
2025.5.8广州软通动力java实习面试
前言
窝看到周围的同学们有一部分出去实习了,以及部分兄弟在打游戏的时候问啥时候出去实习,这也是让我在忙完其他东西后,开始准备迎接就业这一阶段。最后也是在4月30的时候,投了很多简历,但是可能那时候放假的原因,没人鸟我,终于在5月6有个软通动力的回复窝了,一开始我因为没人鸟我,我投了很多,我一开始投的是测试方向的,hr可能发现了我简历的开发方面的,跟我说不合适,我的心凉了一半,窝在想好不容易有人理窝了,不会又结束了吧,可能双非一本确实在简历不是很好看,也没有很多大赛经历,但是最后她还是在7号,跟我说过了简历,约我面试。终于啊,在5月8号,星期四,窝也是引来了处女面。
面试过程
首先面试官确定身份,并要求进行自我介绍一下
1.随后叫你介绍一下你简历里面写的项目的大概情况。
2.在听完你说后,他会问你,你的项目实现了什么功能。
3.由于我拿了两个项目一个学校里面帮研究生搞的东西,一个是学网上的苍穹外卖,但是他就问了我苍穹外卖,问我是否实现了商户入驻,我说没实现,后面看到我写了SpringTask,就问里面的订单超时、订单延时这类具体如何实现
4.随后就问了线程池参数
线程池七大参数(内容来自https://blog.csdn.net/Carrie_Q/article/details/108696481)
corePoolSize——核心线程最大数
maximumPoolSize——线程池最大线程数
keepAliveTime——空闲线程存活时间。
当一个非核心线程被创建,使用完归还给线程池
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由
keepAliveTime来设定
unit——空闲线程存活时间单位
这是keepAliveTime的计量单位
workQueue——等待队列
当线程池满了,线程就会放入这个队列中。任务调度再取出
jdk提供四种工作队列
1.ArrayBlockingQueue——基于数组的阻塞队列,按FIFO,新任务放队尾
有界的数组可以防止资源耗尽问题。
当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。
如果队列已经是满的,则创建一个新线程,
如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
2.LinkedBlockingQuene——基于链表的无界阻塞队列,按照FIFO排序
其实最大容量为Interger.MAX
由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,
因此使用该工作队列时,参数maxPoolSize其实是不起作用的
3.SynchronousQuene——不缓存任务的阻塞队列
生产者放入一个任务必须等到消费者取出这个任务。
也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,
如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略
4.PriorityBlockingQueue——具有优先级的无界阻塞队列
优先级通过参数Comparator实现。
threadFactory线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等
handler——拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,就用到拒绝策略
jdk中提供了4中拒绝策略
1.CallerRunsPolicy——主线程自己执行该任务
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,否则直接抛弃任务。
2.AbortPolicy——抛出异常
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常
3.DiscardPolicy——直接丢弃
该策略下,直接丢弃任务,什么都不做
4.DiscardOldestPolicy——早删晚进
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列
线程池工作流程
线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
当调用 execute() 方法添加一个任务时,线程池会做如下判断:
如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
如果队列满了,而且正在运行的线程数量等于 maximumPoolSize,那么线程池会抛出异常 RejectExecutionException。
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。

