
基于DPDK用户空间的Virtio网络设备驱动设计
1 系统总框架
dpdk
1.概念
数据平面开发工具包,由用于加速在各种CPU架构上运行的数据包处理的库组成
2.优点
基于传统内核的数据传输的弊端:
1.大量的数据包带来频繁的中断
2.频繁的中断带来频繁的上下文切换,带来上下文切换的开销
3.cache miss
4.内核态和用户态的切换
5.局部性失效
6.将容易出错的代码放到用户空间,避免内核崩溃
DPDK在性能上的优化
“旁路内核”
- UIO+mmap实现零拷贝
- UIO+PMD减少中断和CPU上下文切换 驱动屏蔽了硬件发出中断,然后在用户态采用主动轮询的方式。
- HugePages 减少TLB miss
虚拟化
虚拟化是指在一台物理计算机上创建多个虚拟计算环境,每个虚拟环境都可以运行独立的操作系统和应用程序
虚拟化主要分为CPU虚拟化、内存虚拟化和IO虚拟化,本项目主要关注IO虚拟化。
目前,IO虚拟化主要有IO全虚拟化、IO半虚拟化和IO透传三种方式
- IO虚拟化:宿主机KVM截获客户机对IO设备的访问请求,然后用软件QEMU模拟硬件。 无需考虑底层硬件,不需要修改操作系统。但是效率较低。
- IO半虚拟化:让客户机感知到“自己是虚拟机”
好处:全虚拟化IO对模拟设的IO访问都会造成VM-exit,将控制权交给宿主机,这样会带来上下文切换、控制权转移带来的开销和延迟
实现:客户机驱动(前端)<-->宿主机驱动(后端)- IO透传:1.直接将物理设备分配给虚拟机使用,性能最高,但需要物理设备支持;2.这也带来了安全风险、资源的灵活性降低;3.直接绕过了宿主机,不能对其进行防火墙、负载均衡等处理
半虚拟化Virtio
参考:https://tinylab.org/virtio-intro/
https://www.redhat.com/en/blog/introduction-virtio-networking-and-vhost-net
深入浅出DPDK
Virtio-net后端驱动经历了从virtio-net后端,到内核态vhost-net,到用户态vhost-user的过程
1.基本模型

KVM:为程序提供虚拟化硬件的内核模块
- 基于内核的虚拟机。允许Linux充当虚拟机的管理工具,主机可以运行多个隔离的guest环境。
QEMU:利用KVM模拟整个系统的运行环境- 一种托管虚拟机监视器,通过仿真为虚拟机提供不同的硬件和设备模型。客户机通过qemu命令行界面CLI执行。
Libvirt: 为外部管理工具提供虚拟机管理能力- 可将XML格式的配置文件转换为CLI调用的接口。 还提供了一个管理守护进程,来配置子进程,例如qemu。
2.Virtio&&vhost
虚拟网络的实现主要分为控制平面和数据平面
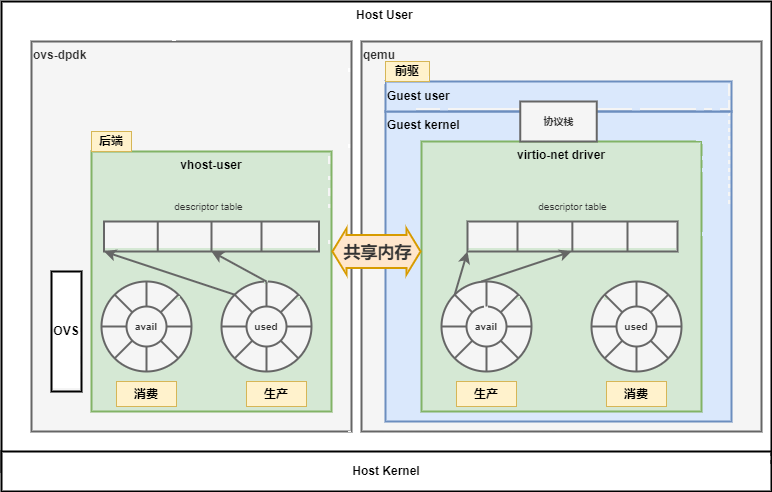
实现:客户机驱动(前端,virtio net)<--虚拟队列(virtqueue)-->宿主机驱动(后端 vhost user)
virtqueue
连接虚拟机前端驱动和宿主机后端驱动的链路

descriptor table:实际要传输的数据
available ring、used ring:记录前端和后端处理描述符的进度

传统双指针法的弊端:只能顺序处理,前面的描述符处理完之前,后面的只能等待
virtio虚拟队列(virtqueue):

