

死锁
死锁
死锁的原因总是并发事务间加锁顺序不一致,导致互相等待,进而死锁。听起来似乎很简单,但是每一个死锁场景的分析都不是一件简单的事,一方面在于Innodb锁机制的复杂性,另一方面则是死锁日志信息的局限性。本文档必须先介绍基本的锁机制,然后再介绍死锁的分析方法,以及几个死锁案例。
1.IoonDB锁机制
1.1 锁生存周期
2PL(Two-Phase Locking)
二阶段锁,说的是锁操作分为两个阶段:加锁阶段与解锁阶段,并且保证加锁阶段与解锁阶段不相交。
¨ 加锁:实际访问到某个待更新的行时,对其加锁(而非一开始就将所有的锁都一次性持有)
¨ 解锁:事务提交/回滚时(而非语句结束时就释放)
1.2 锁模式
InnoDB实现标准的行级锁,其中有两种模式的锁:
¨ 共享锁,LOCK_S
¨ 排他锁,LOCK_X
通常有一种含糊的说法:对行加S锁,其他事务只能对该行读,不能修改;对行加X锁,其他事务对该行不可读、写。
其实这是完全错误的,且不说InnoDB中的“读”为快照读不加锁,其关系也完全颠倒混乱了。可以以这样的顺序来理解:
- 事务T1执行 select * from t1 where id=1 lock in share mode,会先获取id=1行的共享(S)锁,才允许读取id=1这一行的数据;
- 事务T2同样执行 select * from t1 where id=1 lock in share mode,也要先申请获取id=1行的S锁,因为S锁之间兼容,可以成功获取锁,得以查询数据;
- 事务T3执行 update t1 set a=99 where id=1,要先申请id=1行的X锁,因为X锁与S锁互斥,所以获取不成功,需要等待,则更新也就无法执行。
所以对某行加S锁,只能说该事务可以读取这一行;对某行加X锁,只能说该事务可以读取、修改这一行。而不能直接说不允许其他事务读或者修改这一行。
1.3 锁属性
InnoDB实现的是行级锁没错,但是一细分,其实还有其他属性的锁,下面一一介绍。
¨ 记录锁(Record Locks)
记录锁定是对索引记录的锁定。请记住,对象是索引上的记录。
¨ 间隙锁(Gap Locks)
间隙锁定是对索引记录之间的间隙的锁定。REPEATABLE-READ隔离级别就是通过间隙锁解决幻读的:T1锁定间隙,其他事务就无法在间隙中插入数据,这样T1下一次读到的数据不会变多。
实际上除了REPEATABLE-READ隔离级别,在 READ-COMMITTED 隔离级别,也会存在 gap lock ,只发生在:唯一约束检查到有唯一冲突的时候,会加 S Next-key Lock,即对记录以及与和上一条记录之间的间隙加共享锁。
¨ Next-Key Locks
Next-Key Locks是索引记录上的记录锁和上一条记录之间的间隙上的间隙锁的组合。
¨ 意向锁(Intention Locks)
意向锁是一种表锁,分两种:
- 意向共享锁(intention shared lock, IS):事务有意向对表中的某些行加共享锁(S锁)。事务获取某些行的 S 锁前,必须先获得表的 IS 锁。
SELECT column FROM table ... LOCK IN SHARE MODE;
- 意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些行加排他锁(X锁)。事务获取某些行的 X 锁前,先获得表的 IX 锁。
SELECT column FROM table ... FOR UPDATE;
它是为了允许行锁和server层表级锁并存,并且高效而存在的。在执行 lock table t read 时,想要获取表锁,必须保证:
- 当前没有其他事务持有t表的排他锁
- 当前没有其他事务持有t表中任意一行的排他锁
