


10 递归:如何用三行代码找到“最终推荐人”
递归的含义:一种非常简洁、高效的编码技巧,方法/函数调用自身的方式称之为递归,调用为“递”,返回为“归”。
所有的递归问题都可以用递推公式来表达。
优点:代码表达能力强,编码简洁。
缺点:(1)空间复杂度高,存在栈溢出风险(策略:可以设置递归次数强行终止条件);(2)存在重复计算,针对这一点可以(策略:可以额外增加哈希表来快速查找结果而减少重复计算);(3)过多函数调用耗时较长。
针对上述缺陷,任何一个递归问题(笼统来讲)都可以转化为非递归实现方式。方法:抽象出递推公式、初始值、边界条件,然后用循环来实现。
11 排序(上):为什么插入排序比冒泡排序更受欢迎?
有序度:在一个数列中,符合顺序排列的数据对个数。(满有序度:全部数据均有序的数据对个数)
逆序度:在一个数列中,不符合顺序排列的数据对个数。
有序度 + 逆序度 = 满有序度。
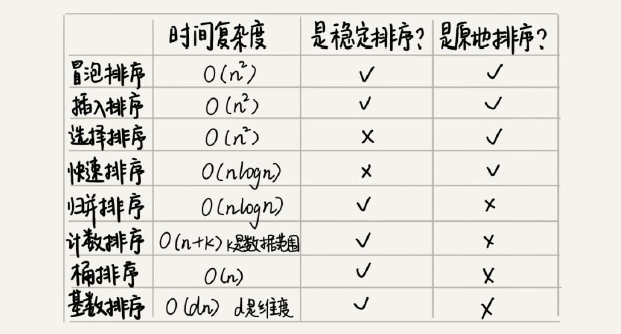
冒泡排序和插入排序都是稳定算法(选择排序是不稳定算法),不论怎么优化,两者的元素移动的次数都等于数列的逆序度。但是,冒泡排序的赋值操作是3个,而插入排序是1个。所以理论上来讲,冒泡排序时间复杂度是3K,而插入排序是1K,如果希望性能更好肯定要首选插入而不是冒泡。基础的插入排序还有很大优化空间,进一步的改进可参考:希尔排序。
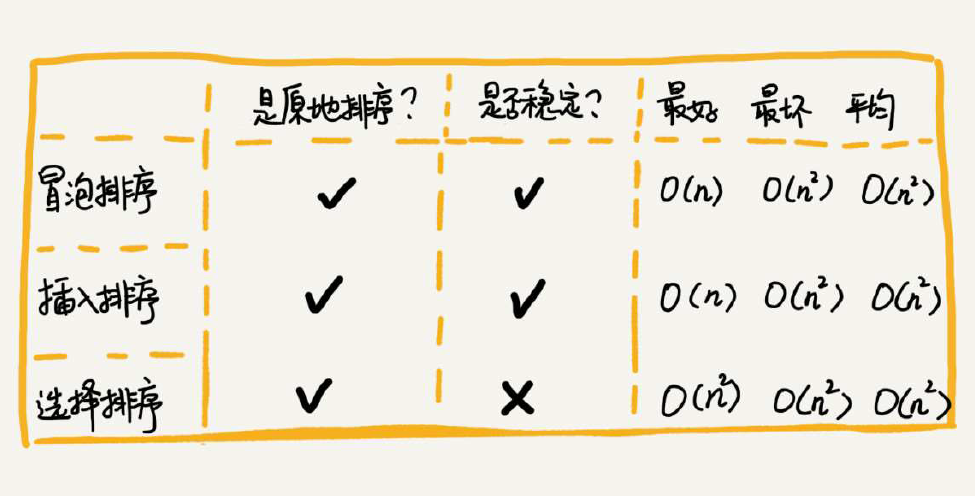
这三种基础排序算法实际的用途不大,但插入排序的思想在某些编程语言的实现原理中还是有可能用到。
12 排序(下):如何用快排思想在O(n)内查找第K大元素?
