
spring-data-JPA:SQL/规定方法名/QueryByExample/Specifications/QueryDSL的快速入门
1.自定义jpql
查询,如果是select * 则可以省略这部分,直接从from开始
参数有两种设置方式:
1.通过?+索引设置参数
@Query("from Customer where custName = ?1")
Customer findByCustName(String custName);
2.通过@param注解与 :name 设置参数
@Query("from Customer where custName = :custName")
Customer findByCustName(@Param("custName") String custName);
此外还可以使用原生sql直接插,但是需要额外参数nativeQuery,例如:
@Query(value = "select * from tb_customer where cust_name = ?1",nativeQuery = true)
Customer findBySql(String custName);
删改:参数设置同查找,此外要有事务支持,要有@Transactional(一般放在业务逻辑层)与@Modifying
如果不加@modifying,会有以下报错
org.springframework.dao.InvalidDataAccessApiUsageException: org.hibernate.hql.internal.QueryExecutionRequestException: Not supported for DML operations
正确写法如下
@Transactional//应该放在业务逻辑层
@Modifying//标注当前方法是增删改,jpa会实现自动刷新与自动擦除
@Query("update Customer set custName = :custName where custId = :custId")
void updateCustomerByCustId(@Param("custId") Integer custId, @Param("custName") String custName);
增:jpql不支持插入,不过本来的save、saveAll方法也够用了
2.JPA中的规定方法
主题关键字+谓词关键字
主题关键字(前缀):只支持查和删,这里的删也要在事务的控制内,不然会报错
find...By、count...By、remove...By(delete...By)、exist...By:很常见的见文知意
...First<number>... ( ...top<number>...) , ...distinct... 这个一般就是插入到上面的省略号中,
谓词关键字:
and、or:举例:findByNameAndAge 即 where name=?1 and age=?2
is、equals平时就是省略的,上述例子就是,如果写全就是findByNameIsAndAgeIs或findByNameEqualsAndAgeEquals
between、lessThan、lessThanEqual:举例:findByStartDateBetween 即 where startDate between ?1 and ?2
isNull/null、isNotNull、notNull、orderBy 举例为:findByNameIsNull
like 需要自己在程序中拼好%%, findByNameLike 即 where name like ?1,这里我们需要给?1拼好数据
in 需要传入一个集合 findByAge(Collection<ages> collect)
true/false 条件判断,给boolean用
如果删除不加事务会有以下报错:
org.springframework.dao.InvalidDataAccessApiUsageException: No EntityManager with actual transaction available for current thread -
cannot reliably process 'remove' call; nested exception is javax.persistence.TransactionRequiredException:
No EntityManager with actual transaction available for current thread - cannot reliably process 'remove' call
3.queryByExample
只支持字符串 查询,不支持嵌套查和分组查,局限性比较多,有number、date、json这种都查不了
extends PagingAndSortingRepository<T, ID> ,QueryByExampleExecutor<T>
挺简单的,但是这个东西挺鸡肋的
示例代码:
