
redis基础数据结构——dict
关于哈希:
哈希表是一种提高效率的数据结构,每当我们插入元素时,会根据key的hash值来决定他进入表的哪一槽位。为了保证均匀分布数据,有了下述公式
index = hash(key) & (size - 1)
在一般情况下,size要求为2的幂。因为原本的公式是hash(key)%size。而使用&的优势是效率更高。
Dict字典
dict主要由三部分组成dict(字典本身)、dictht ( dict hashtable,类似于java中的hashtable)、dictEntry(即table中的entry)
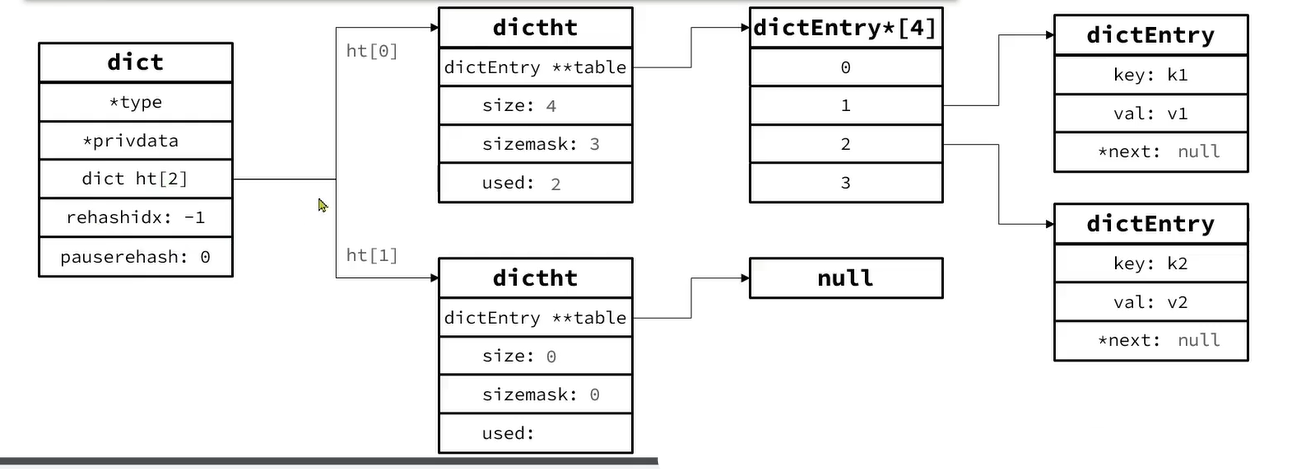
dictEntry
struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; /* Next entry in the same hash bucket. */ };
- 在C语言中,union是一种特殊数据类型,允许同一位置存储不同的数据类型。但只能存储其成员中的一个值
- 其中void *val是一个通用指针,可以指向任何类型的数据;
- uint64和int64分别代表无符号64位整数类型与有符号64位整数类型。
- 关于为什么union中没有包含SDS:在redis的实现中通常通过void*来引用SDS,直接将其嵌入到union中会导致内存浪费。
- *next即同一个hash(key)在table中的下一个entry
在这个hashtable中,使用的是头插法(类似于jdk7,jdk8中改用了尾插法)
- jdk8改用尾插法的最大原因是为了解决多线程下头插法可能会导致链表成环的问题;而redis是单线程的,不会出现这种问题
- 头插法时间复杂度是O(1),而且不需要遍历到链表尾
- 头插法相对来说更简单
dictht
这一部分不管是我看redis6.0的源码还是在github上看最新的源码,都已经没有dictht的定义。现在这个结构体都被嵌入到了dict中,并且删除了sizemask
typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask;//这个就是size-1,用于方便计算hash(key)&(size-1) unsigned long used; } dictht;
dict
struct dict { dictType *type; dictEntry **ht_table[2];//取代了原本的dictht,直接嵌入了dictEntry。这里的**是指指向entry数组的指针 unsigned long ht_used[2];//这里是原本dictht的used,表示哈希表中已经存在的节点数量,由于哈希冲突的问题,节点数量是可能大于size的 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned pauserehash : 15; /* If >0 rehashing is paused */ unsigned useStoredKeyApi : 1; /* See comment of storedHashFunction above */ signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) 哈希表的指数大小,2的幂。sizemask即 (1 << exp) - 1 */ int16_t pauseAutoResize; /* If >0 automatic resizing is disallowed (<0 indicates coding error) */ void *metadata[]; };
类似于hashmap中的容量与负载因子,dict中也有类似的机制。负载因子LoadFactor=used/size。
通常有两种情况会发生扩容:
- loadfactor >= 1,并且服务器没有执行bgsave或bgrewriteaof时;
- loadfactor > 5时
关于检测扩容与创建
int dictExpandIfNeeded(dict *d) {
//如果正在rehash,直接返回
if (dictIsRehashing(d)) return DICT_OK;
//如果是首次使用dict,直接
if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) {
//#define DICT_HT_INITIAL_EXP 2
//#define DICT_HT_INITIAL_SIZE (1<<(DICT_HT_INITIAL_EXP))
dictExpand(d, DICT_HT_INITIAL_SIZE);
return DICT_OK;
}
//如果可以resize并且used/size>=1或者不可以resize,但是used/size>5