归并排序:将数列分成前后两部分分别进行排序,然后将两个有序数列合并起来。(优点:时间复杂度低且稳定排序;缺陷:由于合并函数无法原地执行,所以是非原地排序算法,空间复杂度较高O(n)不如快排)
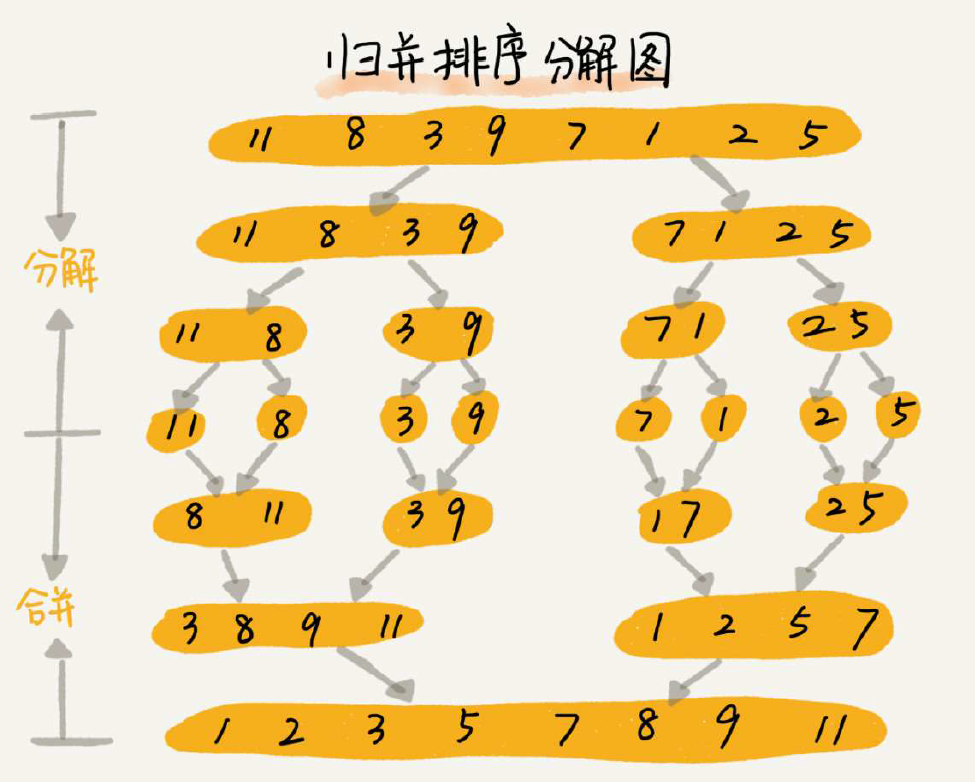
快速排序:与归并排序看起来有点类似,都是借助“分治”思想。(优点:时间复杂度低,空间复杂度仅O(n);缺点:不稳定排序)
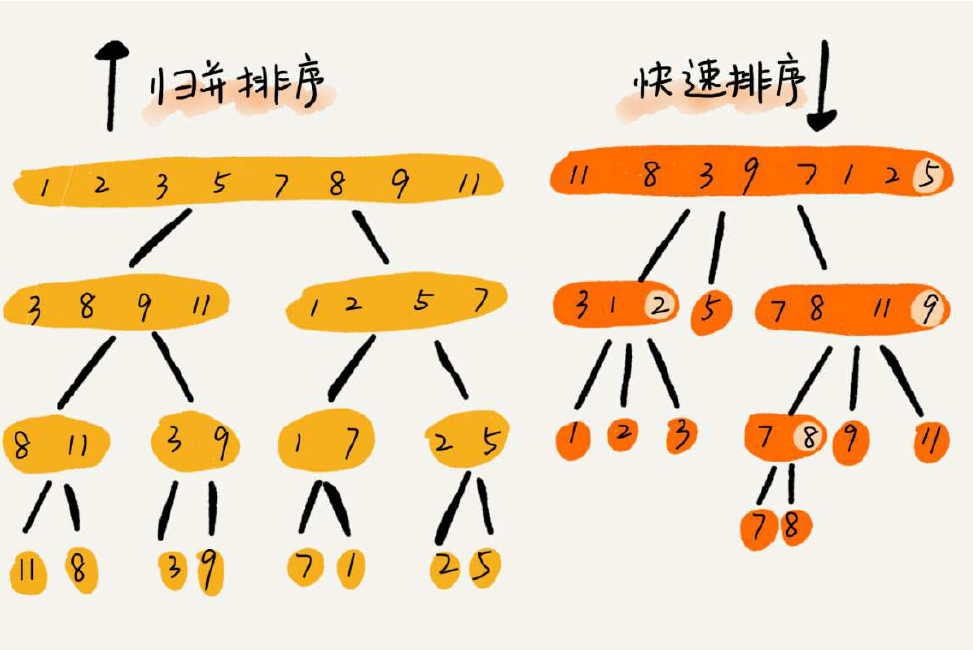
快速排序的时间复杂度依赖于Partition选择的合理性,在极端情况下分区不合理会导致时间复杂度退化为O(n*n)。
选择第K大的思路,每一次分区后,看看分区较小的大小是否符合K-1?如果是那么Guard元素就是了,如果不是,那么继续在分区内查找即可。
13 线性排序:如何根据年龄给100万用户数据排序?
