
作业4
1.熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
实验内容
网页结构
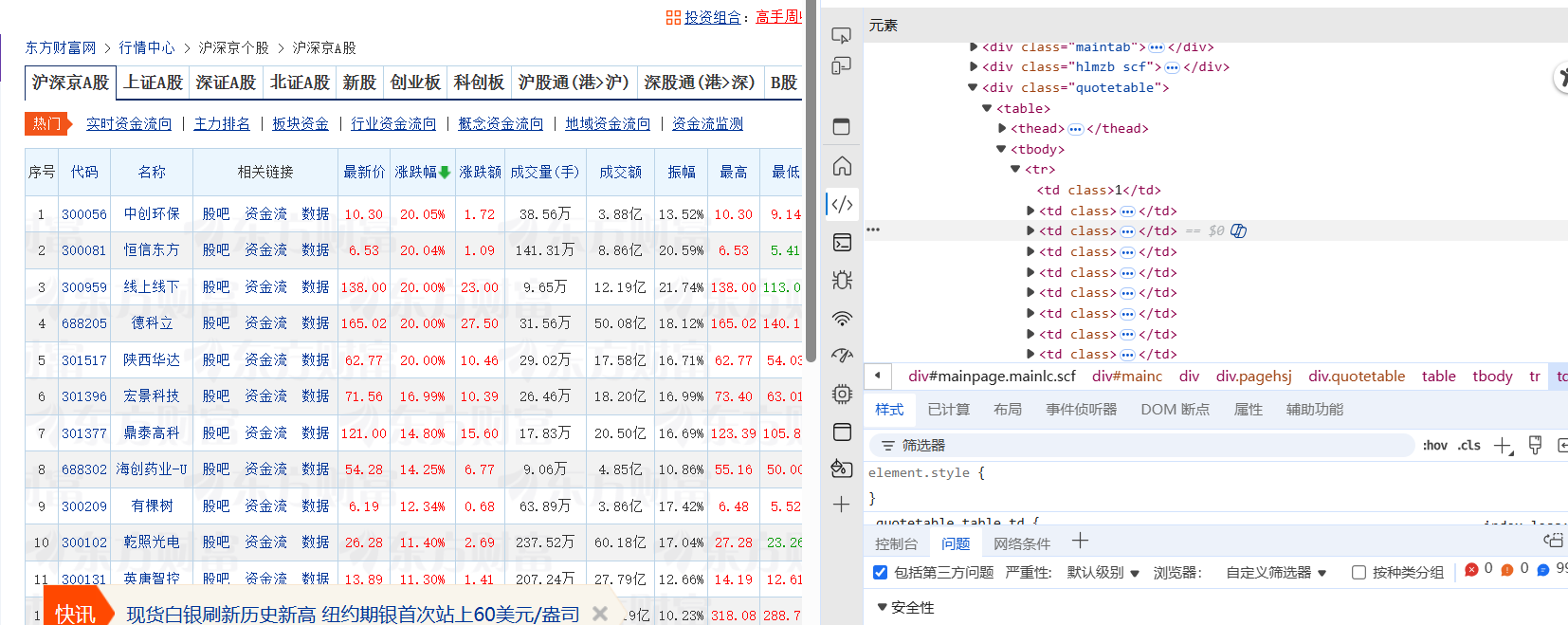
在table中的tr为每行元素,td为单个属性
核心代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pymysql
# 连接 MySQL
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="123456",
database="stock",
charset="utf8mb4"
)
cursor = conn.cursor()
# 启动 Selenium 浏览器
driver = webdriver.Edge()
# 东方财富股票列表基础 URL
BASE_URL = "http://quote.eastmoney.com/center/gridlist.html#"
def close_ad_popup():
"""关闭东方财富网每次都弹出的开户广告"""
try:
# 方法1:点右上角的 X(最常见)
close_btn = driver.find_element(By.CSS_SELECTOR, "div.close-btn, a.close, img.close, span.close")
close_btn.click()
print("已关闭弹窗广告(方法1)")
time.sleep(1)
except:
try:
# 方法2:新版广告的关闭按钮(2025年实测最稳)
driver.execute_script("""
var btn = document.querySelector('div[ad-tag] .close-btn') ||
document.querySelector('.popup-ad .close') ||
document.querySelector('img[src*="close"], img[alt="close"]');
if (btn) btn.click();
""")
print("已关闭弹窗广告(方法2)")
time.sleep(1)
except:
# 方法3:直接隐藏整个广告容器(万能兜底)
driver.execute_script("""