if ((dict_can_resize == DICT_RESIZE_ENABLE &&
d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0])) ||
(dict_can_resize != DICT_RESIZE_FORBID &&
d->ht_used[0] >= dict_force_resize_ratio * DICTHT_SIZE(d->ht_size_exp[0])))
{
//used变成+1,实际上是扩容函数是找大于等于当前数的2的幂,即扩容一倍
if (dictTypeResizeAllowed(d, d->ht_used[0] + 1))
dictExpand(d, d->ht_used[0] + 1);
return DICT_OK;
}
return DICT_ERR;
}
关于收缩:代码类似于上述,要求负载因子<0.1且size>4。如果size<4,那也会重置到4。
代码块不在dict.c里,具体在哪里全文搜索搜不到,这里是黑马讲的结论。
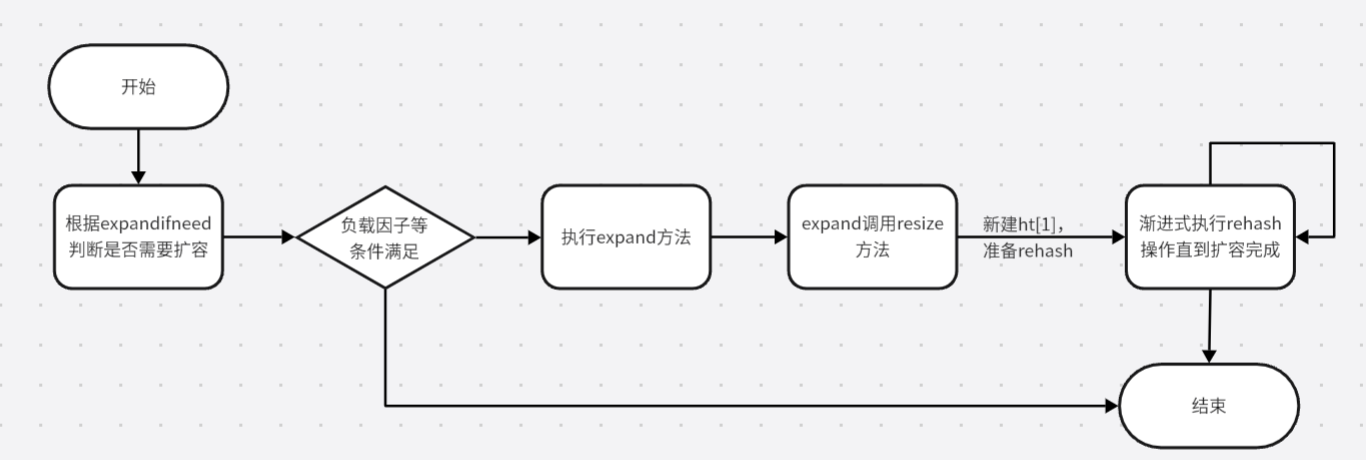
如果检测扩容/收缩成立,那么就会执行expand方法,而expand方法内主要是通过执行resize方法实现调整table大小
关于创建或者调整table大小:
int _dictResize(dict *d, unsigned long size, int* malloc_failed) { if (malloc_failed) *malloc_failed = 0; //如果已经在rehash,断言失败并返回 assert(!dictIsRehashing(d)); //声明一个新的hashtable,用于存储新的data dictEntry **new_ht_table; unsigned long new_ht_used; signed char new_ht_size_exp = _dictNextExp(size); // 健壮性判断:如果newsize超过最大值,报错 Detect overflows size_t newsize = DICTHT_SIZE(new_ht_size_exp); if (newsize < size || newsize * sizeof(dictEntry*) < newsize) return DICT_ERR; // newsize和原来的一样,没意义,直接返回错误 if (new_ht_size_exp == d->ht_size_exp[0]) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ if (malloc_failed) { new_ht_table = ztrycalloc(newsize*sizeof(dictEntry*)); *malloc_failed = new_ht_table == NULL; if (*malloc_failed) return DICT_ERR; } else//给new ht分配空间 new_ht_table = zcalloc(newsize*sizeof(dictEntry*)); new_ht_used = 0; //准备使用ht[1],将新的ht赋值给ht[1],将dict中的rehashidx置0,表示开始rehash d->ht_size_exp[1] = new_ht_size_exp; d->ht_used[1] = new_ht_used; d->ht_table[1] = new_ht_table; d->rehashidx = 0; if (d->type->rehashingStarted) d->type->rehashingStarted(d); //如果是在初始化,不需要rehash,直接给ht[0]赋值 if (d->ht_table[0] == NULL || d->ht_used[0] == 0) { if (d->type->rehashingCompleted) d->type->rehashingCompleted(d); if (d->ht_table[0]) zfree(d->ht_table[0]); d->ht_size_exp[0] = new_ht_size_exp; d->ht_used[0] = new_ht_used; d->ht_table[0] = new_ht_table; _dictReset(d, 1); d->rehashidx = -1; return DICT_OK; } /* Force a full rehashing of the dictionary */ if (d->type->force_full_rehash) { while (dictRehash(d, 1000)) { /* Continue rehashing */ } } return DICT_OK; }