public void testQBEFindAll(){ // 构建查询条件 Customer customer=new Customer(); customer.setCustName("Slark"); // 设置匹配器,控制条件 ExampleMatcher matcher = ExampleMatcher.matching() .withIgnorePaths("custId")//忽略custId字段 .withStringMatcher(ExampleMatcher.StringMatcher.CONTAINING)//包含,此外还有左匹配、右匹配。 // 注意,上面是对所有条件进行模糊匹配 .withMatcher("custName",c->c.contains())//对custName字段进行模糊匹配 .withIgnoreCase()//忽略大小写,可以指定参数,不指定参数即所有字段都忽略大小写 // 这里实际是对列使用了lower函数,可能会引起索引失效 ; // 放入example中 Example<Customer> customerExample = Example.of(customer); // 返回结果 List<Customer> all = customerRepository.findAll(customerExample); }
4.Specifications
extends PagingAndSortingRepository<T, ID> ,JpaSpecificationExecutor<T>
基础样例:
public void testFindAll() { customerRepository.findAll(new Specification<Customer>() { @Override public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) { // root 即要查询的根对象,从root中获取列元素 Path<Integer> custId = root.get("custId"); Path<String> custName = root.get("custName"); // criteriaBuilder 即条件构造器,通过criteriaBuilder来设置条件 // 参数1为root中获取的字段,参数2为需要查的值 Predicate equal = criteriaBuilder.equal(custId, 2); Predicate like = criteriaBuilder.like(custName, "Slark"); CriteriaBuilder.In<Integer> in = criteriaBuilder.in(custId).value(1).value(2).value(3); // 拼接条件 Predicate and = criteriaBuilder.and(equal, like, in); // query 即查询对象,通过query来组合查询条件 Order desc = criteriaBuilder.desc(custId); Predicate restriction = query.where(and).orderBy(desc).getRestriction(); return and; // 如果使用了query,不过query只能使用where和orderBy。这时返回restriction } }); }
使用样例:
public void testFindAll2(Customer customer) { List<Customer> all = customerRepository.findAll(new Specification<Customer>() { @Override public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) { List<Predicate> predicates = new ArrayList<>(); if (customer.getCustId() != null) { predicates.add(criteriaBuilder.equal(root.get("custId"), customer.getCustId())); } if (customer.getCustName() != null) { predicates.add(criteriaBuilder.like(root.get("custName"), customer.getCustName())); } Predicate and = criteriaBuilder.and(predicates.toArray(new Predicate[0])); return and; } }); }
5.QueryDSL
引入新依赖
<dependency> <groupId>com.querydsl</groupId> <artifactId>querydsl-jpa</artifactId> <version>4.4.0</version> </dependency>
extends PagingAndSortingRepository<T, ID> , QueryPredicateExecutor<T>
这里查询需要新的Q实体类,还需要引入额外的maven插件