(1)桶排序
将n个数均匀分到m个桶内,每个桶内有k=n/m个元素,桶内用快速排序O(k*logk),整个桶排序的时间复杂度就是O(m*k*logk)=O(n*logk),当m接近n时,该时间复杂度接近O(n)。
看似很棒,实际有很多限制约束条件:<1>需要数列可划分且桶之间天然有序;<2>各桶内数据分布均匀;<3>数据范围不能太大,否则桶太多了。
适用场景:外部排序(内存较小,将数据划分到外部大空间“桶”)。
(2)计数排序
可以理解为桶排序的一种特殊情况:按照n个数据的数据范围[0, k] 划分k 个桶,省去桶内排序时间。其他步骤跟桶排序一样。
最巧妙的关键点:对数列A进行统计得到C,C中每一个位置表示该数值的不大于(<=)的元素个数,通过还原扫描C中每一个位置的数据(每一次计数减一)来得到排序结果R。
约束条件与桶排序一致,数据量不能太大。
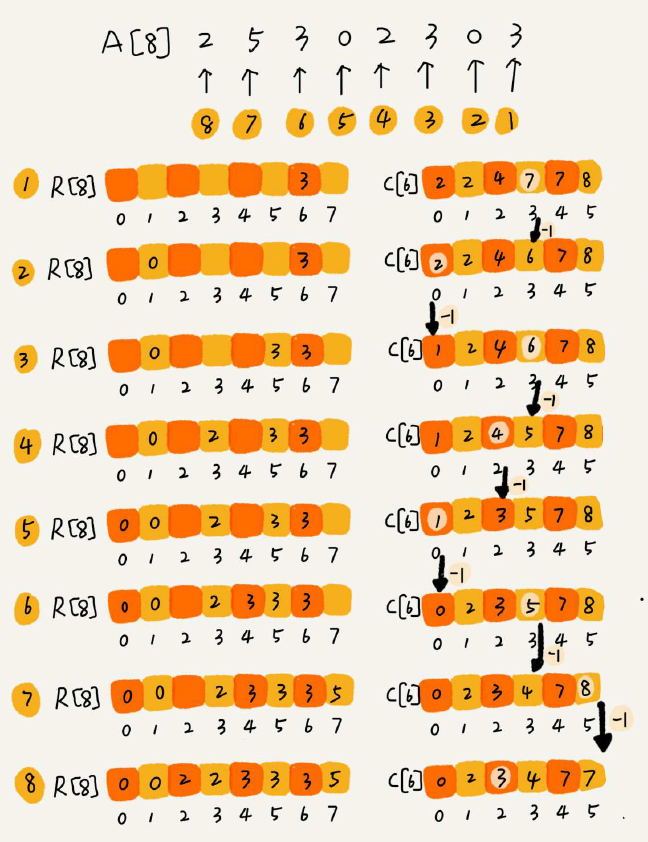
(3)基数排序
对于数据位数一致(例如手机号码)的排序,可能数据量非常大到不能用桶排序和计数排序。这里有一个很巧妙的排序可以接近达到O(n):对每一位从低到高依次进行稳定O(n)排序。例如:
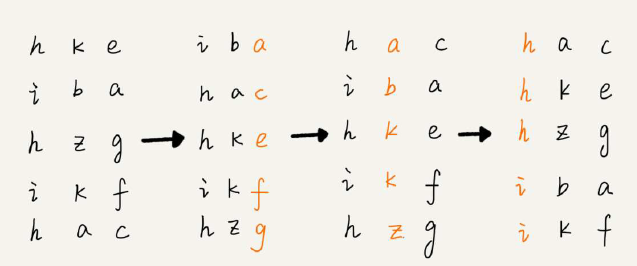
如果数据位数不等,可以通过补齐空位的方式来对齐排序。每一位的排序可以用上面的桶排序或者计数排序来逼近O(n),然后每一位顺序操作下来就是k*O(n)。总之,当位数k不太大时,时间复杂度就是O(k*n),接近O(n)。
综上,基数排序约束条件为:<1>数据要能够划分出独立的“位”;<2>位之间有递进关系,例如高位对比之后低位可以不用比较了;<3>每一位数据范围不能太大,否则不能使用O(n)的桶排序/计数排序。总时间复杂度无法达到O(n)。
14 排序优化:如何实现一个通用的、高性能的排序函数?
优化要点:
(1)让快速排序尽可能接近O(n*logn) 的时间复杂度而不是O(n*n):分区点的选择最重要,可以用“三数取中法”、“随机法”来优化;
(2)对于数据量不大的情况,可以选择O(n)算法来排序,消耗O(n)的空间来换取时间是个很好的优化点;
(3)一般数据量采用快速排序O(n);
(4)对于快速排序中区间小于4个数的情况,退化采用插入排序,虽然是O(n*n)复杂度但实际操作更快。从理论上来解释就是O(n*logn)实际上剪去了一些常量系数,如果加上常量系数后则实际比O(n*n)更慢;
(5)利用哨兵技巧减少一次对比判断,实际效果很好;
15 二分查找(上):如何用最省内存的方式实现快速查找功能?
二分查找时间复杂度O(logn),但有约束条件:(1)连续内存空间支持随机访问;(2)数据有序;(3)不适合处理小规模数据,顺利遍历就OK了,也不适合太大规模数据因为连续内存申请不到;(4)不适合处理动态变化的数据,因为频繁插入删除影响效率;
二分查找算法实现的注意点:(1)(high + low) / 2 有可能因为序号太大而加法溢出,应改成 low + (high - low) >> 1,这里 >> 操作效率比 / 更高。(2)下标移动的时候注意 low = mid + 1,high = mid - 1;
16 二分查找(下):如何快速定位IP对应的省份地址?