var ads = document.querySelectorAll('div[ad-tag], div.popup-ad, .advertisement, div[class*="ad"], iframe');
ads.forEach(ad => ad.style.display = 'none');
""")
print("已强制隐藏所有广告元素(方法3)")
def crawl_board(hash_code, board_code):
# 1) 拼接 URL,打开对应板块页面
url = BASE_URL + hash_code
driver.get(url)
time.sleep(3) # 给广告一点时间弹出来
close_ad_popup()
# 2) 简单等待页面和数据加载完成
time.sleep(5)
# 3) 找到表格的所有行
rows = driver.find_elements(By.CSS_SELECTOR, "table tbody tr")
print("共发现行数:", len(rows))
sql = """
INSERT INTO stocks
(board, seq_no, stock_no, stock_name,
last_price, change_pct, change_amt,
volume, amount, amplitude,
high_price, low_price, open_price, pre_close)
VALUES
(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
for row in rows:
tds = row.find_elements(By.TAG_NAME, "td")
if len(tds) < 13:
# 防止空行或异常行,列数不足时直接跳过
continue
# 按网页表头顺序取值:
seq_no = tds[0].text.strip() # 序号
stock_no = tds[1].text.strip() # 股票代码
stock_name = tds[2].text.strip() # 股票名称
last_price = tds[4].text.strip() # 最新报价
change_pct = tds[5].text.strip() # 涨跌幅
change_amt = tds[6].text.strip() # 涨跌额
volume = tds[7].text.strip() # 成交量
