TCP是如何保证可靠传输的?
为了实现可靠性传输,需要考虑很多事情,例如数据的破坏、丢包、 重复以及分片顺序混乱等问题。如不能解决这些问题,也就无从谈起可靠传输。
重传机制
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
TCP 针对数据包丢失的情况,会用重传机制解决。

2.快速重传
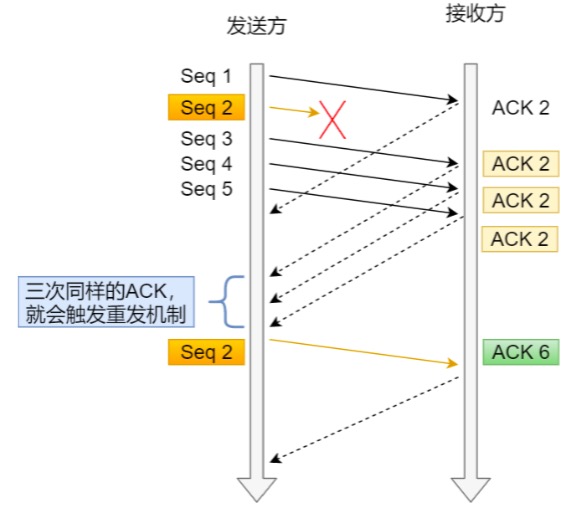
第一份 Seq1 先送到了,于是就 Ack 返回 2;
结果 Seq2 因为某些原因没收到,Seq3 到达了,于是还是 Ack 回 2;
后面的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;
发送端收到了三个 Ack = 2 的确认,知道了 Seq2 还没有收到,就会在定时器过期之前,重传丢失的 Seq2。
最后,收到了 Seq2,此时因为 Seq3,Seq4,Seq5 都收到了,于是 Ack 回 6 。
所以,快速 重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前, 重传丢失的报文段。
根据 TCP 不同的实现,以上两种情况都是有可能的。可⻅,这是一把双刃剑。 为了解决不知道该 传哪些 TCP 报文,于是就有 SACK 方法。
3.SACK
