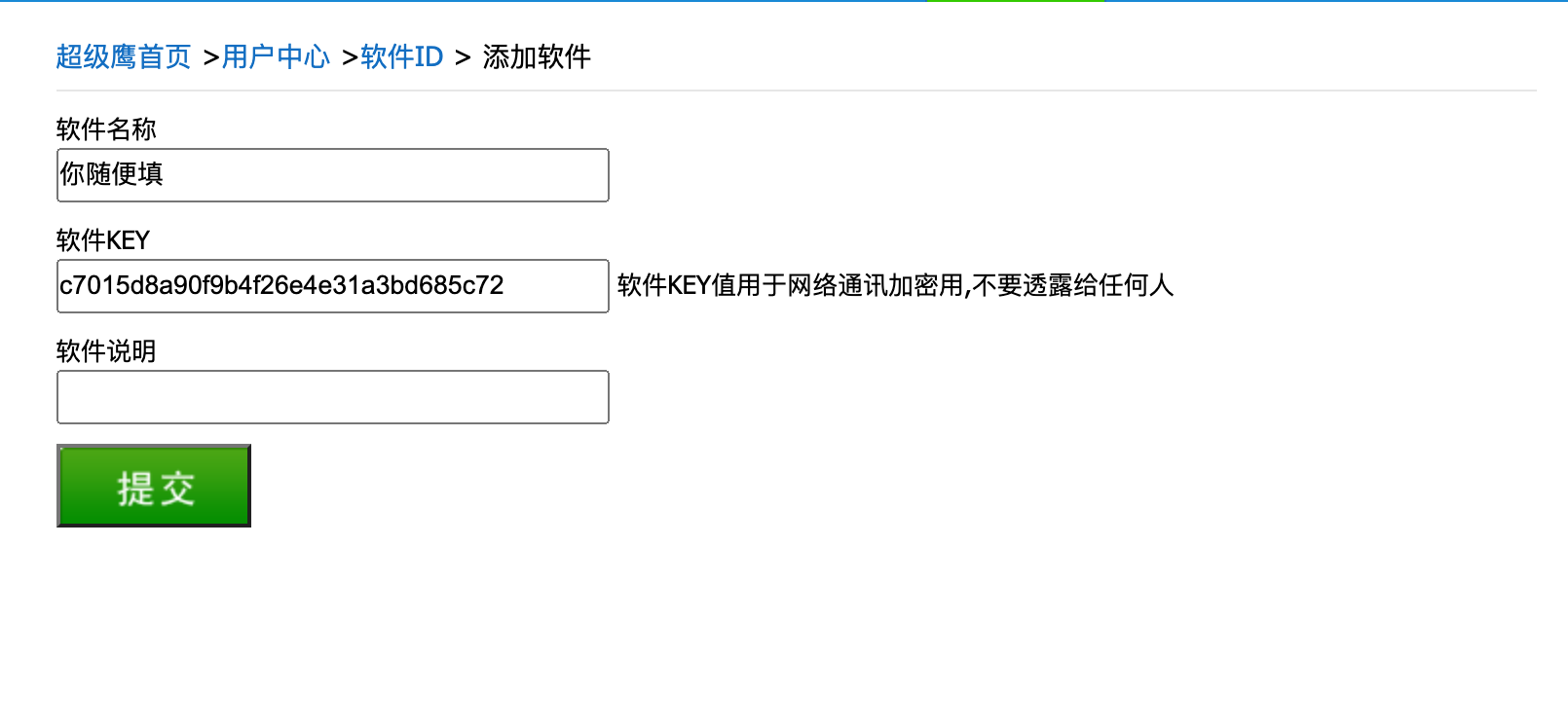
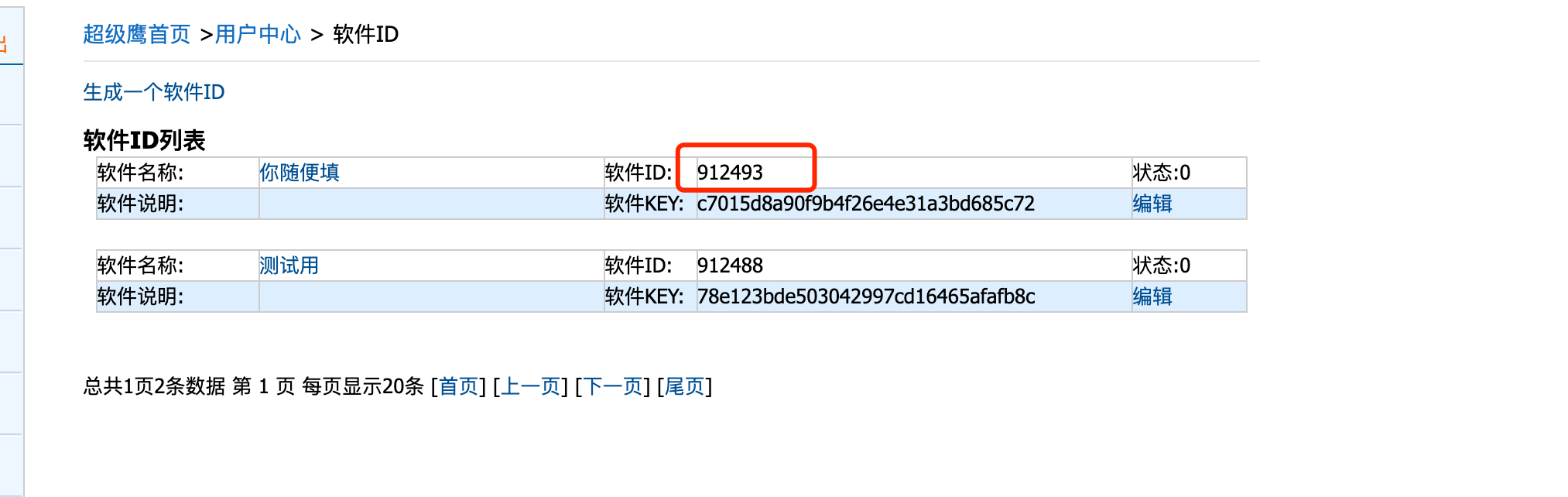
注意这个号, 后面会用到.