二分查找算法的难点在于如何编写正确又能处理变种情况的代码,例如:

(1)查找第一个值等于给定值的元素
一个精简的“漂亮”的写法:


1 int bsearch(int a[], int n, int val) { 2 int low = 0; 3 int high = n - 1; 4 while (low <= high) { 5 int mid = low + ((high - low) >> 1); 6 if (a[mid] >= val) { 7 high = mid - 1; 8 } 9 else { 10 low = mid + 1; 11 } 12 } 13 if (a[low] == val) { 14 return low; 15 } 16 else { 17 return -1; 18 } 19 }
一个更容易理解的写法:
1 int bsearch(int a[], int n, int val) { 2 int low = 0; 3 int high = n - 1; 4 while (low <= high) { 5 int mid = low + ((high - low) >> 1); 6 if (a[mid] > val) { 7 high = mid - 1; 8 } 9 else if (a[mid] < val) { 10 low = mid + 1; 11 } 12 else { 13 if ((mid == 0) || (a[mid - 1] != val)) { 14 return mid; 15 } 16 else { 17 high = mid - 1; 18 } 19 } 20 } 21 return -1; 22 }
可以看到第二种写法只是更直观一点,但总体思路都是:不断缩短二分查找的范围。让mid==val的时候不是二分折半逼近,而是采取单步逼近,最后选择范围内满足数值相等的最低位即可。
(2)查找最后一个值等于给定值的元素(在上面“更容易理解的写法”代码中稍稍变更即可)
1 int bsearch(int a[], int n, int val) { 2 int low = 0; 3 int high = n - 1; 4 while (low <= high) { 5 int mid = low + ((high - low) >> 1); 6 if (a[mid] > val) { 7 high = mid - 1; 8 } 9 else if (a[mid] < val) { 10 low = mid + 1; 11 } 12 else { 13 if ((mid == n - 1) || (a[mid + 1] != val)) { 14 return mid; // 边界检查 15 } 16 else { 17 low = mid + 1; // 缩减范围 18 } 19 } 20 } 21 return -1; 22 }
(3)找到第一个大于等于给定值的元素(想想怎么缩减二分查找的范围边界即可)
1 int bsearch(int a[], int n, int val) { 2 int low = 0; 3 int high = n - 1; 4 while (low <= high) { 5 int mid = low + ((high - low) >> 1); 6 if (a[mid] >= val) { 7 if ((mid == 0) || (a[mid - 1] < val)) { 8 return mid; 9 } 10 else { 11 high = mid - 1; 12 } 13 } 14 else { 15 low = mid + 1; 16 } 17 } 18 return -1; 19 }
(4)找到最后一个小于等于给定值的元素(同上,想想怎么缩减二分查找的范围边界即可)