amount = tds[8].text.strip() # 成交额
amplitude = tds[9].text.strip() # 振幅
high_price = tds[10].text.strip() # 最高
low_price = tds[11].text.strip() # 最低
open_price = tds[12].text.strip() # 今开
pre_close = tds[13].text.strip() # 昨收
data = (
board_code,
seq_no, stock_no, stock_name,
last_price, change_pct, change_amt,
volume, amount, amplitude,
high_price, low_price, open_price, pre_close
)
cursor.execute(sql, data)
conn.commit()
print(board_code, "板块入库完成!\n")
if __name__ == "__main__":
try:
# 依次爬三个板块
crawl_board("hs_a_board", "hs_a") # 沪深 A 股
crawl_board("sh_a_board", "sh_a") # 上证 A 股
crawl_board("sz_a_board", "sz_a") # 深证 A 股
finally:
# 释放资源
cursor.close()
conn.close()
driver.quit()
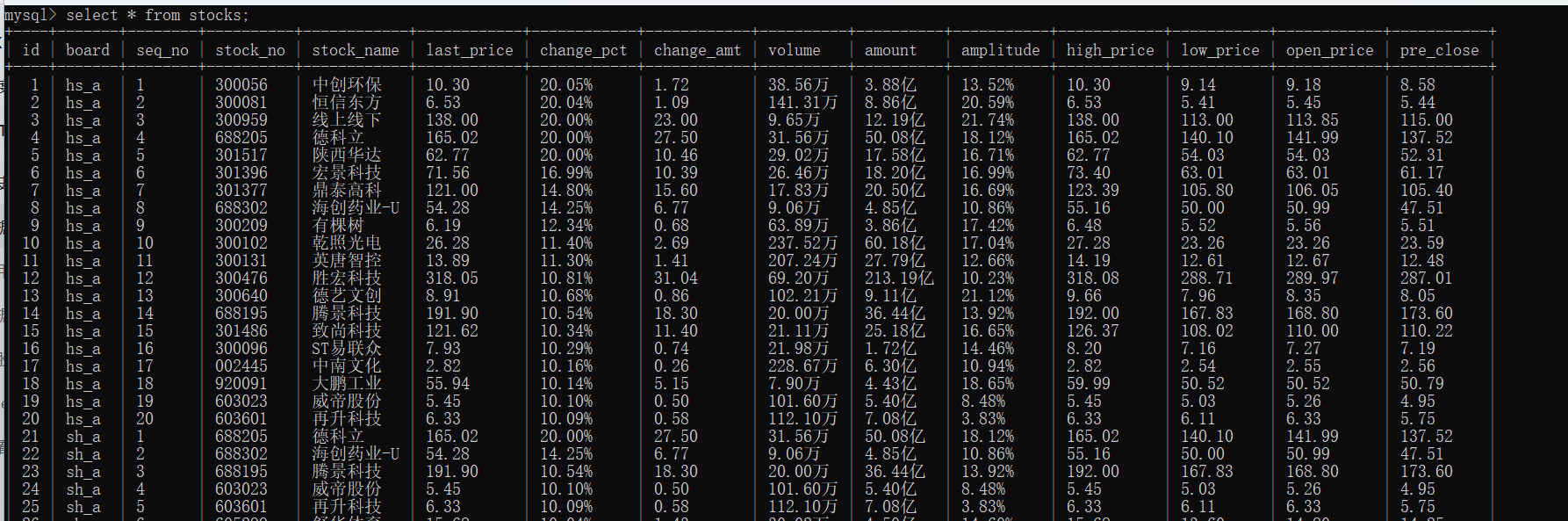
运行结果

心得体会
这个网站加载出来后会有一个广告弹窗,影响页面爬取,div[ad-tag].close-btn:查找有ad-tag属性的div元素内的关闭按钮img[src*="close"]:查找src属性包含"close"的图片(模糊匹配)img[alt="close"]:查找alt属性为"close"的图片,利用这三种方式便可关掉广告
链接https://gitee.com/wugao00882999/data-collection/blob/master/%E4%BD%9C%E4%B8%9A4/stocks.py
2.熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
实验内容
