python爬虫(1)requests库
在pycharm中安装requests库的一种方法
首先找到设置
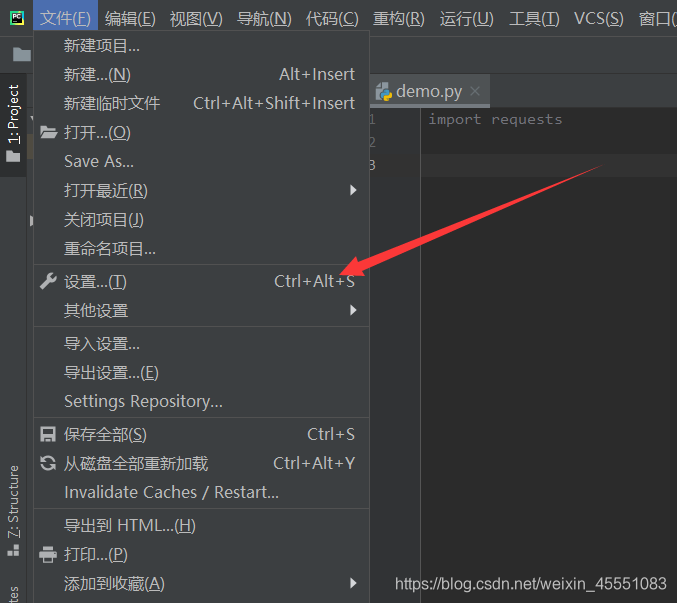
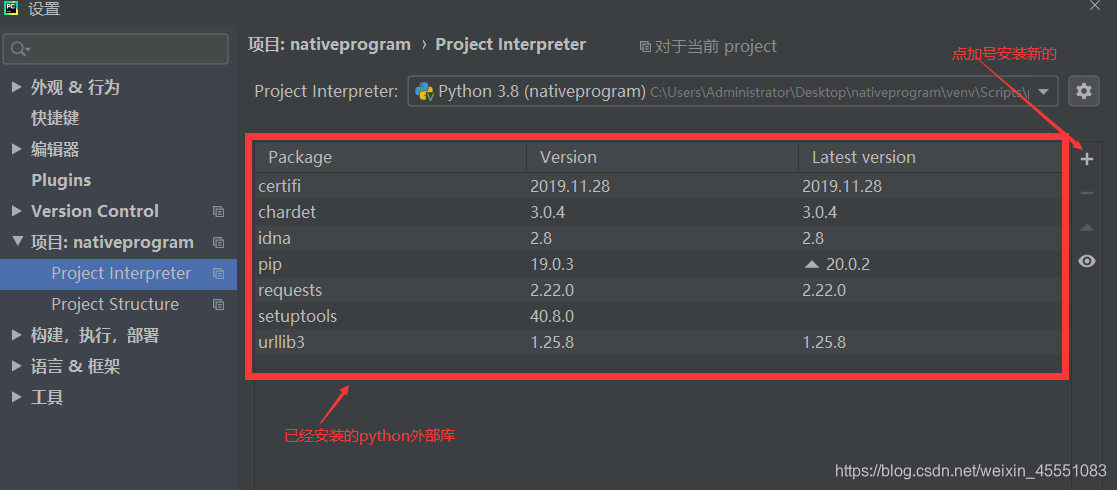
搜索然后安装,蓝色代表已经安装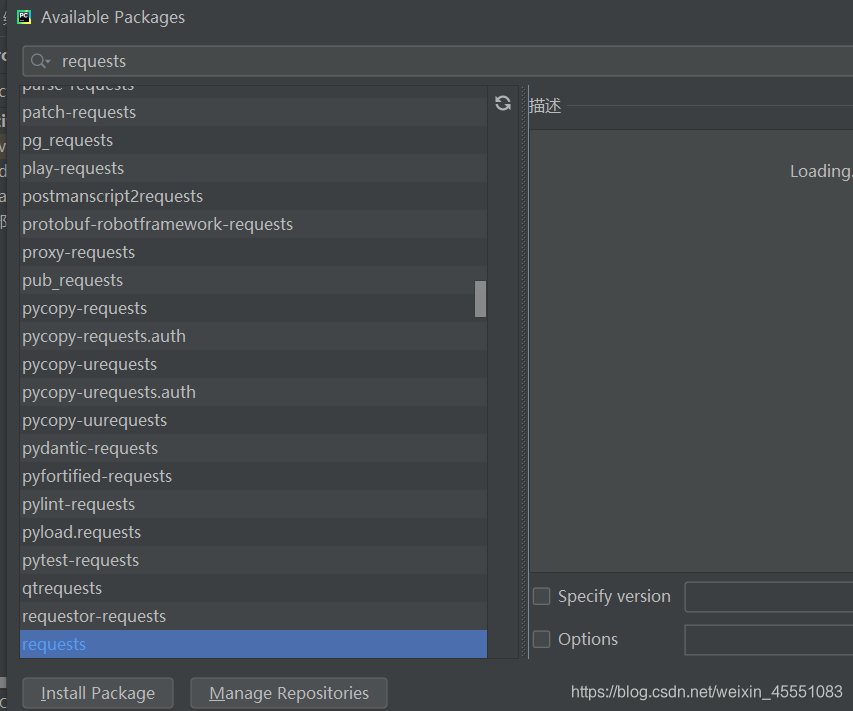
requests库中的get请求
- 与HTTP协议相对应,requests库也有七种请求方式.