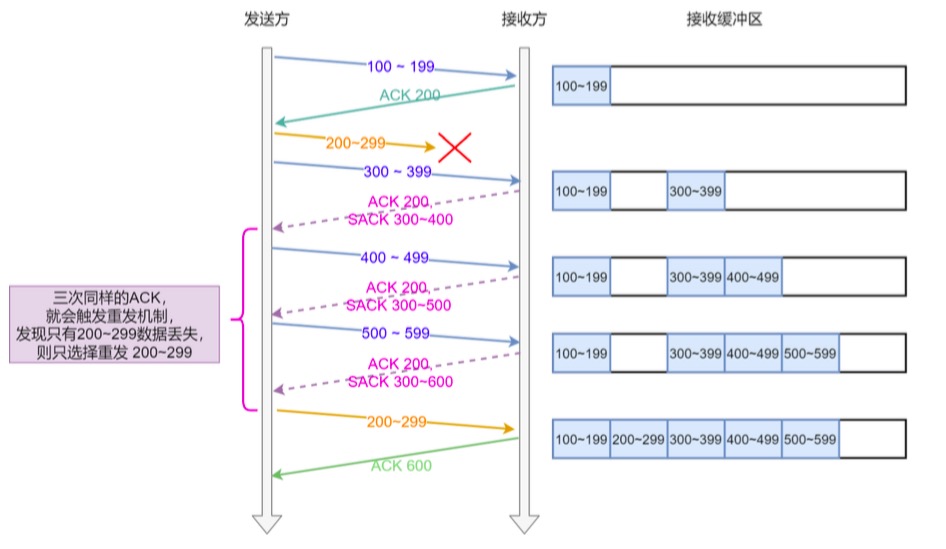
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东⻄,它可以将缓存的地图发送给发送方,这样发送 方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
如下图,发送方收到了三次同样的 ACK 确认报文,于是就会触发快速 重发机制,通过 SACK 信息发现只有 200~299 这段数据丢失,则 发时,就只选择了这个 TCP 段进行重复。
4.Duplicate SACK
滑动窗口
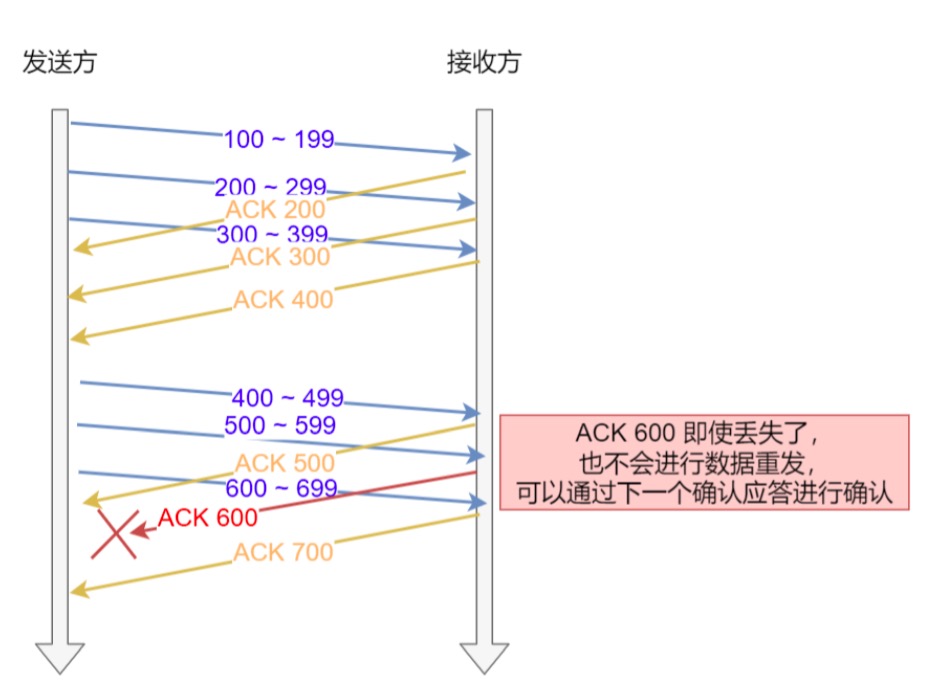
假设窗口大小为 3 个 TCP 段,那么发送方就可以「连续发送」 3 个 TCP 段,并且中途若有 ACK 丢失,可以 通过「下一个确认应答进行确认」。如下图:
TCP 头里有一个字段叫 Window ,也就是窗口大小。 这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收
端处理不过来。所以,通常窗口的大小是由接收方的窗口大小来决定的。发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。
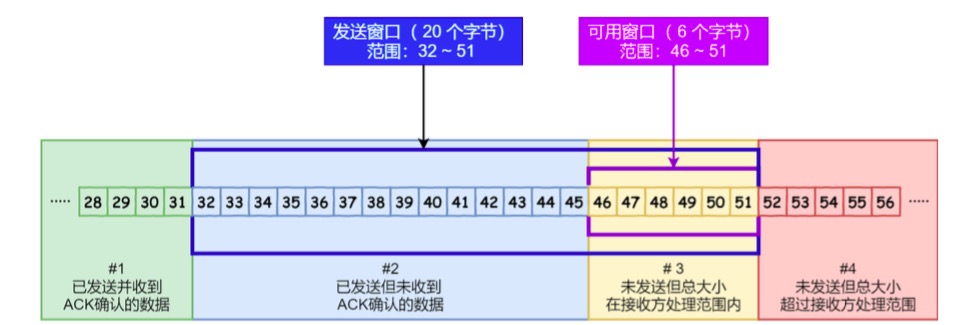
