
正则表达式
1.什么是正则?
- 正则是一种思维方式。
- 表达对字符串的过滤逻辑。
- 作用:匹配和捕获。
2.基本语法
| [xyz] | 一个字符集,匹配任意一个包含的字符。 | [^xyz] | 一个否定的字符集,匹配任何未包含的字符集。 |
| \w | 匹配字母或数字或者下划线的字符。 | \W | 匹配不是数字,字母。下划线的字符。 |
| \s | 匹配任意空白符 | \S | 匹配不是空白符的字符 |
| \d | 匹配数字 | \D | 匹配非数字的字符 |
| \b | 匹配单词的开始或结束的位置 | \B | 匹配不是单词开始或者结束的位置 |
| ^ | 匹配字符串的开始 | $ | 匹配字符串的结束 |
| . | 匹配除换行符外的任意字符 |
3.RegExp对象
- test():接受一个字符串,在该模式与该参数匹配的情况下返回true。
- exec():接受一个参数,即要应用模式的字符串,然后返回包含第一个匹配项信息的数组或者在没有匹配项的情况下返回null。及时在模式中设置了全局标识(g),它每次也只会返回第一个匹配项。
4.flags:标识
- g:表示全局模式(global)
- i:表示不区分大小写模式(case-insensitive)
- m:表示多行模式(multiline)
5.量词(重复相关的pattern)
| * | 重复0次或更多次 |
| + | 重复1次或更多次 |
| ? | 重复0次或1次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 |
6.分组与捕获
分组又分为捕获型分组()和非捕获型(?:)分组。
捕获型分组:
1 var a = /010101/.exec("20010101"); 2 var b = /(01){3}/.exec("20010101"); 3 var c = /vincent like (music|reading)/.exec('vincent like music'); 4 5 console.log(a); 6 console.log(b); 7 console.log(c);

由于第二个采用了分组,所以调用exec方法后,会默认创建一个捕获01.
非捕获型分组:
1 var d = /(vincent) like (?:music|reading)/.exec('vincent like music'); 2 console.log(d);

由于使用了(?:),所以(?:music|reading)单纯表示或者的效果,并不会产生捕获,所以最后的结果只捕获到了vincent。
引用:
1 var e = /(vincent) like (music|reading)/.exec('vincent like music'); 2 console.log(e,RegExp.$1,RegExp.$2);

上式中分别有两个捕获vincnet和music。我们可以用e[1]和e[2]或者RegExp.$1和RegExp.$2来引用它们。
反向引用:
1 var reg1 = /<div>.*<\/div>/; 2 console.log(reg1.test("<div>abcdefg</div>"));
1 var reg2 = /<(div)>.*<\/\1>/; 2 console.log(reg2.test("<div>abcdefg</div>"));
上式中reg1与reg2表示相同意思。reg2将(div)设置成一个分组,并在后面用\1来引用它。
7.贪婪匹配和惰性匹配
贪婪(greedy)匹配:普通量词
1 var str = "<span>hello</span><span>world</span>"; 2 var reg = /<(span)>.+<\/\1>/; 3 console.log(reg.exec(str));

贪婪匹配:尽可能多的匹配
惰性(lazy)匹配:普通量词加?
- 又称非贪婪匹配(non-greedy)
1 var str = "<span>hello</span><span>world</span>"; 2 var reg = /<(span)>.+?<\/\1>/; 3 console.log(reg.exec(str));

惰性匹配:尽可能少的匹配
8.正向前瞻(?=)和负向前瞻(?!)
/kxx(?= like music)/ look ahead position assert 正向前瞻
/kxx(?! like reading)/ look ahead negative assert 负向前瞻
/(?= like music)/ 匹配位置 零宽断言
/(?! like reading)/ 负向零宽断言
正向前瞻(?=):匹配后面跟随指定的字符的字符。
负向前瞻(?!):匹配后面不跟随指定的字符的字符。
1 var reg1 = /kxx(?=\slike\smusic)/g; 2 var reg2 = /kxx(?!\slike\sreading)/g; 3 var str = "kxx like music kxx like reading kxx like music kxx like swimming"; 4 5 console.log(str.match(reg1)); 6 console.log(str.match(reg2));
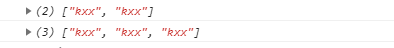
注:如果正则中有空格,尽量用\s代替。
实例:匹配字符串中所有jpg图片
1 var str = "img.jpg style.css script.js hello.jpg"; 2 var reg = /\b(\w+)(?=\.jpg)\b/g; 3 console.log(str.match(reg));

9.String能使用正则的方法
- replace()
- match():捕获所有分组(exec只能捕获第一个分组)
- split()
- search()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号