| 获取url | requests.get(url.params,kwargs) |
|---|
r = requests.get(url,params=None,**kwargs)
url:模拟获取页面的url连接
params:url中的额外参数,字典或字节流格式
**kwargs:12个控制访问的参数
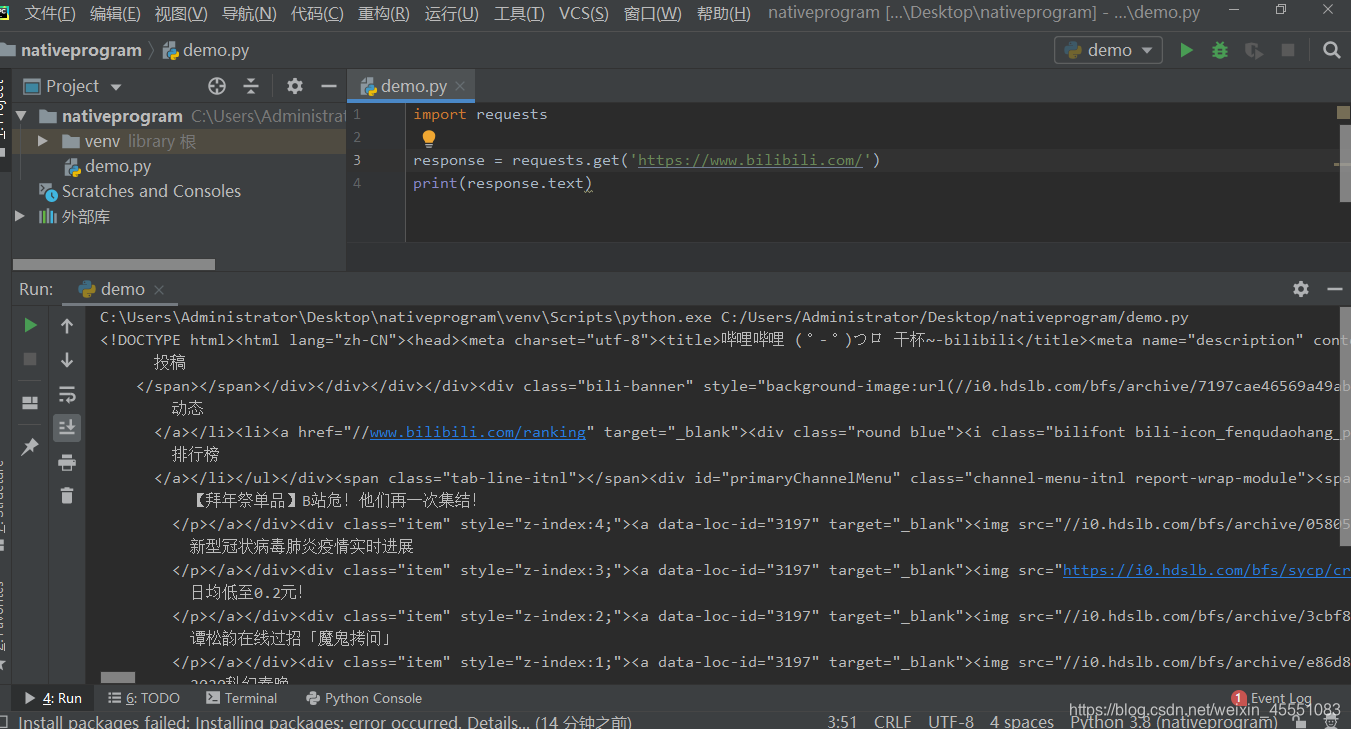
demo
-
这里爬取了哔哩哔哩的一个页面
-
基本的get请求
request库的七个方法 -
主要用到的即requests.get()
-
还有: requests.request() ; requests.post() ; requests.head() ; requests.put() ; requests.patch() ; requests.delete()
response对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态 |
| r.text | HTTP响应内容的字符串形式,即:url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式 |
| r.content | HTTP响应内容的二进制形式 |
[博客内容只是本人学习过程记录的笔记,不保证质量.本人不保证技术的实用性,一切文章仅供参考,如有谬错,请留言.]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号