1 int bsearch(int a[], int n, int val) { 2 int low = 0; 3 int high = n - 1; 4 while (low <= high) { 5 int mid = low + ((high - low) >> 1); 6 if (a[mid] <= val) { 7 if ((mid == n - 1) || (a[mid + 1] > val)) { 8 return mid; 9 } 10 else { 11 low = mid + 1; 12 } 13 } 14 else { 15 high = mid - 1; 16 } 17 } 18 return -1; 19 }
我觉得最后的思考题更值得思考研究:如果是一个循环有序数组(如:4,5,6,1,2,3)那么如何实现上述的二分查找?网友给出来三种思路,第三种很棒:
(1)找到分界点(时间复杂度O(n)),判断目标元素在哪个区间,然后在区间内进行普通二分查找;
(2)找到分界点(时间复杂度O(n))下标x,所有元素下标+x偏移量,超出数组范围则取模。对找到的元素点再做下标-x处理。
(3)将数组mid折半划分为一个有序部分和循环有序部分(时间复杂度O(logN)):如果a[0] < a[mid] 则证明前半部分有序而后半部分为循环有序(反之亦然),如果目标元素在有序范围内则普通二分查找;反之则对循环有序部分继续做上一步查找。
17 跳表:为什么Redis一定要用跳表来实现有序集合?
跳表基本结构如下(对原始链表建立索引层,加快查找速度):
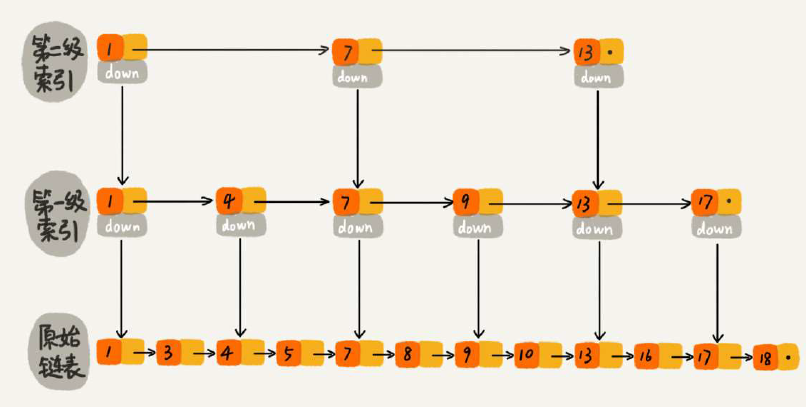
这里以每N=2个元素建立索引为例(如果N>2也是一样的):
(1)查找效率 O(logN):索引层高度logN,每一层访问不超过3个,因此是3 * logN
(2)空间复杂度O(N):索引空间和为 N/2 + N/4 + ... + 2 = N-2
(3)插入时间复杂度O(logN):查找的时间复杂度就是上面的O(logN),实际插入操作时间复杂度O(1)
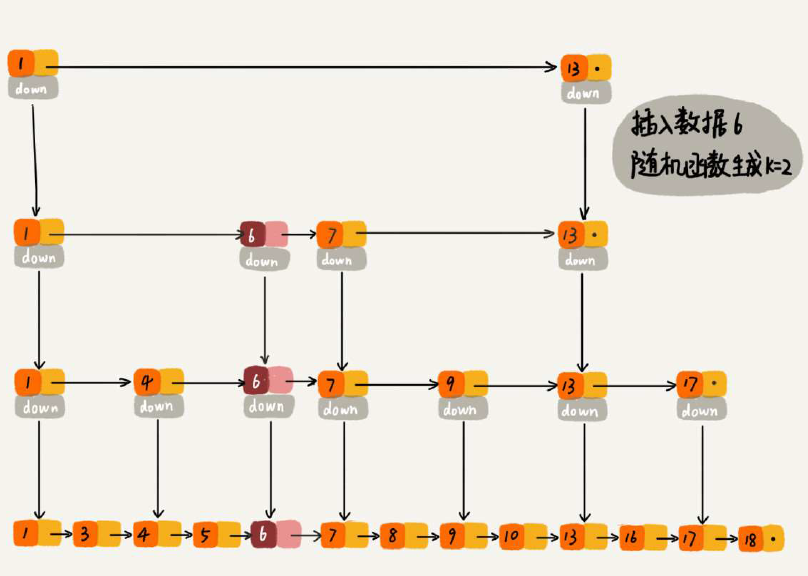
(4)跳表索引更新:采取“随机函数”的方式来维护平衡性。如果随机函数返回值K,就表示从1~K级插入索引数据。这个函数很讲究,要保证性能不至于过度退化。
为什么Redis采用跳表而不是红黑树呢?可能有以下原因:(1)按照区间来查找数据,跳表可以在O(logN)找到起点再顺序遍历,比红黑树快;(2)跳表比红黑树更易实现,可读性好不易出错;(3)跳表更灵活,可以通过改变索引构建策略有效地平衡效率和内存消耗。
跳表相比红黑树的不足:(1)红黑树出现的更早,有现成库支持。跳表只能自己动手实现;
18 散列表(上):Word文档中的单词拼写检查功能是如何实现的?
散列表来源于数据,利用散列函数对数据进行改造,利用的是数组支持随机访问的特点。核心两个问题:(1)散列函数设计;(2)冲突解决方法 --> 常用两种:开放寻址法、链表法。散列函数是好坏决定了散列表的冲突概率(即性能)。
19 散列表(中):如何打造一个工业级水平的散列表?
“散列表碰撞攻击”:攻击者利用精心构造的数据全部散列到同一个槽内,让查找效率从O(1)退化为O(n),达到DDOS效果。
如何设计好的散列函数?(1)不能态复杂,否则计算量大会降低效率;(2)装载因子不能太大。
装载因子太大怎么办?扩容降低因子。一次性扩容会造成瞬间耗时巨大,可以改成分批次扩容,将扩容动作分摊到每一个插入动作中去。查找的时候可以先查新表,再查旧表。
冲突解决办法的优缺点对比:(1)开放寻址法:易序列化,且内存集中可借助CPU缓存加速。但冲突代价太大,耗内存(适用于小数据低装载因子的场景);(2)链表法:内存利用率高,当存储大数据时指针的消耗可忽略,内存不连续对CPU缓存不友好(适用于大数据量大对象场景)。链表法可以进一步优化成“跳表”、“红黑树”达到O(logN)的效果,有效抵御“散列表碰撞攻击”。
20 散列表(下):为什么散列表和链表经常会一起使用?
原来的LRU淘汰算法用链表实现,时间复杂度是O(n),如果加上哈希表就会好很多,虽然操作看起来复杂了一点,但是时间复杂度可以是O(1)。散列表负责快速定位,然后增加一个双向链表可以快速链接到队列头(尾),实现淘汰。
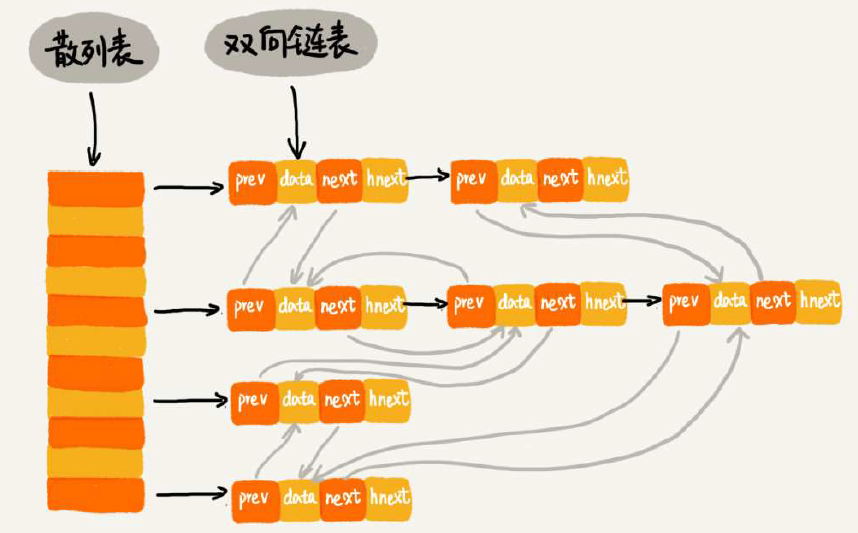
另外,如果将双向链表换成跳表,就具有了跳表的能力了,可以快速定位区间数据。
21 哈希算法(上):如何防止数据库中的用户信息被脱库?