然后我们回到超级鹰的官网. 找到测试代码. 找到python的测试代码, 下载. 丢到pycharm里

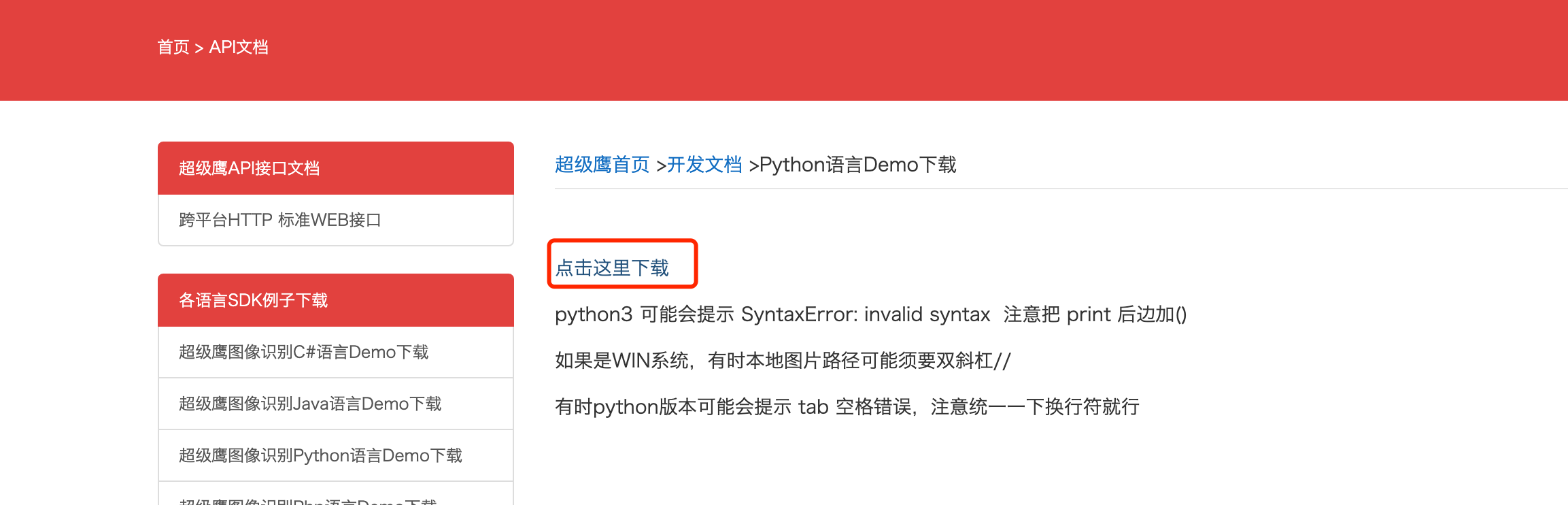
