
elasticsearch初步使用学习
通过使用elasticsearch,我们可以加快搜索时间(直接使用SQL的模糊查询搜索耗时会比较久,而且elasticsearch的响应耗时与数据量关系不大)
es主要用于存储,计算,搜索数据
依次部署elasticsearch,kibana
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
参数说明9200为访问端口,9300为集群端口
- 第一个环境表示es的最大最小内存,不能低于512
- 第二个环境表示当前是单节点模式
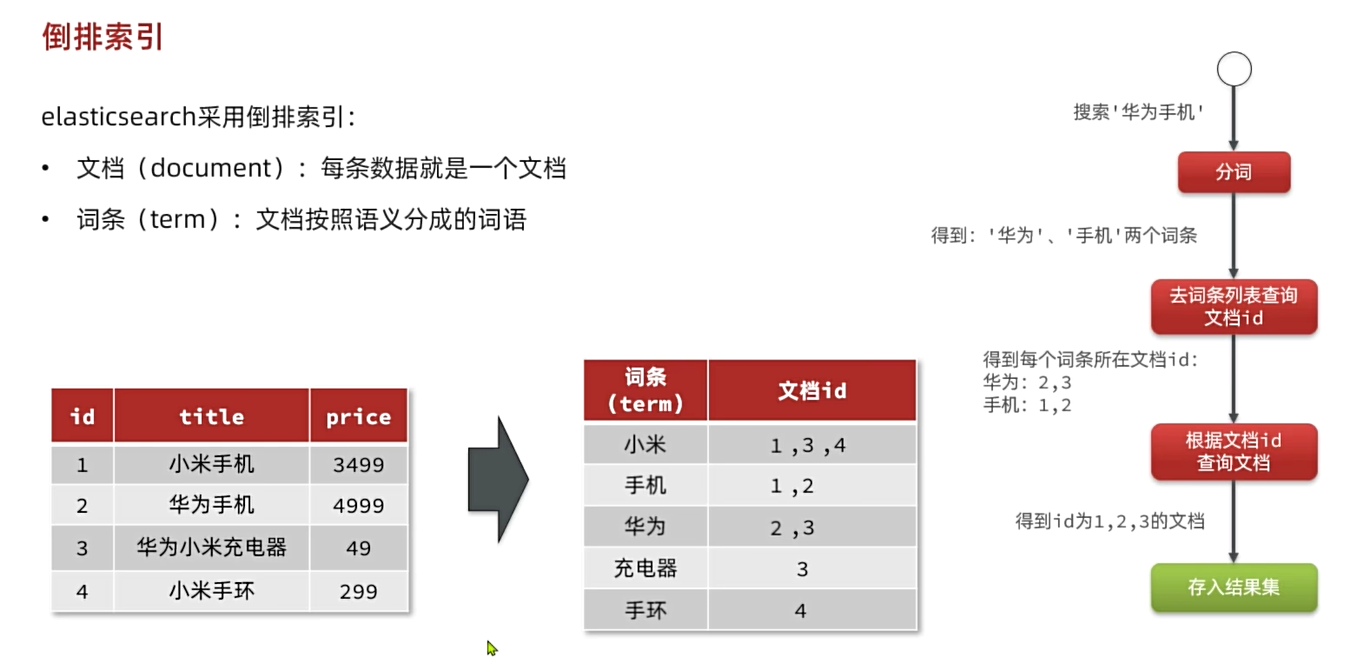
倒排索引:
文档document:每一条数据就是一个文档
词条term:文档按语义分成的词语
索引index:相同类的文档集中在一起
对文档内容分词,对词条建立索引,并记录词条所在文档的id
查询的时候根据词条查询文档id,再根据文档id查询文档
mySQL es
table index
row document
column field
schema mapping mapping是索引中文档的约束
SQL DSL DSL是es提供的json风格请求语句,实现CRUD
IK分词器:
smart智能切分,粗粒度
max_word最细切分,细粒度
POST /_analyze
{
"analyzer": "ik_max_word",// "ik_smart"
"text": "天津市长江大桥"
}
如何拓展IK分词器的词典
修改IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--> <entry key="ext_dict">ext.dic</entry> </properties>
在config中新建一个ext.dic
市长
江大桥
mapping映射属性:
type:字段数据类型,
常见数据类型:
- 字符串text(这个是可以分词的)keyword(这个是精确值,不可进行分词)
- 数值:long,double,integer,float,byte,short
- 布尔boolean
- 日期date
- 对象object
index:是否创建索引,默认是true
analyzer:使用那种分词器(一般只有text需要指定这个)
properties:(该字段的子字段,一般是给object用的)
索引库操作:对应SQL中的table操作
# 创建索引库样例
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
# 查询样例
GET /heima
# 删除样例
DELETE /heima
# 修改样例
PUT /heima/_mapping
{
"properties":{
"age":{
"type": "byte"
}
}
}
文档操作:对应SQL中对column的操作
# 文档操作:新增
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
# 文档操作:查询
GET /heima/_doc/1
# 文档操作:删除
DELETE /heima/_doc/1
# 文档操作:修改 1.全量修改(先删除旧文档,再新增新文档)
PUT /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "子龙",
"lastName": "赵"
}
}
# 文档操作:修改 2.局部修改
POST /heima/_update/1
{
"doc": {
"info": "黑马程序员的Java讲师"
}
}
批处理文档:注意这里不能格式化,必须写在一行上,不然就会报错而且操作失败
# 文档批处理 新增
POST /_bulk
{"index":{"_index":"heima","_id":"3"}}
{"info":"黑马程序员C++讲师","email":"ww@itcast.cn","name":{"firstName":"五","lastName":"王"}}
{"index":{"_index":"heima","_id":"4"}}
{"info":"黑马程序员前端讲师","email":"zhangsan@itcast.cn","name":{"firstName":"三","lastName":"张"}}
# 文档批处理 删除
POST /_bulk
{"delete":{"_index":"heima","_id":"3"}}
{"delete":{"_index":"heima","_id":"4"}}
# 文档批处理 更新
POST /_bulk
{"update":{"_index":"heima","_id":"3"}}
{"doc":{"info":"黑马程序员C艹讲师"}}
{"update":{"_index":"heima","_id":"4"}}
{"doc":{"info":"黑马程序员非后端讲师"}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号