#2 是已发送但未收到 ACK确认的数据:32~45 字节
#3 是未发送但总大小在接收方处理范围内(接收方还有空间):46~51字节

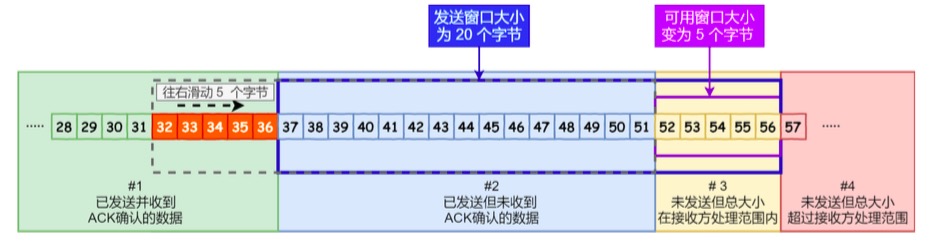
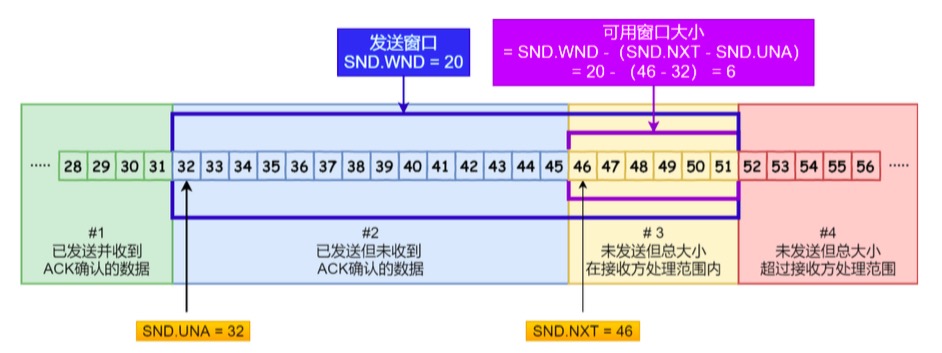
SND.UNA :是一个绝对指针,它指向的是已发送但未收到确认的第一个字节的序列号,也就是 #2 的第一 个字节。
SND.NXT :也是一个绝对指针,它指向未发送但可发送范围的第一个字节的序列号,也就是 #3 的第一个 字节。
指向 #4 的第一个字节是个相对指针,它需要 SND.UNA 指针加上 SND.WND 大小的偏移 ,就可以指向 #4 的第一个字节了。
可用窗口大小 = SND.WND -(SND.NXT - SND.UNA)
接下来我们看看接收方的窗口,接收窗口相对简单一些,根据处理的情况划分成三个部分:
#1 + #2 是已成功接收并确认的数据(等待应用进程读取);
#3 是未收到数据但可以接收的数据;
#4 未收到数据并不可以接收的数据;
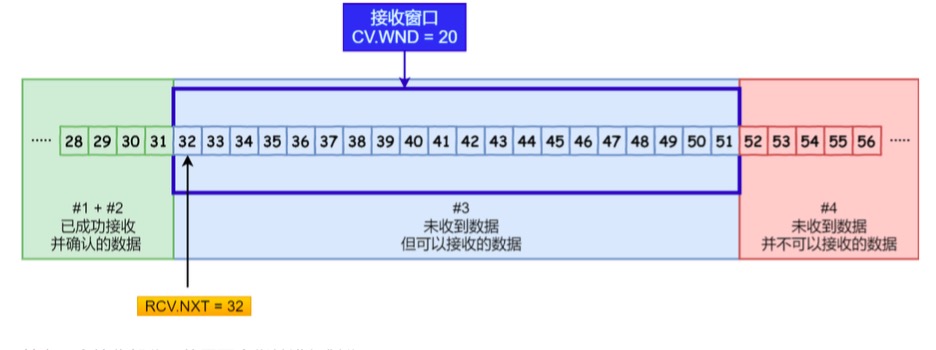
RCV.WND :表示接收窗口的大小,它会通告给发送方。
RCV.NXT :是一个指针,它指向期望从发送方发送来的下一个数据字节的序列号,也就是 #3 的第一个字 节。