设备使用流程:
- 驱动向设备提供数据缓冲区(virtio net driver填充空buffer)
1.把数据缓冲区的地址、长度等信息保存到descriptor table
2.把指向descriptor的指针添加到avail ring
3.更新avail ring的头部指针
4.将virtqueue编号写入queue notify寄存器,通知设备- 设备使用和归还数据缓冲区
1.设备使用缓冲区数据(读取或者写入)
2.把使用过的descriptor table的头指针添加到used ring
3.更新used ring头部指针
4.根据是否开启MSI-X中断,用不同的中断方式通知驱动。
virtio发展历程
1. 最早的架构

通信流程:
1.虚拟机中 virtio-net driver 通过虚拟 PCIE 总线感知到 QEMU 模拟的 virtio-net device,驱动初始化,两者建立控制通道,协商基本能力,虚拟机分配 vring 并与 QEMU 共享。
2.网络发包,虚拟机更新 vring,并通知 KVM, KVM 再通知 QEMU,QEMU 处理待发送的报文
3.网络收包,QEMU 收到报文,填充 vring,通过 KVM 向虚拟机触发虚拟中断,虚拟机完成收包
- 缺点:上下文切换多,报文收发需要在虚拟机/KVM/QEMU 三者间上下文切换
virtio 最初的实现形式,数据平面需要经过 QEMU,效率比较低。然而数据平面的核心操作就是 vring 的通知和前后端填充/提取 vring 的操作。所以,控制平面将 vring 协商好之后,数据平面不需要经过 QEMU.因此,virtio 数据平面可以脱离 QEMU,被‘卸载’到内核或者用户态。
2.内核态vhost
- virtio spec:定义宿主机和虚拟机之间如何创建控制
- vhost:通过将virtio的数据通道卸载到其他地方,提高性能。
数据平面由kernel直接接管。
3.用户态vhost
IO处理模块放在用户态,1.后端通过轮询的方式减少vm-exit带来的开销,2.用户态进程内存共享DPDK,再用户态直接操作网卡,收发数据
优点:1.利用共享内存的技术,减少了virtio-net和vhost之间数据传输的成本;2.IO处理模块全部放在用户态,减轻了Linux内核的工作负担
2 Linux网络栈接收数据
Linux 网络栈接收数据(RX):原理及内核实现(2022) (arthurchiao.art)
硬中断和软中断
什么是硬中断和软中断
根据实现的方式的不同,分为了硬中断和软中断:
- 由 CPU 硬件实现的中断机制,就属于硬中断,比如中断、异常、INT指令都是由 CPU 实现的中断机制。
- 由软件实现实现的中断机制,就属于软中断。比如 Linux 实现的软中断守护进程。
硬中断和软中断区别在于,谁去检测中断事件:
- 硬中断就是 CPU 在每一个指令周期的最后,都会留一个 CPU 周期去查看是否有中断,如果有,就把中断号取出,去「中断向量表」中寻找中断处理程序,然后跳过去执行中断处理程序。
- 软中断就是有一个单独的守护进程,不断轮询一组标志位,如果哪个标志位有值了,那去这个标志位对应的「软中断向量表数组」的相应位置,找到软中断处理函数,然后跳过去执行软中断处理函数。
为什么要有软中断?
硬中断的资源十分宝贵,在处理一个硬中断时,通常会临时关闭其他的中断,在当前的中断处理程序执行完之前就无法处理其他的中断了。
而网络包的收发过程时比较耗时的,如果站着硬中断函数不反悔,会影响其他硬中断的响应,例如鼠标、键盘的操作
Linux的解决方法
Linux 系统为了解决中断处理程序执行过长和中断丢失的问题,将中断过程分成了两个阶段,分别是「上半部和下半部分」(延后中断处理)。
- 上半部用来快速处理中断,主要负责处理跟硬件紧密相关或者时间敏感的事情。
- 下半部用来延迟处理上半部未完成的工作,一般由「内核守护进程」来完成,相当于将中断处理程序比较复杂的逻辑解耦出来了,并通过异步的方式来处理这些复杂的逻辑。
网卡收到网络包后,通过 DMA 方式将接收到的数据写入内存,将网络包的数据写入到内存后,下一步就需要通知内核来处理,于是网卡会触发一个硬中断,内核就会调用网卡的中断处理程序来处理该事件,这个事件的处理会分成上半部和下半部:
- 上部分由硬中断处理程序处理,要做的事情很少,做完后就会发起了一次软中断,然后就结束了。这里发起的软中断,并不是向CPU 发送中断信号,而是将软中断标记数组中的某一个位置标记一下。
- 下半部由软中断处理程序处理,内核守护进程会不断轮询软中断标记数组,看哪个位置被标记为 1 了,接着就去软中断向量表里,寻找这个标志位对应的处理程序,然后执行软中断处理程序处理,其主要是需要从内存中找到网络数据,再按照网络协议栈,对网络数据进行逐层解析和处理,最后把数据送给应用程序。
所以,软中断的作用就是承接原本硬中断处理程序比较复杂且耗时的工作,让硬中断的中断处理函数的逻辑尽可能的简单,从而提高系统的中断响应速度。
Linux 中的三种推迟中断(deferred interrupts):
- softirq
- tasklet
- workqueue
软中断
软中断子系统
软中断是一个内核子系统:
- 每个 CPU 上会初始化一个
ksoftirqd内核线程,负责处理各种类型的 softirq 中断事件 - 软中断事件的 handler 提前注册到 softirq 子系统, 注册方式
open_softirq(softirq_id, handler)
软中断触发的步骤
1.open_softirq()注册软中断处理函数
2.raise_softirq()将一个软中断进行标记
3.当内核调度器调用ksoftirqd线程的时候,处理所有标记的软中断,执行对应的软中断梳理函数softirq handler
Linux 网络栈接收数据
收包过程
1.内核初始化驱动,其中包括注册poll方法
2.网卡收到数据,通过DMA将数据包拷贝到ring buffer当中
3.如果此时NAPI没有在执行,发出硬件中断,通知系统收到了一个包
4.触发软中断,内核调度到软中断处理线程ksoftirqd
5.软中断处理的时候调用NAPI的poll()从ring buffer收包,并以skb的形式交给上层协议栈处理。
网卡驱动初始化
pci_driver->probe()
内核启动过程中,会通过PCI ID来依次识别PCI设备,然后为设备寻找合适的驱动。每个PCI驱动都注册了一个probe方法。
NAPI
内核有一种称为 NAPI(New API)的机制,允许网卡注册自己的 poll() 方法,执行这个方法就会从相应的网卡收包。
网卡收包
网卡是没有处理的(除了近年来出现的只能网卡)。所以到达网卡的数据如果没有进程或者线程来接收,只能被丢弃
收包方式:
- 100%轮询:给网卡预留专门的
- 硬件中断
DPDK的收发包:
1.起初是100%轮询,收发包完全不用任何中断
2.混合中断和轮询的方式:刚开始是轮询,连续多次收到包的个数为0时,应用程序设置了简单的策略决定什么时候进入休眠模式。进入休眠模式以后,如果再次有包收到,产生中断,再次唤醒收包线程,开始轮询地区去收包
sk_buff(skb)
生成一个skb的过程
要想形成一个最终的数据包,即以太帧(不考虑其它的链路层)。要进行以下的操作:
1.分配一个skb结构体
2.分配数据包的数据区
(填充数据载荷、TCP头部、IP头部、MAC头部,但每次填充具体内容之前,都要先将数据区的起始位置进行重定位(skb->data))
3.在skb数据区定位应用层起始位置
4.拷贝数据到应用层(假设应用层协议没有在socket接口之上被封装)
5.在skb数据区定位传输层起始位置
6.设置传输层头部字段
7.在skb数据区定位IP层起始位置
8.设置IP层头部字段
9.在skb数据区定位以太层起始位置
10.设置以太头部字段
四个重要的指针:head,data,tail,end
1.alloc_skb(size) 分配skb
包括申请skb缓冲区和分配skb结构体

