
hyperf 注解
Hyperf的注解是一种内嵌在代码中的结构化配置指令
是什么
一种为类、方法、属性等代码声明部分添加结构化元数据的能力。它不是普通注释,而是框架可读取的“配置式语言”,目的是实现功能定义与功能使用的解耦。
如何工作
注解本身只是元数据定义,其作用依赖于框架的收集与利用。
-
收集:启动时,Hyperf的注解扫描器会读取代码,将所有注解的元数据收集到 Hyperf\Di\Annotation\AnnotationCollector 类(或你自定义的收集器)中。
-
利用:在框架运行过程中,相关组件(如路由、依赖注入容器、AOP切面)会在需要时查询这些已收集的元数据,并执行相应逻辑。
注解的主要用途与分类
可应用于类、类方法和类属性
| 类别 | 典型注解 | 应用对象 | 主要用途与示例 |
|---|---|---|---|
| 路由与控制 | #[Controller]、#[GetMapping] |
类、方法 | 定义HTTP路由。#[GetMapping(path: “/user”)] 会将方法绑定到 /user 的GET请求。 |
| 依赖注入 | #[Inject], #[Value] |
属性 | 实现依赖自动注入。#[Inject] 注入对象,#[Value(“${config.key}”)] 注入配置值。 |
| 参数校验 | #[Validation] |
方法 | 自动验证请求参数,失败则抛出异常。 |
| 事件监听 | #[Listener]`` | 类 | 将类标记为事件监听器。 |
| 异步任务 | #[Async], #[Crontab] |
方法 | 声明异步执行方法或定时任务。 |
| 切面编程 | #[Aspect] |
类 | 标记一个类为AOP切面,用于拦截特定注解或方法。 |
自定义注解:从创建到应用
文档详细说明了自定义注解的完整流程,这是实现高度解耦业务逻辑的关键。其过程可以概括为下图:
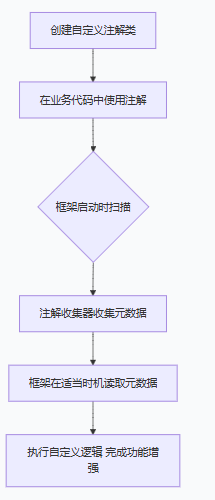
-
- 创建注解类
你需要创建一个继承 Hyperf\Di\Annotation\AbstractAnnotation 的类,并使用 #[Attribute] 定义其可用的目标。
这个注解类,就像我们定义一个标签的样式和可写的参数.
- 创建注解类
<?php
// 文件:app/Annotation/Cacheable.php
namespace App\Annotation;
use Attribute;
use Hyperf\Di\Annotation\AbstractAnnotation;
// 这个“标签”只能贴在类的方法上 (Attribute::TARGET_METHOD)
#[Attribute(Attribute::TARGET_METHOD)]
class Cacheable extends AbstractAnnotation
{
// 定义标签上可写的参数:$prefix 缓存键前缀,$ttl 缓存时间(秒)
public function __construct(public string $prefix = '', public int $ttl = 3600)
{
// 父类 AbstractAnnotation 会自动将接收到的参数(如 ['prefix'=>'user', 'ttl'=>100])
// 赋值给这个对象的同名属性 $this->prefix 和 $this->ttl
}
}
此刻,这个“标签”还只是个空壳,贴上去什么也不会发生。
-
- 使用注解
创建后,即可在业务代码中像使用内置注解一样使用它
现在,我们可以在任何服务类的方法上,贴上这个自定义的“标签”。
- 使用注解
<?php
// 文件:app/Service/UserService.php
namespace App\Service;
use App\Annotation\Cacheable;
class UserService
{
// 在 getUserInfo 方法上贴上标签,并写上参数:缓存前缀为 ‘user’, 有效时间100秒
#[Cacheable(prefix: 'user', ttl: 100)]
public function getUserInfo(int $userId): array
{
// 这是真实的、可能很耗时的数据库查询逻辑
echo “正在查询数据库获取用户 {$userId} 的信息...\n”;
return [
‘id’ => $userId,
’name’ => ‘张三’,
’email’ => ‘zhangsan@example.com’
];
}
}
即使贴了标签,方法仍然会每次执行真实逻辑,因为还没有人来看这个标签并采取行动。
-
- 注解收集
我们需要一个“登记员”,在项目启动时扫描所有代码,把Cacheable标签贴在哪儿、参数是什么,都记录到一个本子上(AnnotationCollector)。
这个“登记”行为,我们在 Cacheable 注解类自身内部定义。修改第一步的 Cacheable.php 文件:
- 注解收集
<?php
// 文件:app/Annotation/Cacheable.php (修改后)
namespace App\Annotation;
use Attribute;
use Hyperf\Di\Annotation\AbstractAnnotation;
use Hyperf\Di\Annotation\AnnotationCollector; // 引入收集器
#[Attribute(Attribute::TARGET_METHOD)]
class Cacheable extends AbstractAnnotation
{
public function __construct(public string $prefix = '', public int $ttl = 3600) {}
// 当扫描器发现这个注解用在某个类的方法上时,会自动调用此方法
public function collectMethod(string $className, ?string $target): void