5.hashmap是线程安全的吗,为什么
首先HashMap 不是线程安全的。
原因
1.数据结构特性:HashMap 是基于哈希表实现的,它通过哈希函数将键映射到桶中,然后在桶中存储键值对。在多线程环境下,当多个线程同时对同一个 HashMap 进行操作(如插入、删除、更新等)时,可能会导致数据竞争和数据不一致的问题。
2.并发问题:例如,当两个线程同时对同一个键进行更新操作时,可能会出现一个线程的更新操作被另一个线程覆盖的情况。再比如,在进行扩容操作时,如果多个线程同时触发扩容,可能会导致数据丢失或结构损坏。
3.缺乏同步机制:HashMap 的实现并没有内置的同步机制来保证线程安全。虽然可以通过外部同步(如使用 synchronized 块)来实现线程安全,但这并不是 HashMap 本身的特性。
5.1 ConcurrentHashMap是怎么实现线程安全的(如果5回答出,就会出现这个问题)
首先ConcurrentHashMap 是 Java 中的一个线程安全的哈希表实现。
它通过以下几种方式实现线程安全:
1.分段锁(Segment Lock):在早期版本(如 Java 7)中,ConcurrentHashMap 使用分段锁来减少锁的粒度。整个哈希表被划分为多个段(Segment),每个段相当于一个小的哈希表,并且每个段都有自己的锁。当对哈希表进行操作时,只需要锁定相关的段,而不是整个哈希表,从而提高了并发性能。
2.CAS 操作(Compare-And-Swap):在 Java 8 及以后的版本中,ConcurrentHashMap 采用了 CAS 操作和 synchronized 块来实现线程安全。CAS 是一种无锁编程技术,通过比较内存中的值和预期值来决定是否进行更新操作,从而避免了传统锁的开销。
3.锁的优化:ConcurrentHashMap 还对锁进行了优化,例如在某些操作中使用了轻量级锁和偏向锁,进一步提高了性能。
4.多线程协作:在进行一些复杂操作(如扩容)时,ConcurrentHashMap 会采用多线程协作的方式,多个线程可以同时参与操作,从而提高了效率。
6.spring的循环依赖,spring怎么解决的
循环依赖指的是两个类中的属性相互依赖对方:例如 A 类中有 B 属性,B 类中有 A属性,从而形成了一个依赖闭环
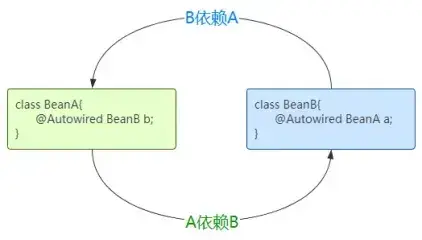
Spring 解决单例模式下的setter循环依赖问题的主要方式是通过三级缓存解决循环依赖。
三级缓存指的是 Spring 在创建 Bean 的过程中,通过三级缓存来缓存正在创建的 Bean,以及已经创建完成的 Bean 实例。
具体步骤如下:
实例化 Bean:Spring 在实例化 Bean 时,会先创建一个空的 Bean 对象,并将其放入一级缓存中。
属性赋值:Spring 开始对 Bean 进行属性赋值,如果发现循环依赖,会将当前 Bean 对象提前暴露给后续需要依赖的 Bean(通过提前暴露的方式解决循环依赖)。
初始化 Bean:完成属性赋值后,Spring 将 Bean 进行初始化,并将其放入二级缓存中。
注入依赖:Spring 继续对 Bean 进行依赖注入,如果发现循环依赖,会从二级缓存中获取已经完成初始化的 Bean 实例。
通过三级缓存的机制,Spring 能够在处理循环依赖时,确保及时暴露正在创建的 Bean 对象,并能够正确地注入已经初始化的 Bean 实例,从而解决循环依赖问题,保证应用程序的正常运行。
7.#{}和${}符号的区别
这个其实就说到了mybatis里面的了
Mybatis 在处理 #{} 时,会创建预编译的 SQL 语句,将 SQL 中的 #{} 替换为 ? 号,在执行 SQL 时会为预编译 SQL 中的占位符(?)赋值,调用 PreparedStatement 的 set 方法来赋值,预编译的 SQL 语句执行效率高,并且可以防止SQL 注入,提供更高的安全性,适合传递参数值。
Mybatis 在处理 ${} 时,只是创建普通的 SQL 语句,然后在执行 SQL 语句时 MyBatis 将参数直接拼入(拼接)到 SQL ,不能防止 SQL 注入,因为参数直接拼接到 SQL 语句中,如果参数未经过验证、过滤,可能会导致安全问题。
8.联合索引在什么
联合索引的实现原理
将多个字段组合成一个索引,该索引就被称为联合索引

联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 product_no 字段比较,在 product_no 相同的情况下再按 name 字段比较。
使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
9.具体好像还有一个我没听清,听了好多遍都还没不知道是啥
感想:
多半可能挂了,内心有点难受,想找一个实现还是有点难的,有点烦,在9号的时候,hr通知我“本周面试的比较多 部门的话会统一面试完之后集中看一看给出结论”,有点希望,但不多,得继续投,并且继续学习了。
想进主要原因还是离学校进不用租房,如果公司在广州,由于学校的新校区附近没有公交、地铁,早上上班比较麻烦。
本文参考
1.线程池原理&常用四大线程池及七大参数https://blog.csdn.net/Carrie_Q/article/details/108696481
2.Spring面试题https://xiaolincoding.com/interview/spring.html#spring

 浙公网安备 33010602011771号
浙公网安备 33010602011771号