哈希算法四个应用场景:(1)安全加密,如MD5、SHA、DES、AES;(2)唯一标识,作为ID快速定位再仔细对比确认;(3)数据校验;(4)散列函数。
22 哈希算法(下):哈希算法在分布式系统中有哪些应用?
哈希算法在分布式系统中应用场景:(5)负载均衡,利用哈希算法把访问者IP+ID散列到固定值%服务器个数,就可以算出目标服务器而不需要映射表了;(6)数据分片,将同类数据计算哈希并分配到指定机器。借助分片的思路,可以突破单机内存、CPU等资源限制;(7)分布式存储,如何解决分布式系统扩容、缩容导致大量数据搬迁的问题?此时要用到“一致性哈希”:将原有的分隔区间进行进一步细分,把新增节点插入进来转移部分子区间数据即可,不影响原有散列位置。
23 二叉树基础(上):什么样的二叉树适合用数组来存储?
树的基本概念,满二叉树是全部节点都是二叉的,主要是记住“完全二叉树”的概念就行。为何单独把叶子节点全部靠左的称之为“完全二叉树”呢?又为何把这个概念单独拿出来讲呢?看看按数组的二叉树存储方式就知道了——空间利用率很高!(堆其实就是完全二叉树,最常用的是数组存储)
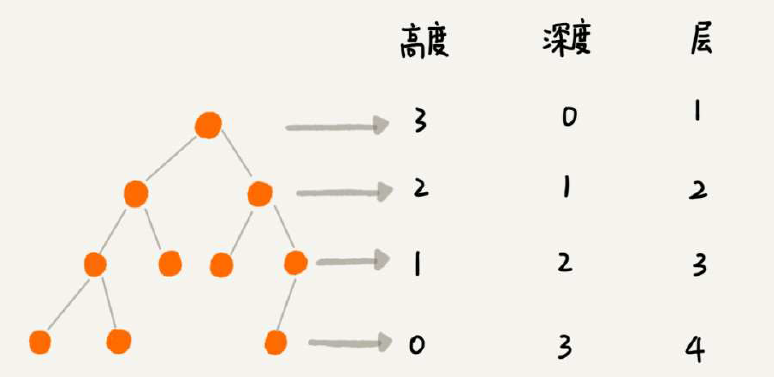
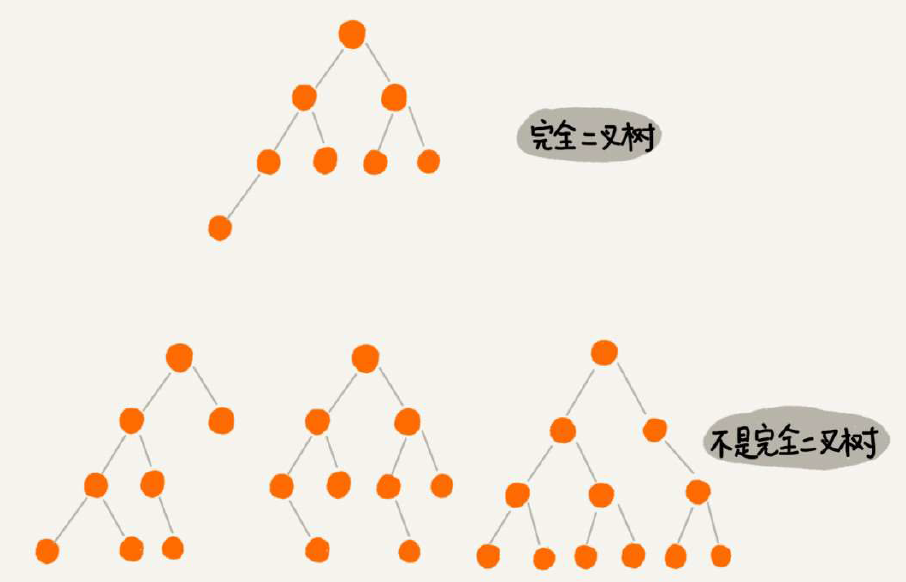
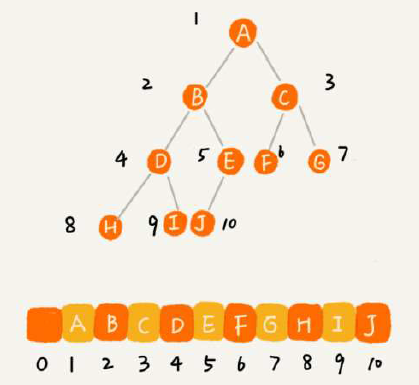
思考题有点难度:(1)怎么实现按层遍历?借助栈或者层数控制?(2)给定一个数列怎么算出可以构建多少种树?
24 二叉树基础(下):有了如此高效的散列表,为什么还需要二叉树?