{
// 核心:将当前注解对象($this)的信息,登记到“总账本”中。
// 登记的信息是:“在 $className 类的 $target 方法上,有一个 Cacheable 注解,它的参数是 $this。”
AnnotationCollector::collectMethod($className, $target, static::class, $this);
}
}
现在,“登记员”工作了。项目启动后,AnnotationCollector 里就有了所有 Cacheable 的使用记录。
-
- 让“标签”真正起作用(实现功能 - AOP切面)
在方法执行时,拦截它,先查缓存,如果有就返回,没有才执行方法并存入缓存。
在Hyperf中,这个“拦截并增强”的功能,通常由 AOP切面(Aspect) 来实现。
- 让“标签”真正起作用(实现功能 - AOP切面)
<?php
// 文件:app/Aspect/CacheableAspect.php
namespace App\Aspect;
use App\Annotation\Cacheable;
use Hyperf\Di\Annotation\Aspect;
use Hyperf\Di\Aop\AbstractAspect;
use Hyperf\Di\Aop\ProceedingJoinPoint;
use Hyperf\Context\Context; // 这里简单用Context模拟缓存,实际应用请用Redis等
use Hyperf\Di\Annotation\AnnotationCollector; // 引入总账本
// 声明这是一个切面,专门拦截带有 @Cacheable 注解的方法
#[Aspect]
class CacheableAspect extends AbstractAspect
{
// 要拦截的注解或类
public array $annotations = [
Cacheable::class,
];
// 环绕通知:在目标方法前后执行
public function process(ProceedingJoinPoint $proceedingJoinPoint)
{
// 1. 获取当前被拦截的方法所属的类和方法名
$className = $proceedingJoinPoint->className;
$methodName = $proceedingJoinPoint->methodName;
// 2. 去“总账本” (AnnotationCollector) 里查询这个方法的 Cacheable 注解元数据
/** @var null|Cacheable $annotation */
$annotation = AnnotationCollector::getMethodAnnotation($className, $methodName, Cacheable::class);
// 如果该方法没有 Cacheable 注解(理论上不会,因为被$this->annotations过滤了),直接执行原方法
if (!$annotation) {
return $proceedingJoinPoint->process();
}
// 3. 根据注解参数生成唯一的缓存键 (这里拼接了前缀和方法参数)
$args = $proceedingJoinPoint->arguments['keys'];
$cacheKey = sprintf(‘%s:%s:%s’, $annotation->prefix, $methodName, md5(json_encode($args)));
// 4. 尝试从缓存中获取 (这里用Hyperf的Context内存存储简单演示)
if (Context::has($cacheKey)) {
echo “从缓存中获取数据...\n”;
return Context::get($cacheKey);
}
// 5. 缓存不存在,则执行原始方法(例如:查询数据库)
echo “执行真实业务逻辑...\n”;
$result = $proceedingJoinPoint->process();
// 6. 将结果存入缓存,并设置TTL (此处Context无TTL,仅为演示。实际请用Redis)
Context::set($cacheKey, $result);
// 实际代码: $this->redis->setex($cacheKey, $annotation->ttl, serialize($result));
// 7. 返回结果
return $result;
}
}
-
- 配置自定义收集器
编辑 config/autoload/annotations.php 文件:
- 配置自定义收集器
<?php
return [
‘scan’ => [
‘collectors’ => [
// 添加你的自定义注解类到收集器数组
\App\Annotation\Cacheable::class,
],
],
];
-
- 最后
当以上所有步骤完成后,你的 UserService::getUserInfo 方法行为就完全改变了:
- 最后
// 第一次调用:执行真实逻辑,并缓存
$user1 = $userService->getUserInfo(1);
// 输出:正在查询数据库获取用户 1 的信息... / 执行真实业务逻辑...
// 第二次调用(100秒内):直接返回缓存结果
$user2 = $userService->getUserInfo(1);
// 输出:从缓存中获取数据...
自定义注解的本质是:1. 定义标记 -> 2. 收集标记 -> 3. 利用标记。
这个过程实现了 “声明”与“实现”的完美分离。业务开发者在写 UserService 时,只需关心“这里需要被缓存”(声明),而缓存具体怎么实现(AOP切面中的Key生成、Redis操作、TTL处理)则由另一部分基础设施代码负责。这使得代码极其干净、可维护,且缓存逻辑可以统一修改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号