
Redis基础数据结构——skipList
skipList(跳表)一种支持二分查找的链表,结构简单并且性能不亚于红黑树
与传统链表不同的是:
节点包含多个指针,指针的跨度不同,指针层级越高,跨度越大
元素按照升序排列存储:节点安装score值排序,score值一样则按元素排序
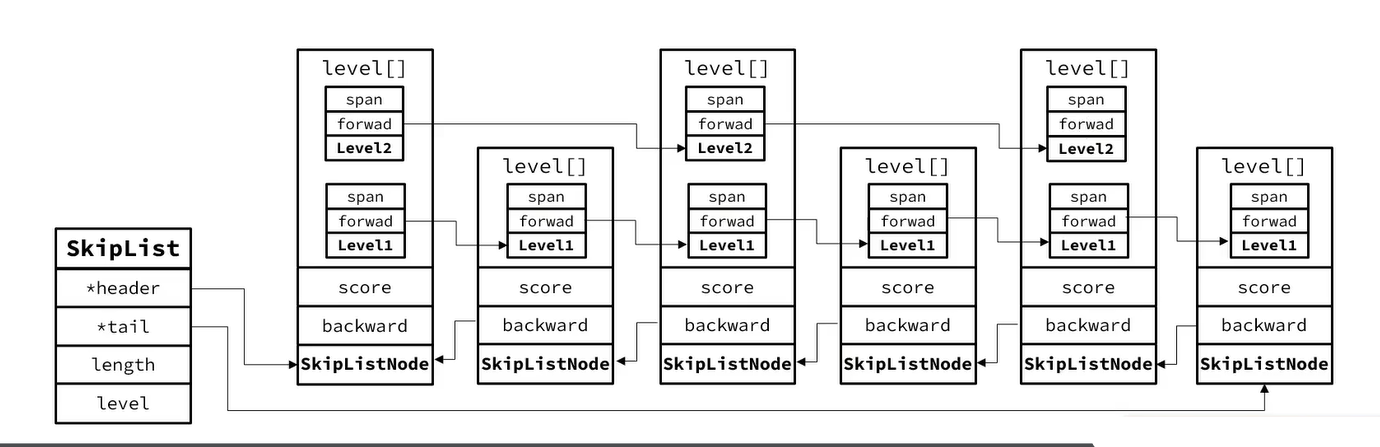
在翻阅源码的时候,我发现没有像之前的源码一样有个专门为skiplist生成的skiplist.c和skiplist.h,全局搜索之后才发现原来skiplist只存在于server.h(定义)和t_zet.c中。
skiplist的数据结构
/* ZSETs use a specialized version of Skiplists */ typedef struct zskiplistNode { sds ele;//元素内容 double score;//排序依据 struct zskiplistNode *backward;//前驱指针(固定执行前一个,因此不需要多个) struct zskiplistLevel {//后驱指针数组 struct zskiplistNode *forward;//指针 unsigned long span;//指针的层级 } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;
注释写:zset使用的一种特殊版本的skiplist,也就是说:skiplist是专门为优化zset用的,并不是独立的数据结构。
skiplist的插入
逻辑:
1.先在每层查找查找一下当前节点要插入的位置(小于当前score的,后置score相同ele更小的节点,记作update[i],并设置当前span)
2.随机生成新节点层高,如果新层高大于当前最大,则覆盖skiplist的level
3.创建新节点,由于前面记录了每层的前驱节点,因此只需要根据前驱节点插入到对应的位置即可
4.未插入的节点的层,直接更新span(跨度)+1
5.如果新节点不是最后一个,则将后继节点的前驱指针指上;如果新节点是最后一个,更新尾指针*tail
/* Insert a new node in the skiplist. Assumes the element does not already * exist (up to the caller to enforce that). The skiplist takes ownership * of the passed SDS string 'ele'. */ zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; unsigned long rank[ZSKIPLIST_MAXLEVEL]; int i, level; serverAssert(!isnan(score)); x = zsl->header; for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span; x = x->level[i].forward; } update[i] = x; } /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. */ level = zslRandomLevel(); if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } zsl->level = level; } x = zslCreateNode(level,score,ele); for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; } /* increment span for untouched levels */ for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; } x->backward = (update[0] == zsl->header) ? NULL : update[0]; if (x->level[0].forward) x->level[0].forward->backward = x; else zsl->tail = x; zsl->length++; return x; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号