下载好的内容解压. 丢到pycharm中.

最后, 测试一下
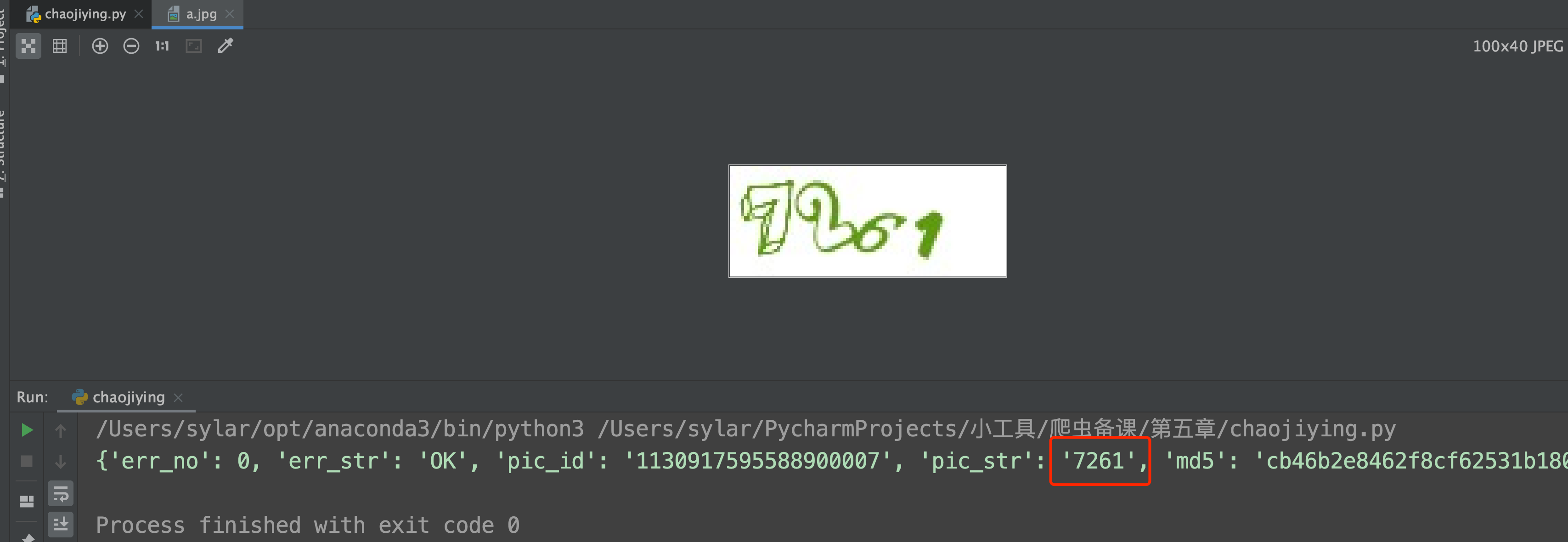
识别效果还是不错的.