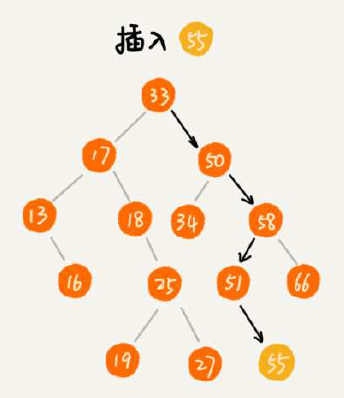
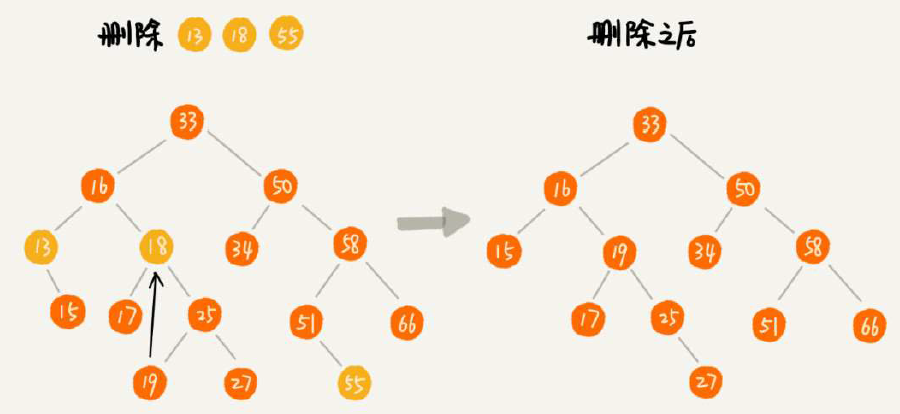
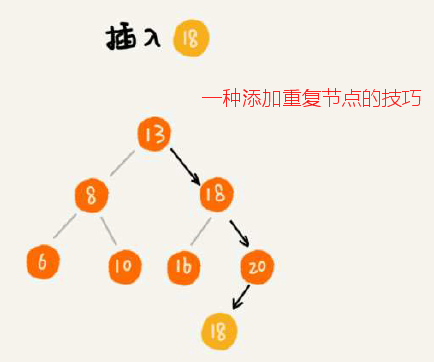
二叉排序树的查找、插入、删除操作,其中删除略复杂一点点,注意删除包含左右子节点的方式(将右子数最小节点替换删除节点)就行了。更取巧的做法是:仅标记节点DEL而并不真正操作节点删除。如果是支持重复节点的二叉排序树呢,插入的方案可以是单节点存储多个,也可以采用一种巧妙方案(将重复节点继续插入右子树),查找和删除重复节点的二叉树就需要一直找到叶子节点为止。
为了有了O(n)的散列表方案还需要搞一个二叉排序树呢?原因有:(1)散列表不利于输出有序数据,而二叉排序树采用中序遍历就能O(n)输出有序数列;(2)散列表扩容耗时长且冲突时性能不稳定,而采用“平衡二叉排序树”非常稳定在O(logN);(3)哈希冲突的查找时间与哈希函数计算的时间累加,可能并不一定比平衡二叉排序树的效率高;(4)散列表的构造比二叉查找树复杂,要考虑效率、冲突、扩容等诸多问题,平衡二叉查找树只需要考虑平衡一个问题。
25 红黑树(上):为什么工程中都用红黑树这种二叉树?
平衡二叉查找树中“平衡”的定义是任意节点的左右子树高度差不大于1。但究其本质“平衡”的目的是希望二叉排序树不要因为频繁动态更新而导致性能退化,实际上不一定要严格遵循高度差不大于1的定义要求。例如红黑树,就是一种非严格的平衡二叉排序树属于“近似平衡”。

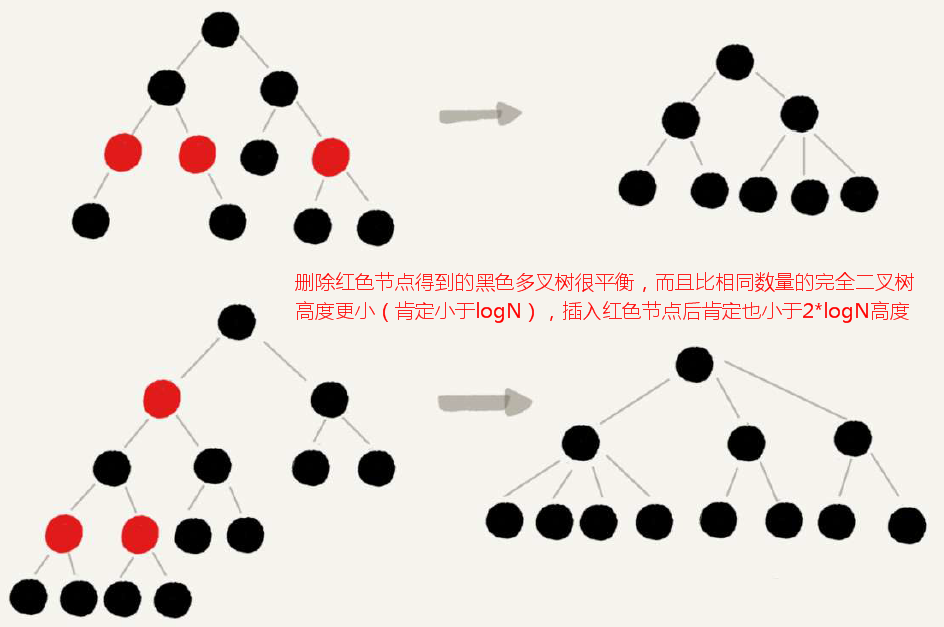
