

ZooKeeper特性:数据存储
数据存储
不同于 Redis 的 key-value 结构, ZooKeeper 将所有的数据管理在一个树状结构中. 这个结构很像文件系统, 一个路径标识一个节点, 由若干个用斜杠隔开的名字组成. 根结点路径为 /, 因此路径总是由斜杠开头.
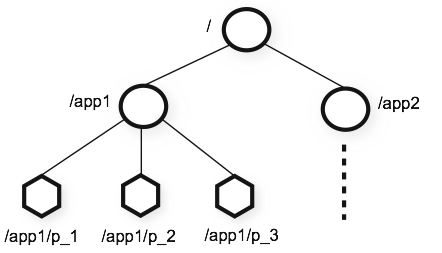
与文件系统不同的是, ZooKeeper 中叶子结点和内部节点都可以存储数据, 这就好比允许一个文件同时也是一个目录. 我们通常称 ZooKeeper 中的节点为 znode. 每个 znode 数据的存取是原子的, 要么一次性取出全部数据, 要么覆盖掉全部数据. znode 的操作十分简单:
- create : 创建一个节点
- delete : 删除一个节点
- exists : 判断节点是否存在
- get data : 获取指定节点的数据
- set data : 设置指定节点的数据
- get children : 获取指定节点的子节点列表
- sync : 等待数据同步 (稍后可以看到, 在集群化部署时需要考虑同步的问题)
观察一个节点
除了可以主动获取一个节点的数据, 我们还可以观察一个节点. exists, get data 和 get children 都可以设置观察. 如果设置了观察一个节点, 那么当这个节点发生改变当时候, 观察者就会收到通知. 例如观察 get data, 就会在节点的数据发生改变时收到通知.
对节点的观察通常是一次性的. 也就是说, 当一个观察会在它触发后立刻被移除. 如果需要继续观察这个节点, 就必须再次设置观察.
节点的权限
ZooKeeper 的每个节点都可以单独设置权限, 称为访问控制列表 ACL (Access Control List). 节点都支持以下几种权限:
- CREATE: 可以在这个节点下创建一个子节点
- READ: 可以读取这个节点的数据
- WRITE: 可以设置这个节点的数据
- DELETE: 可以删除这个节点下的子节点
- ADMIN: 可以修改这个节点的权限
注意 ZooKeeper 的权限仅作用于当前节点, 并不会影响其子节点. 也就是说可以将权限设置成 /app 可读但是 /app/status 不可读.
不同于 UNIX 文件系统中 user, group, other 三种权限作用域, ZooKeeper 的每个节点都有一个访问者 id 到访问权限的映射列表. 每个 id 的格式为 scheme:expression, scheme 为这个 id 的方案, expression 则具体定义这个 id. 例如 ip:172.16.16.1 就是一个 id, 它的方案为 IP, 标识 IP 地址为 172.16.16.1 的用户. ZooKeeper 权限有以下几种方案:
- world: 代表所有用户.
- auth: 代表当前用户. 当一个用户想创建一个仅能被它自己访问的节点时就可以使用 auth 代表它自己.
- digest: 使用字符串
username:password生成的 MD5 哈希作为 id. - ip: 使用 IP 地址作为 id.
- x509: 使用 x509 证书作为 id.
持久化
ZooKeeper 会将整个树状结构的数据都存储在内存中. 然而仅存储在内存中是不够的, 为了防止数据丢失, 还必须持久化在硬盘上. ZooKeeper 的做法有些类似于 Redis 的 AOF: 所有的更新操作都会实时记录在一个日志文件中; 当这个日志文件变得足够大了, ZooKeeper 就会生成一个包含当前所有 znode 数据的快照文件, 然后再创建一个新的日志文件, 之后的操作事务就会记录在这个新的日志文件中. 在生成快照的过程中产生的操作事务仍然记录在旧的日志文件中. 需要说明的是 ZooKeeper 不会自动清理旧的日志文件和快照文件, 这需要管理者定期手动清理.
集群部署
ZooKeeper 的一个重要特性就是支持集群部署, 称为复制模式 (replicated mode), 因此健壮性很高.
ZooKeeper 可以配置为多台机器协同工作, 这些机器整体作为一个 ZooKeeper 服务. 数据会自动在这些服务器之间同步, 客户端可连接其中的任意一台服务器. 如果客户端连接的服务器宕机, 它可以立刻转而连接另外的服务器, 而保持原有的会话状态. ZooKeeper 保证只要大部分服务器可用, 整个 ZooKeeper 服务就是可用的.
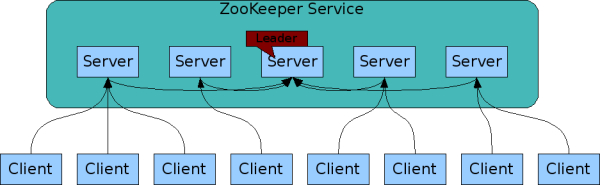
ZooKeeper 要求一半以上的服务器可用, 整个服务就可用, 因此 ZooKeeper 服务器的数量通常是奇数个. 3 台机器可承受 1 台机器故障, 5 台机器可承受 2 台机器故障; 然而 4 台机器 只能承受 1 台机器故障, 2 台机器无法承受机器故障.
由于 ZooKeeper 的服务器之间要互相同步数据, 因此 znode 中不宜存储过大的数据, 一般大小在字节到千字节到范围内. 过大的数据会导致存取效率低下.
一致性保证
尽管 ZooKeeper 是分布式的, 它仍然提供了一系列的一致性保证:
- 顺序一致性: 来自客户端的更新请求会按照发送到顺序依次执行.
- 原子性: 更新要么成功, 要么失败. 不会有中间状态.
- 单系统映像: 无论客户端连接 ZooKeeper 服务中的哪个服务器, 它看到的东西都是一样的. 即使客户端由于一些故障改变了连接的服务器, 只要在同一个会话中, 它看到的数据也是最新的.
- 可靠性: 一旦应用了一次更新操作, 就会保持这个状态直到下次更新覆盖它. 这个保证有两个结果:
- 一旦客户端的操作返回了成功, 就确保这次操作的更新已经生效了 (这也被称为单调性).
- 即使出现服务器宕机, 也不会造成任何数据回滚.
- 及时性: 整个系统中客户端看到的东西能保证在一定的时间范围 (大约几十秒) 内是最新的. 可通过 sync 操作等待当前数据更到最新.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号