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
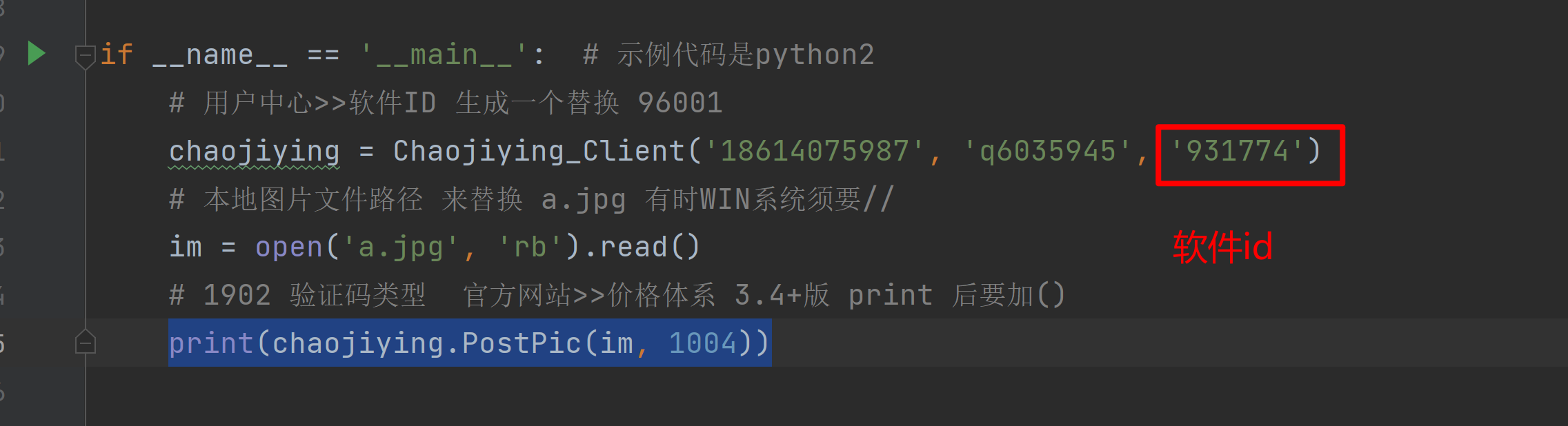
if __name__ == '__main__': # 示例代码是python2
# 用户中心>>软件ID 生成一个替换 96001
chaojiying = Chaojiying_Client('18614075987', 'q6035945', '931774')
# 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
im = open('a.jpg', 'rb').read()
# 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
print(chaojiying.PostPic(im, 1004))
如果遇到的验证码比较特殊. 可以更换代码中的1902位置的参数值. 具体情况可以参考官网上给出的参数列表
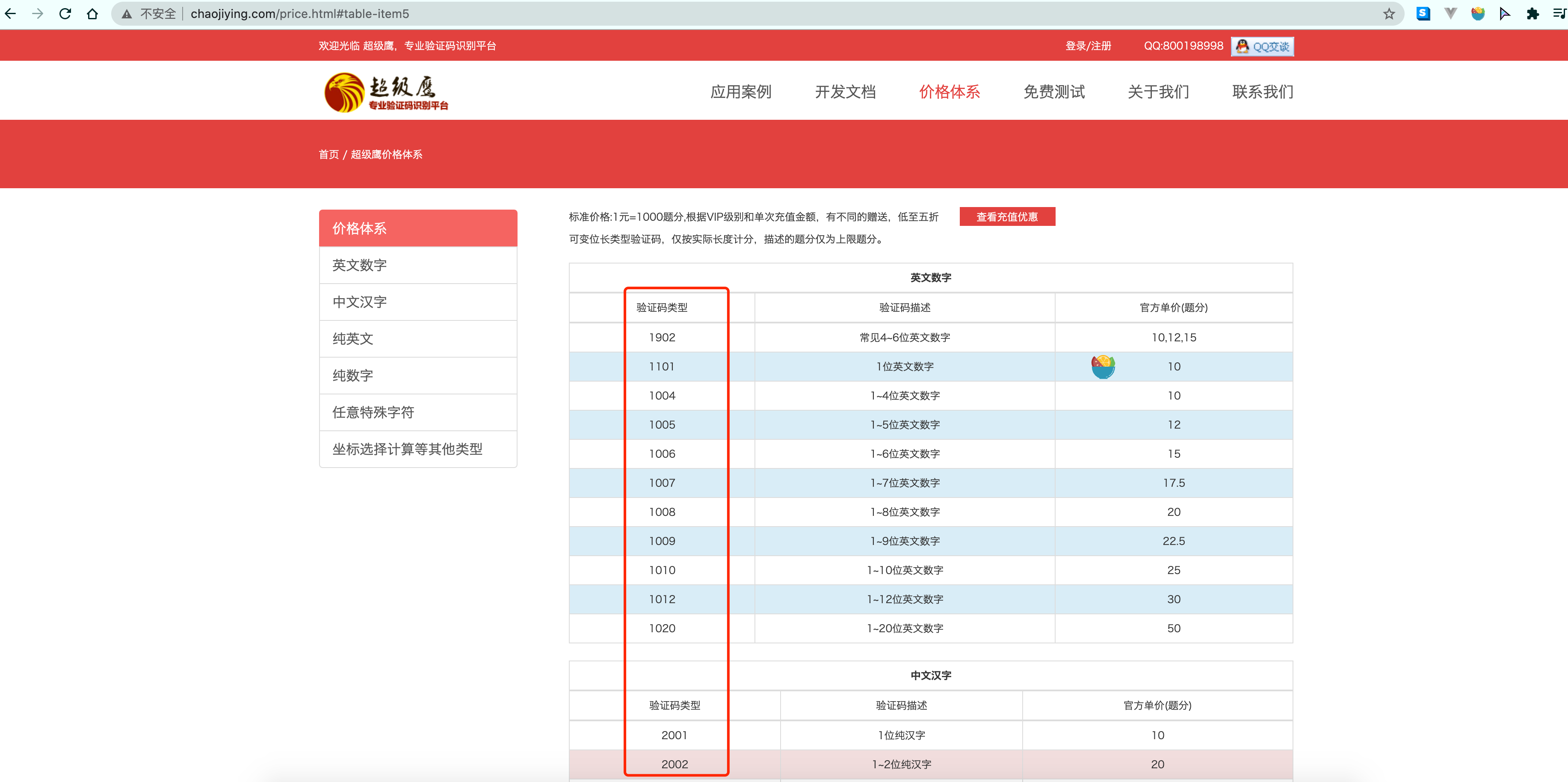
需要哪个填哪个就行.
各位可以自行做个测试. 用超级鹰来破解超级鹰的登录验证码~~ 相信会很有意思.
超级鹰干超级鹰
本小节, 我们用超级鹰来破解超级鹰的验证码. 看看效果如何~
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
web = Chrome()
web.get("https://www.chaojiying.com/user/login/")
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input").send_keys("18614075987")
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input").send_keys("q6035945")
img = web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')
# screenshot 截屏
bs = img.screenshot_as_png # 返回的是字节
# 交给超级鹰来进行识别
chaojiying = Chaojiying_Client('18614075987', 'q6035945', '931774')
dic = chaojiying.PostPic(bs, 1004) # 把图片的字节传递进去即可
code = dic['pic_str'] # 获取识别结果
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input").send_keys(code)
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input").click()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号