为什么工程中都喜欢红黑树这种非严格的平衡二叉排序树呢?因为Treap、Splay Tree尽管绝大多数情况下效率很高,但无法避免极端情况下时间退化,因此对于单次操作比较敏感的场景并不适用;AVL树是一种高度平衡的二叉查找树,朝赵很高效,但是维护成本非常高昂,不适用于频繁插入删除操作的场合。所以,为了支撑复杂的工业应用场景,更倾向于使用性能稳定的近似平衡的二叉查找树(红黑树)。
26 红黑树(下):掌握这些技巧,你也可以实现一个红黑树
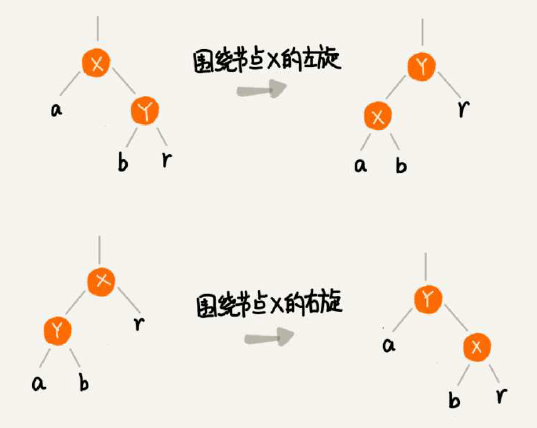
插入删除的操作会对树的平衡产生影响,先来复习下基础概念“左旋”“右旋”。
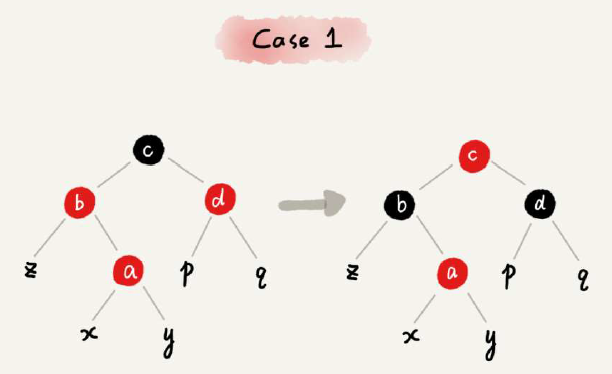
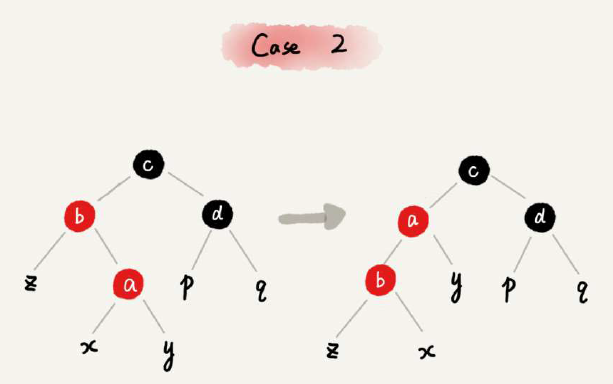
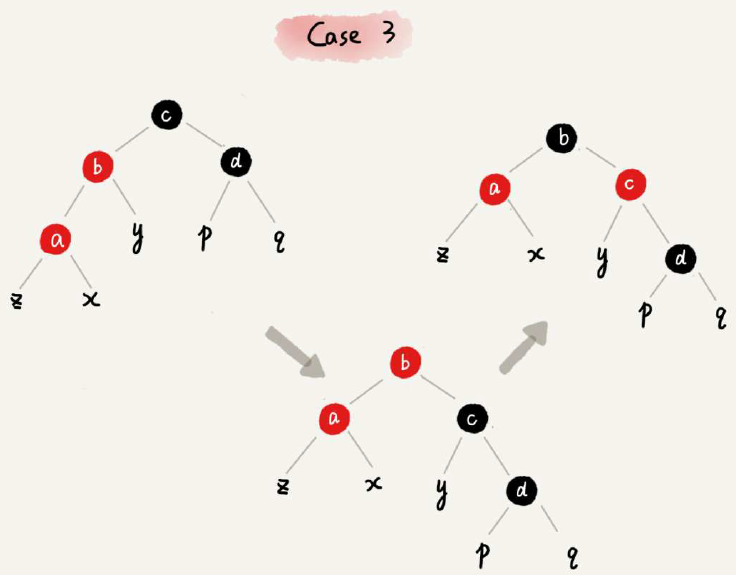
红黑色的调整步骤非常复杂,下面分别来区分CASE对照说明即可:
26.1 红黑树的节点插入
所有调整的方法就是两种基本操作“左右旋转”和“改变颜色”。两种特殊情况:(1)插入节点的父节点是黑色的,那么什么都不用做;(2)插入节点自身就是根节点,那么把颜色变成黑色即可。
其他情况,划分为三种固定CASE来处理即可:
26.1 红黑树的节点删除
红黑树的删除操作比插入要难很多。分为两步走:(1)第一步对删除节点初步调整,目标是确保满足最后一条定义约束:即整个树在删除节点后,每个节点到达叶子节点的所有路径都包含相同数量的黑色节点;(2)针对关注节点做二次调整,目标是确保满足第三条定义约束:即不存在相邻红色节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号