
MySQL优化-explain:字段,索引相同的多个数据库为什么他们的type,key,key_len会不一样
实习倒数第二天,偶然间查了查自己的写的sql语句性能有没有问题。
select COL1,COL2,COL3 from inf_log where CODE ='AAA' and ORDER_ID='123456';
上述字段中,code与order_id都被设置为索引IDX_MIAN_ID,IDX_CODE。也就是说,正常情况下这两个索引应该是都会命中
公司实现了表的水平分片把inf_log分成了20+个表。
explain select COL1,COL2,COL3 from inf_log where CODE ='AAA' and ORDER_ID='123456';
而查出来的结果却显示,只有一个表是命中两个索引的,其余的都只是命中了一个索引,百思不得其解。
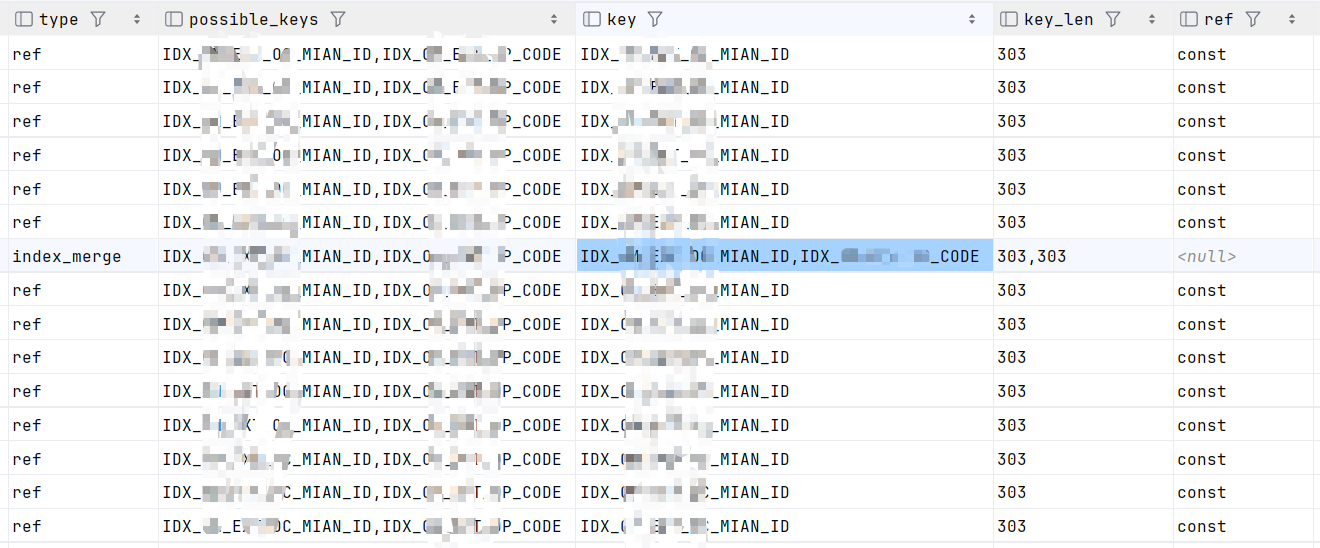
explain select COL1,COL2,COL3 from inf_log
通过上述sql我发现这个命中两个索引的表的数据量远高于其他表的数据量:其他表的rows最多是千位级别,而这个命中两个索引的表row为十万级别
也就是说,正常情况下(可能是当数据量正常的时候),MySQL的查询优化器会取用单个索引搜索就够了;而特殊情况(当数据量达到一定量时),MySQL的查询优化器会认为索引合并(index_merge)的查询更有效进而选择更多key,将type从type由普通索引ref改为索引合并index_merge。
注意,我们在设计索引时应该尽量避免index_merge,这样会需要额外的优化与计算,还会增加IO开销。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号