为了检测是否满足第二个条件,T2必须在确保t表不存在任何排他锁的前提下,去检测表中的每一行是否存在排他锁。很明显这是一个效率很差的做法。有意向锁后,只需要检测t表是否存在排他意向锁即可。
最后一定要记住意向锁的特性:
- 意向锁是为了阻塞表级锁存在的
- 意向锁不会与行级的共享/排他锁互斥
- 意向锁不会与意向锁互斥
¨ 插入意向锁(Insert Intention Locks)
执行insert时,在数据插入前需要对插入的间隙加的一种间隙锁称为插入意向锁。虽然也是一种间隙锁,但是属性特殊:
- 它不会阻塞其他任何锁;
- 它本身仅会被 gap lock 阻塞。
只有在它被阻塞的时候才能观察到,所以常常会被忽略。
¨ 自增锁(AUTO-INC Locks)
自增锁是一种特殊的表级锁,在向具有auto_increment字段属性的表中插入数据时,因为要获取字段的自增值而获取的锁。由innodb_autoinc_lock_mode参数控制加锁行为:
- 0,代表传统模式,也就是说,在对有自增属性的字段插入记录时,会持续持有一个表级别的自增锁,直到语句执行结束为止。
- 1,默认值,普通 insert 能够确定行数的,可能一次性获取到需要的自增值,自增锁在申请之后马上释放。类似 insert ...select 这样不确定插入的行数时,需要等语句执行完才释放自增锁;
- 2,建议使用,交叉模式,自增值即取即用,可以并发获取,但是会不连续。所有 insert类型都是申请后就释放锁(需要 binlog_format=row,才能保证主从数据一致)。
1.4 锁组合
上面详细介绍了锁模式和锁属性,这两者是可以组合的,比如:记录锁+LOCK_S、记录锁+LOCK_X
1.5 锁冲突矩阵
要分析死锁,一定要清楚锁与锁之间的冲突关系:
|
待加锁 存在锁 |
S(Record) |
S(Gap) |
S(Next-Key) |
X(Record) |
X(Gap) |
X(Next-Key) |
Insert-Intention |
|
S(Record) |
|
|
|
冲突 |
|
冲突 |
|
|
S(Gap) |
|
|
|
|
|
|
冲突 |
|
S(Next-Key) |
|
|
|
冲突 |
|
冲突 |
冲突 |
|
X(Record) |
冲突 |
|
冲突 |
冲突 |
|
冲突 |
|
|
X(Gap) |
|
|
|
|
|
|
冲突 |
|
X(Next-Key) |
冲突 |
|
冲突 |
冲突 |
|
冲突 |
冲突 |
|
Insert-Intention |
|
|
|
|
|
|
|
1.6 SQL与加锁
有了前面的认识,接下来要掌握的就是在InnoDB中各种SQL操作需要加的锁。先记住一个概念:同一个SQL,在不同的索引、不同的隔离级别下加的锁是不同的。
下面我们分别介绍在RC隔离级别下增、删、改、查4种SQL操作的加锁行为。
¨ select
快照读:不加锁(普通的 select * from t where id=1)
当前读:对扫描的行记录加相应的锁(显示加锁的读 select * from t where id=1 for update,修改数据也属于当前读)
¨ delete
对满足条件的所有记录加排他锁:LOCK_X + LOCK_REC_NOT_GAP
¨ insert
无unique key时:LOCK_INSERT_INTENTION + LOCK_X + LOCK_REC_NOT_GAP
有unique key时:
- 先进行唯一性约束检查,如果发生冲突,会加 S Next-Key Lock,否则不加;
- 如果没有冲突,接下来向插入间隙加插入意向锁 LOCK_INSERT_INTENTION,如果该间隙已经存在Gap Lock,会被阻塞;
- 如果没被Gap Lock阻塞,数据插入成功,最后加 LOCK_X + LOCK_REC_NOT_GAP