网页结构
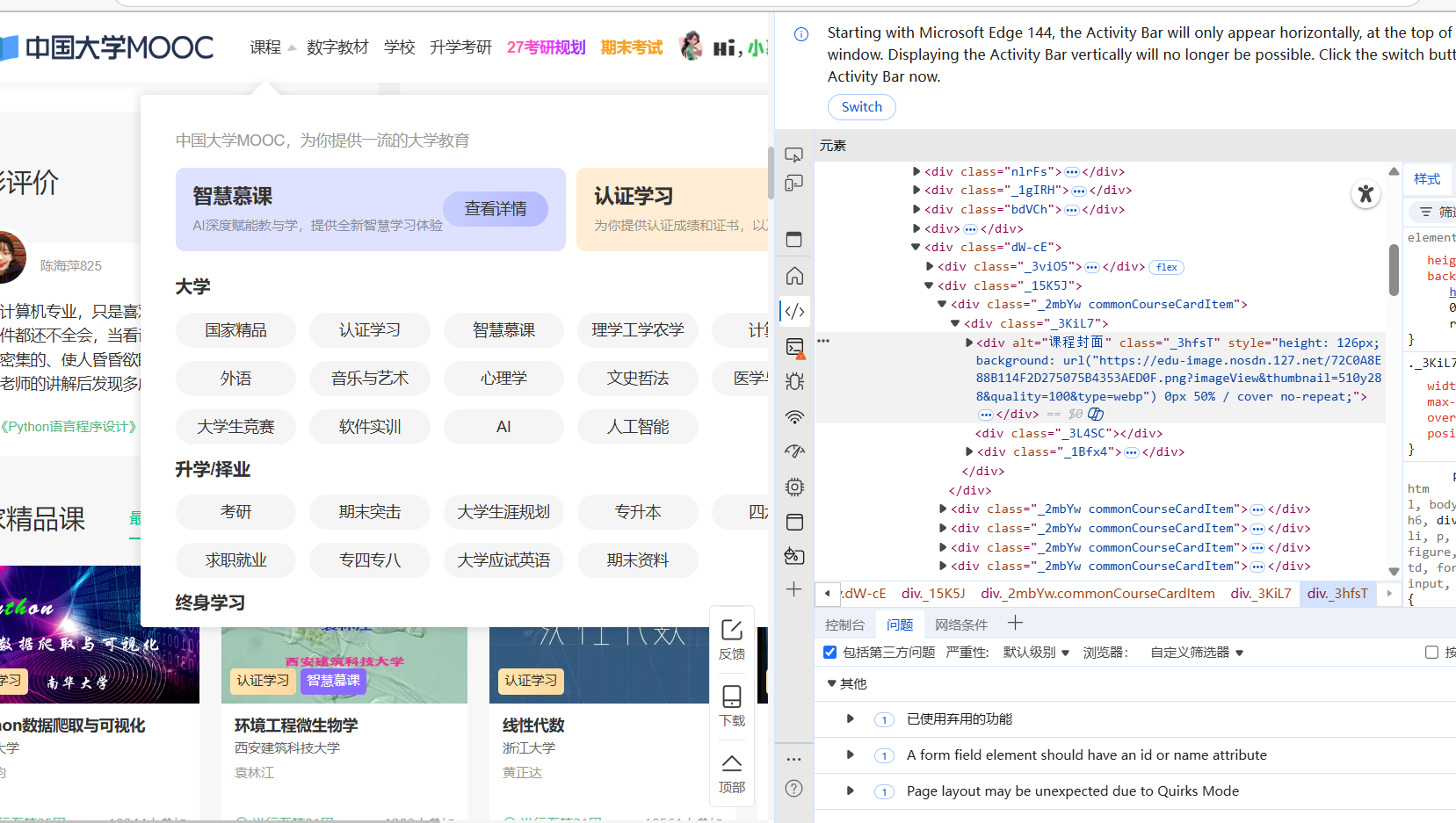
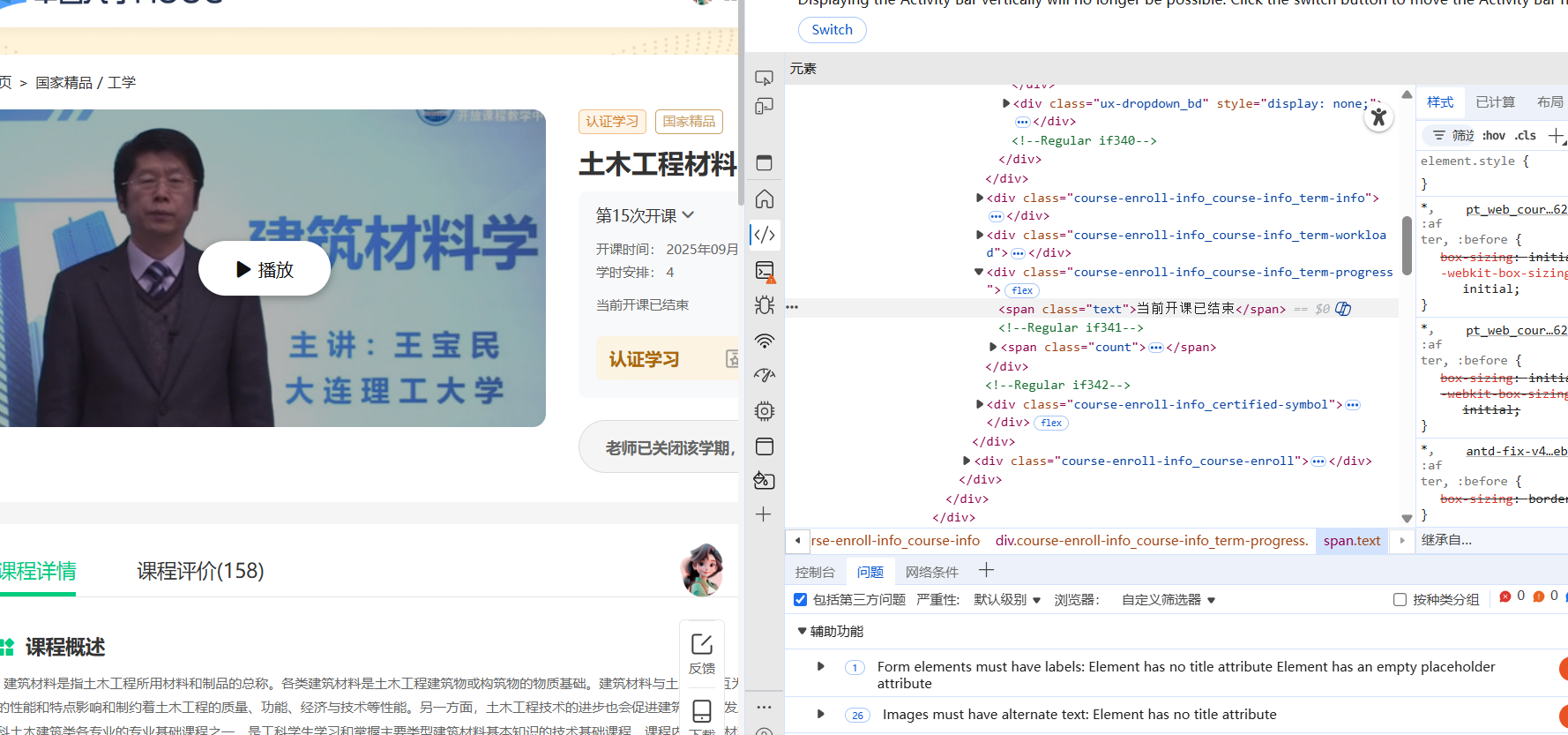
可以看到,这是很明显的动态加载页面,十分适合用动态方法爬取
核心代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pymysql
options = webdriver.EdgeOptions()
# 反爬配置
options.use_chromium = True # 使用Chromium版Edge
options.add_argument('--disable-blink-features=AutomationControlled') # 隐藏自动化特征
options.add_argument('--no-sandbox') # 防止某些环境下的沙盒问题
driver = webdriver.Edge(options=options)
driver.maximize_window()
# 数据库连接
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3306, database='mooc')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS courseMessage')
sql = '''CREATE TABLE courseMessage(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),
cProcess varchar(32),cBrief varchar(2048))'''
cursor.execute(sql)
def spiderOnePage():
time.sleep(3)
courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
current_window_handle = driver.current_window_handle
for course in courses:
cCourse = course.find_element(By.XPATH, './/h3').text # 提取课程名称
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 提取院校