rehash流程:
不论是扩容还是收缩都需要创建一个新的hash表(因为size发生了变化,key的查询也会发生变化,因此每个key都需要重新计算索引)
- 首先是计算新hash表的size
- 如果是扩容,则根据ht[0].used+1算出当前的容量,2的n次方+1(一般来说就是翻倍)
- 如果是收缩,则根据ht[0].used算出当前容量,2的n次方(假设现在有14个元素,那么容量就应该在16,但是无论如何小于4)
- 按新的size申请内存空间,将新创建的ht赋值给ht[1],并将dict的rehashidx从-1设置为0,标志开始rehash
- 为了防止太多数据阻塞住主线程,因此不能一次性的将数据推入ht[0],这就是渐进式rehash:
- 每次做增删改查的时候,会检查一下idx是否为-1,不为-1则将下标对应的entry连到ht[1]中。然后idx++,直至ht[0]内没有数据
- 当ht[0]索引迁移完毕后,清除ht[0]的内存空间;并将ht[1]设置为ht[0],重新让ht[1]变回null。最后再将rehashidx置为-1表示size变更结束
在迁移过程中每次做增删改查,都会引起一个数据的迁移。因此每次做删改查时都需要遍历ht[0]和ht[1]来确保结果准确,而新增则是直接将数据插入到ht[1]
rehash源码:
/* 执行N步渐进式rehash操作。 * 如果还有键需要从旧哈希表移动到新哈希表,则返回1,否则返回0。 * * 注意:每一步rehash操作会将一个桶(可能包含多个键,因为我们使用链式哈希)从旧哈希表移动到新哈希表。 * 但由于哈希表可能包含空桶,因此不能保证每次调用都会rehash一个桶。 * 为了避免函数阻塞过长时间,最多只会访问N*10个空桶。 */ int dictRehash(dict *d, int n) { int empty_visits = n*10; //最多允许访问空桶的数量 unsigned long s0 = DICTHT_SIZE(d->ht_size_exp[0]); unsigned long s1 = DICTHT_SIZE(d->ht_size_exp[1]); if (dict_can_resize == DICT_RESIZE_FORBID || !dictIsRehashing(d)) return 0; // DICT_can_resize有三种值:AVOID尽量避免调整;ALLOW允许调整;FORBID禁止调整 /* s1是ht[0]的size,s2是nt[1]的size;当s1>s2时,表示正在收缩;反之则是扩容 */ /* If dict_can_resize is DICT_RESIZE_AVOID, we want to avoid rehashing. * - If expanding, the threshold is dict_force_resize_ratio which is 4. * - If shrinking, the threshold is 1 / (HASHTABLE_MIN_FILL * dict_force_resize_ratio) which is 1/32. */ //使用avoid即尽量避免rehash,需要让s1/s0的值超过一定阈值才可以进行。否则直接返回0,即告知不需要rehash if (dict_can_resize == DICT_RESIZE_AVOID && ((s1 > s0 && s1 < dict_force_resize_ratio * s0) || (s1 < s0 && s0 < HASHTABLE_MIN_FILL * dict_force_resize_ratio * s1))) { return 0; } //执行第n步rehash,直到旧表内的数据都被移走 while(n-- && d->ht_used[0] != 0) { /* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(DICTHT_SIZE(d->ht_size_exp[0]) > (unsigned long)d->rehashidx); while(d->ht_table[0][d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } /* 将当前桶内的键移到ht[1]中 */ rehashEntriesInBucketAtIndex(d, d->rehashidx); d->rehashidx++; } //检测是否完成rehash,完成则返回1,未完成仍需继续则返回0 return !dictCheckRehashingCompleted(d); }
总体来说流程如下图(个人理解,可能有误,欢迎指正)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号