¨ update
update可以看作delete+insert的组合:
- Step 1:定位到下一条满足查询条件的记录(查询过程)
- Step 2:删除当前定位到的记录(标记为删除状态)
- Step 3:拼装更新后项,根据更新后项定位到新的插入位置
- Step 4:在新的插入位置,判断是否存在 Unique 冲突(存在Unique Key时)
- Step 5:插入更新后项(不存在Unique冲突时)
- Step 6:重复Step 1到Step 5的操作,直至扫描完整个查询范围
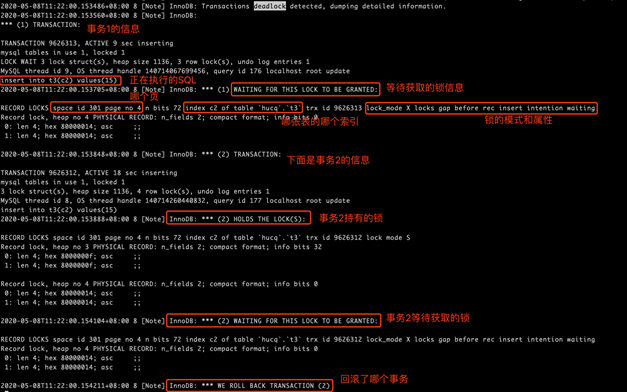
2 阅读死锁日志
MySQL默认是开启死锁检测的,一旦发生死锁,InnoDB会回滚其中一个事务,将锁解放。默认show engine innodb status 会记录上一次的死锁日志,也可以设置innodb_print_all_deadlocks 将每一次死锁的日志记录到error log中。
死锁日志中列出了死锁发生的时间,以及导致死锁的事务信息(只显示两个事务,如果由多个事务导致的死锁也只显示两个),并显示出每个事务正在执行的 SQL 语句(事务执行多个SQL,只会记录正在执行的那个)、等待的锁以及持有的锁信息等。
死锁日志的局限性:
- 不显示事务1已经持有了什么锁;
- 不显示事务所有的SQL,也就没法推测事务1已经持有了什么锁。
3 得到完整的事务
分析死锁原因的第2步就是联系开发获取事务1、事务2的全部SQL,然后写出每个SQL加的锁,构造可能死锁的执行顺序,然后进行复现。每个事务中SQL的执行顺序是固定的,但是2个事务并发执行,就会有多种顺序组合,并不是都会触发死锁。举个例子:
同样2个事务,按以下顺序执行会死锁:
|
T1: |
T2: |
|
begin; |
begin; |
|
update t set a=9 where id=1; |
update t set a=99 where id=5; |
|
update t set a=99 where id=5; |
|
|
|
update t set a=9 where id=1; |
按以下顺序执行却不会死锁:
|
T1: |
T2: |
|
begin; |
begin; |
|
update t set a=9 where id=1; |
|
|
update t set a=99 where id=5; |
|
|
|
update t set a=99 where id=5; |
|
|
update t set a=9 where id=1; |
2个事务可以有n*m种顺序组合(n、m表示事务中的SQL数量),很难一一列举出来进行分析,所以我们需要记住一些死锁的常见原因:
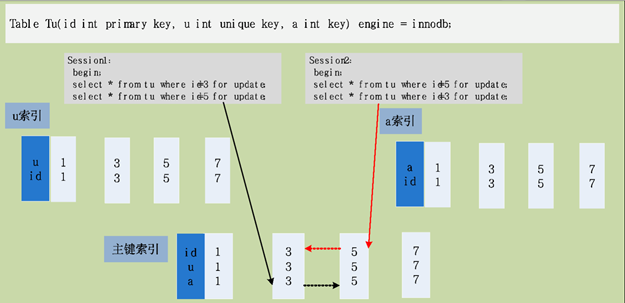
¨ 事务以相反的顺序操作相同的数据;
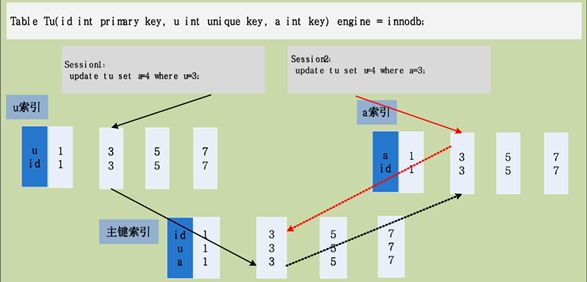
¨ 事务以不同索引的过滤条件,来操作相同的记录;
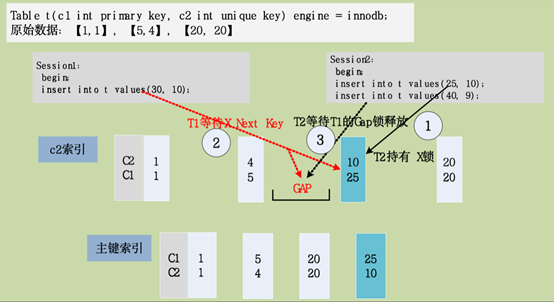
¨ 存在Unique key的表中,insert时容易出现由于唯一性约束检查而产生的 gap lock,导致死锁概率的增加。
4死锁案例
4.1 相反的顺序操作相同的数据
4.2 不同的过滤条件操作相同的记录
4.3 唯一键冲突,并发插入相同数据
5 解决方法
分析原因需要与开发合作,找出死锁的逻辑,由开发最终修改代码来解决。另外一点可以修改隔离级别为READ-COMMITTED,减少Gap Lock 产生的死锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号