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 提取老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 提取学校人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 提取课程进度
course.click()
Handles = driver.window_handles
if len(Handles) < 2:
continue
driver.switch_to.window(Handles[1])
time.sleep(3)
# 提取课程详情
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text # 先通过固定ID找简介
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*') # 获取简介区块下的所有子元素
cBrief = ""
for c in cBriefs:
cBrief += c.text
cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")
cBrief = cBrief.strip()
nameList = []
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]') # 提取授课团队
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]') # 提取下一页按钮
while len(nextButton) != 0:
nextButton[0].click()
time.sleep(3)
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
cTeam = ','.join(nameList)
# 关闭详情页
driver.close()
driver.switch_to.window(current_window_handle)
# 插入数据库
cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
driver.get('https://www.icourse163.org/')
driver.get(WebDriverWait(driver, 10, 0.48).until(EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a'))).get_attribute('href'))
spiderOnePage()
count = 1
# 翻页逻辑
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
while next_page.get_attribute('class') == '_3YiUU ':
if count == 2:
break
count += 1
next_page.click()
spiderOnePage()
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
# 关闭数据库连接
cursor.close()
db.close()
time.sleep(3)
driver.quit()
运行结果

心得体会
这个项目让我学会了如何爬取教育平台数据,处理复杂的页面交互和教师信息展示。
链接https://gitee.com/wugao00882999/data-collection/blob/master/%E4%BD%9C%E4%B8%9A4/icourse1.py
3.掌握大数据相关服务,熟悉Xshell的使用完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务
实验内容
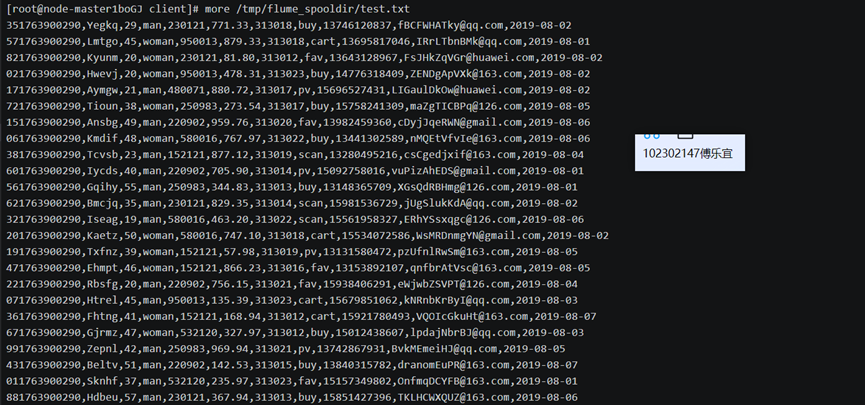
Python脚本生成测试数据
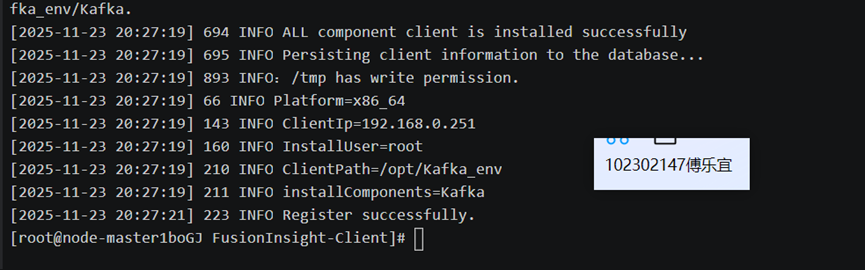
配置Kafka

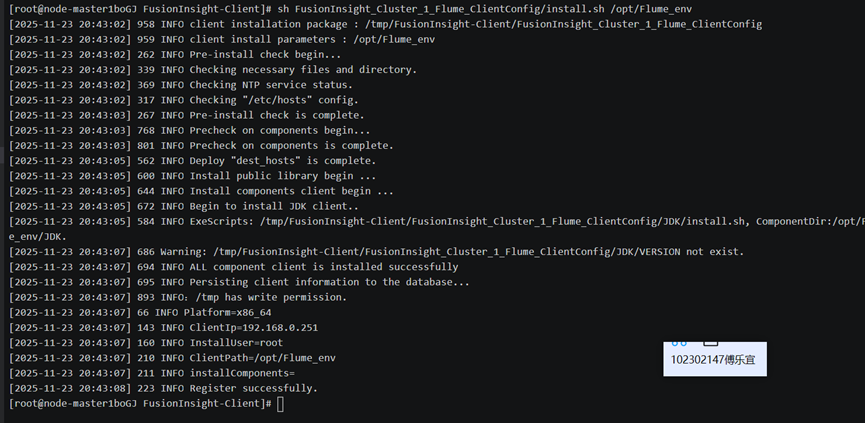
安装Flume客户端

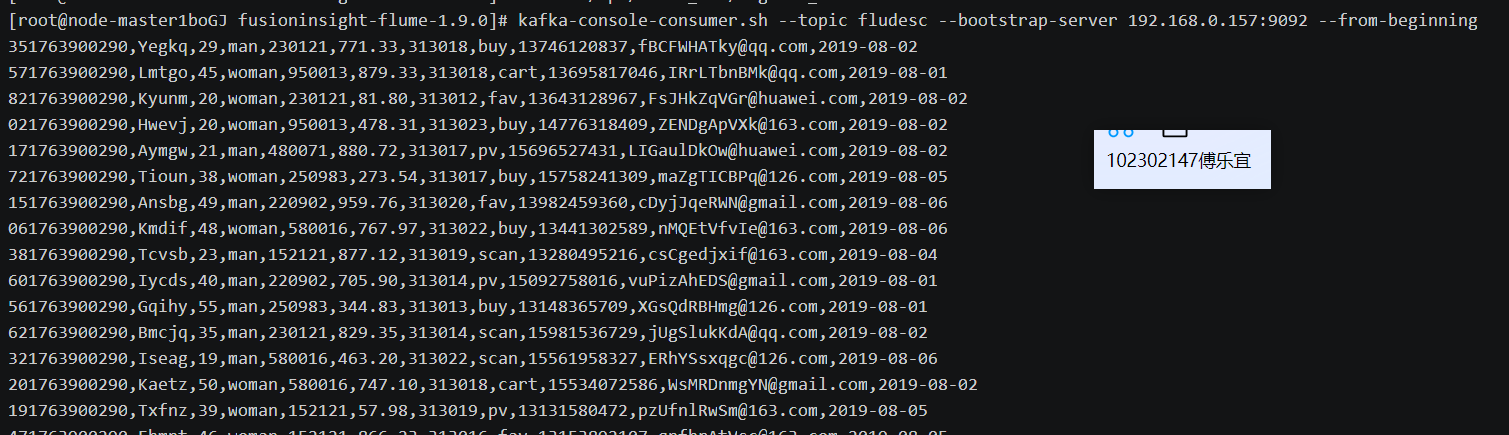
配置Flume采集数据

心得体会
通过这次Flume日志采集实验,我系统性地掌握了大数据生态核心技术的集成应用。不仅学会运用Python模拟复杂业务数据流,更深层次理解了分布式消息系统Kafka在高并发场景下的架构哲学,以及Flume在数据采集领域展现的工程美学。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号