<plugin> <groupId>com.mysema.maven</groupId> <artifactId>apt-maven-plugin</artifactId> <version>1.1.3</version> <dependencies> <dependency> <groupId>com.querydsl</groupId> <artifactId>querydsl-apt</artifactId> <version>4.4.0</version> </dependency> </dependencies> <executions> <execution> <goals> <goal>process</goal> </goals> <configuration> <outputDirectory>target/generated-sources/java</outputDirectory> <processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor> </configuration> </execution> </executions> </plugin>
引入插件成功之后需要先手动编译程序,这里apt通过@entity生成对应对象的q类在target目录中,生成完成后,需要检查其目录下对应的文件,将其设置为源文件(如果在idea中,显示为蓝色的文件夹,那就是没问题。如果配置不当,那就是正常的黄色文件夹)设置如下图,将excluded改为sources
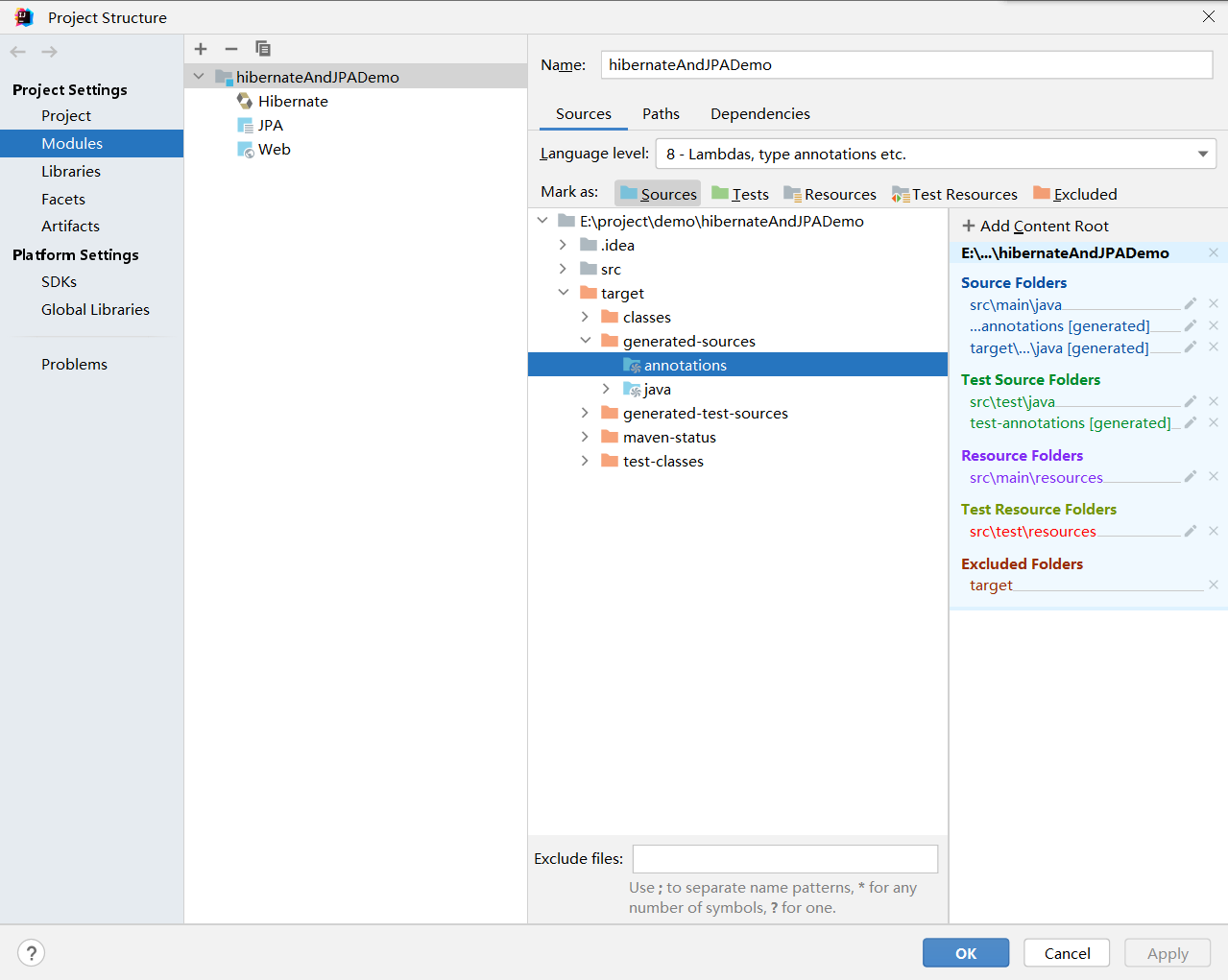
这个时候就能正常使用queryDSL+JPA了,实际使用起来很像mybatis-plus...但是明显用着比mp复杂不少,下面是一个小栗子:个人感觉其实这里的booleanExpression就是mp里的queryWrapper
public void test(){ QCustomer qCustomer=QCustomer.customer; BooleanExpression eq = qCustomer.custId .eq(1) .and(qCustomer.custName.eq("slark")); repository.findOne(eq); }
动态查询:同样,需要判空然后引入数据
public void test2(List<Customer>customers){ List<Integer> collect = customers.stream().map(Customer::getCustId).collect(Collectors.toList()); QCustomer qCustomer=QCustomer.customer; // 初始条件,类似于1=1,保证查询能走下去 BooleanExpression expression = qCustomer.isNotNull().or(qCustomer.isNull()); // 添加查询条件 expression = !collect.isEmpty()?expression.and(qCustomer.custId.in(collect)):expression; repository.findAll(expression); }
使用entityManager+queryDSL
这个主要是为了解决一些聚合查询、分组查询的问题,因为repository在生成的时候就会生成好对应的列等信息
栗子如下,这里em头顶上的注解是专门为entityManager服务的,他用于在依赖注入的情况下,保证em的线程安全问题
@PersistenceContext
EntityManager entityManager;
@Test
public void test3() {
JPAQueryFactory factory = new JPAQueryFactory(entityManager);
QCustomer qCustomer = QCustomer.customer;
List<Tuple> fetch = factory.select(qCustomer.custId.sum(), qCustomer.custName)
.from(qCustomer)
.where(qCustomer.custId.eq(1))
.groupBy(qCustomer.custName)
.fetch();
for (Tuple tuple : fetch) {
tuple.get(qCustomer.custId.sum());
tuple.get(qCustomer.custName);
}
}
上面的tuple类实际是一个数组,里面存放类似KV的对应关系(在select中决定),并且他也会在你select一个完整类、仅select sum、cnt时自动转换成对应的class
最后总结一下:
- 使用原生SQL时,删改要记得加上注解;
- 规定方法名的方法只支持删改
- queryByExample最好是对单对象查询,直接传对象方便快捷
- specifications写起来很复杂,但是我公司用的就是这个,封装了一个好的类使用很方便,只需要传对应的map即可,感觉很厉害
- queryDSL使用类似MP,但是又需要在maven中额外插件,又得先编译再运行,不知道在gradle中行不行。
- 想要写一些特定的,sum、cnt、groupBy,JPA自带框架不支持,只能手搓一下EntityManager再写。
- 一定一定要记得加事务,jpa对事务要求还是比较高的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号