
爬虫
import urllib.request url = "https://www.sogou.com/" response = urllib.request.urlopen(url) content = response.read().decode('utf-8') for i in range(20): print(content)
(以下仅为一部分结果截图):
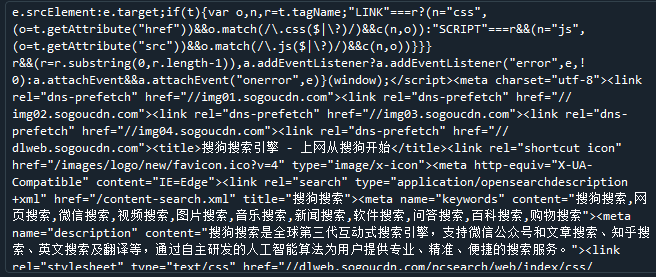
import requests def gethtmltext(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding='utf-8' return len(r.text),len(r.content) except: return "" url="https://www.sogou.com/" print(gethtmltext(url))

(3)
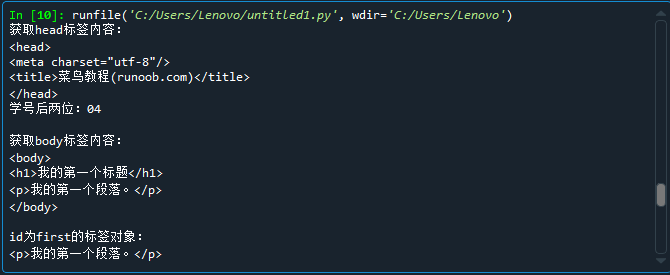
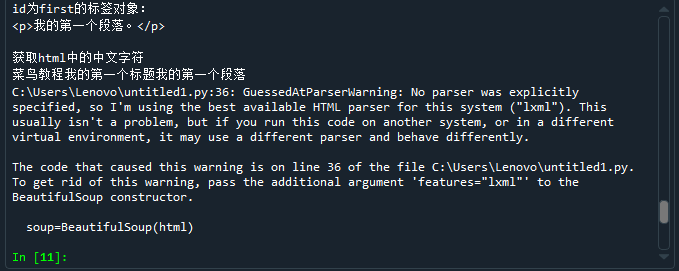
html = '''<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>''' import re def getChinese(html): html_unicode=html.strip() string=re.compile('[^\u4e00-\u9fff]') chinese="".join(string.split(html_unicode)) return chinese from bs4 import BeautifulSoup soup=BeautifulSoup(html) print("获取head标签内容:") print(soup.head) print("学号后两位:04") print() print("获取body标签内容:") print(soup.body) print() print("id为first的标签对象:") print(soup.p) print() print("获取html中的中文字符") print(getChinese(html))
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "" def fillUnivList(ulist,html): soup=BeautifulSoup(html,"html.parser") for tr in soup.find('tbody').children: if isinstance(tr,bs4.element.Tag): tds=tr('td') ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string,tds[4].string]) def printUnivList(ulist,num): print("{0:^10}\t{1:{5}^10}\t{2:{5}^10}\t{3:^10}\t{4:^10}".format("排名","学校名称","省份","总分","生源质量",chr(12288))) for i in range(num): u=ulist[i] print("{0:^10}\t{1:{5}^10}\t{2:{5}^10}\t{3:^10}\t{4:^10}".format(u[0],u[1],u[2],u[3],u[4],chr(12288))) def main(): uinfo=[] url="http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html=getHTMLText(url) fillUnivList(uinfo,html) printUnivList(uinfo,310) main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号