指向 #4 的第一个字节是个相对指针,它需要 RCV.NXT 指针加上 RCV.WND 大小的偏移 ,就可以指向 #4 的第一个字节了。
流量控制
那么,当发生窗口关闭时,接收方处理完数据后,会向发送方通告一个窗口非 0 的 ACK 报文,如果这个通告窗口 的 ACK 报文在网络中丢失了,那麻烦就大了
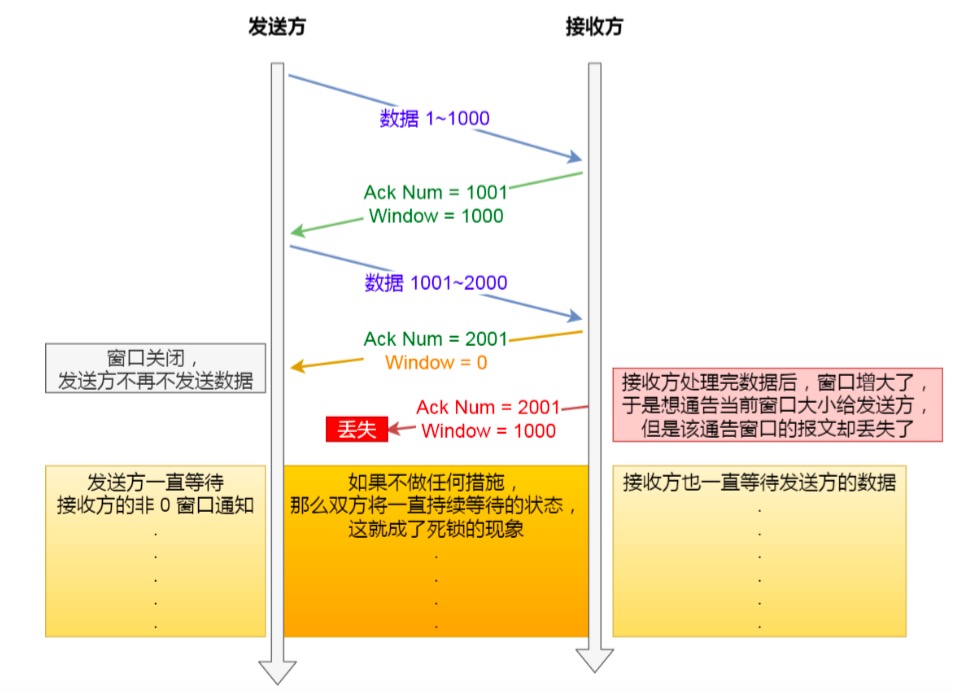
这会导致发送方一直等待接收方的非 0 窗口通知,接收方也一直等待发送方的数据,如不采取措施,这种相互等待 的过程,会造成了死锁的现象
TCP 是如何解决窗口关闭时,潜在的死锁现象呢?
为了解决这个问题,TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持 续计时器。
如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
如果接收窗口仍然为 0,那么收到这个报文的一方就会 新启动持续计时器; 如果接收窗口不是 0,那么死锁的局面就可以被打破了。
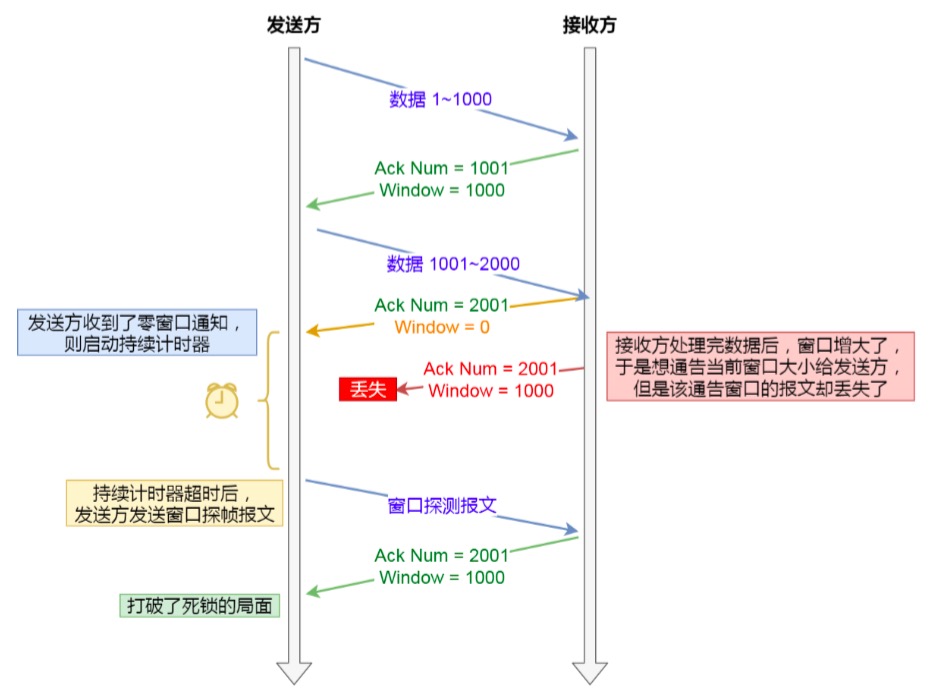
窗口探测的次数一般为 3 次,每次大约 30-60 秒(不同的实现可能会不一样)。如果 3 次过后接收窗口还是 0 的 话,有的 TCP 实现就会发 RST 报文来中断连接。
拥塞控制
为什么要有拥塞控制啊,不是有流量控制了嘛?