2.skb_reserve(m) 初始定位
为头部预留空间 data指针和tail指针往后移动m
3.拷贝应用层数据
1.skb_push(n) 将data指针前移n
2.拷贝应用层数据
4.设置传输层头部 skb_push
5.设置IP层头部
6.设置以太网头部
7.在应用数据后追加padding skb_put
headroom和tailroom:对齐原则需要进行填充、前导码、纠错码、附加信息
skb的分段和分页
分页:使用非线性数据区
非线性区的含义是包含在sk_buff中的数据长度超过了线性数据区所能容纳的界限(一般为一页)。
分页的前提:DMA支持分散-聚集操作
sk_buff数据的总长度存储在len域,非线性数据的长度存储在sk_buff的data_len域。
skb_shared_info: skb_frag_t frags[MAX_SKB_PAGES]做多64kb
分段:主要指IP分段的实现
当一个数据报过长,需要分为多个,形成一个链表
skb_shared_info中:struct sk_buff *frag_list
3 收包
总流程
step1. virtio-net driver填充空buffer:向rxq virtqueue中的descriptor table填充空的descriptor,并更新avail ring的索引
step2. dpdk收包:vhost-user从host侧收包,首先为dpdk的mte_buf从avail ring的可用索引指向的descriptor table找到足够的空间,然后将mbuf中的数据填充进virtqueue的descriptor中,更新used ring的索引,并通知virio-net由有数据到来
step3. kernel收包:virtio-net利用used ring,得到对应的descriptor idx,然后将descriptor中存储的缓冲读取出来,并组装成skb,交付给协议栈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号