前面的流量控制是避免发送方的数据填满接受方的缓存,但是并不知道网络中发生了什么。
一般来说,计算机网络都处在一个共享的环境,因此也有可能会因为其他主机之间的通信使得网络拥堵。
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是 一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,
这个情况就会进入恶性循环被不断地放大....
为了在「发送方」调节所要发送数据的 ,定义了一个叫做「拥塞窗口」的概念。
拥塞窗口 cwnd是发送方维护的一个的状态变 ,它会根据网络的拥塞程度动态变化的。
我们在前面提到过发送窗口 swnd 和接收窗口 rwnd 是约等于的关系,那么由于加入了拥塞窗口的概念后,此时发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值
拥塞窗口 cwnd 变化的规则:
只要网络中没有出现拥塞, cwnd 就会增大;
但网络中出现了拥塞, cwnd 就减少;
其实只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞 。
拥塞控制有哪些算法?
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢启动
TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数 , 如果一上来就发大量的数据,这不是给网络添堵吗?
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这里假定拥塞窗口 cwnd 和发送窗口 swnd 相等,下面举个栗子:
连接建立完成后,一开始初始化 cwnd = 1 ,表示可以传一个 MSS 大小的数据。
当收到一个 ACK 确认应答后,cwnd 增加 1,于是一次能够发送 2 个
当收到 2 个的 ACK 确认应答后, cwnd 增加 2,于是就可以比之前多发2 个,所以这一次能够发送 4 个
当这 4 个的 ACK 确认到来的时候,每个确认 cwnd 增加 1, 4 个确认 cwnd 增加 4,于是就可以比之前多发 4 个,所以这一次能够发送 8 个。

可以看出慢启动算法,发包的个数是指数性的增⻓。
那慢启动涨到什么时候是个头呢?
有一个叫慢启动⻔限 ssthresh (slow start threshold)状态变 。
当 cwnd < ssthresh 时,使用慢启动算法。
当 cwnd >= ssthresh 时,就会使用「拥塞避免算法」。
拥塞避免算法
前面说道,当拥塞窗口 cwnd 「超过」慢启动⻔限 ssthresh 就会进入拥塞避免算法。 一般来说 ssthresh 的大小是 65535 字节。 那么进入拥塞避免算法后,它的规则是:每当收到一个
ACK 时,cwnd 增加 1/cwnd。
接上前面的慢启动的栗子,现假定 ssthresh 为 8 :当 8 个 ACK 应答确认到来时,每个确认增加 1/8,8 个 ACK 确认 cwnd 一共增加 1,于是这一次能够发送 9个 MSS 大小的数据,变成了线性增⻓。

所以我们可以发现,拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度慢了一些,就这么一直增长着,网络就会慢慢进入了拥塞的状况了,于是就会出现
丢包现象,这时就需要对丢失的数据包进行重传,当触发了重传机制,也就进入了拥塞发生算法。
拥塞发生
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种:
- 超时重传
- 快速重传
当发生了「超时重传」,则就会使用拥塞发生算法。 这个时候,ssthresh 和 cwnd 的值会发生变化:
ssthresh 设为 cwnd/2 , cwnd 置为 1

还有更好的方式,前面我们讲过「快速 传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严 ,因为大部分没丢,只丢了一小部分,则
cwnd = cwnd/2 ,也就是设置为原来的一半;
ssthresh = cwnd ;
进入快速恢复算法 ;
快速恢复
快速 传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟 糕,所以没有必要像 RTO 超时那么强烈。
正如前面所说,进入快速恢复之前, cwnd 和 ssthresh 已被更新了: cwnd = cwnd/2 ,也就是设置为原来的一半;
ssthresh = cwnd ; 然后,进入快速恢复算法如下:
拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了); 传丢失的数据包;
如果再收到重复的 ACK,那么 cwnd 增加 1;
如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说 明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,
可以回到恢复之前的状态了,也即再次进 入拥塞避免状态;

也就是没有向超时重传一夜回到解放前,而是还在比较高的值,后续呈线性增长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号