

多源异构数据信息的融合方式1 - 区间数
一、区间数
鉴于区间数容易计算的特点,将多源异构数据融合为区间数的形式。区间数,如果表示为一个具体的东西,那么该是什么?
步骤1:统一化处理决策矩阵D和T,其中D代表的是方案A在属性C下的评估值,其中T代表的是方案A在属性G下的评估值。
方案A:代表备选方案的集合,属性C:效用满意度评估时考虑的决策属性。其中属性C包含区间数、直觉模糊数、犹豫模糊数和语言变量的集合。属性G:灾民关注的决策属性。其中属性C包含区间、直觉、犹豫模糊数和语言变量的属性集合。
步骤2:计算效用满意度函数Fij
决策者对于方案属性的评估有基本的期望区间,满意度分别为0/1。评估值在期望区间中,根据前景理论,决策者在评估值在超过参照点为损失规避,满意度为凹函数;反之,如果决策者为风险追求,满意度为凸函数。根绝前景理论,计算益损值:
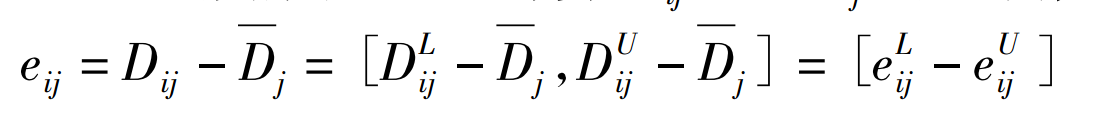
通过eijU <0和eijL >0分别表示为决策者在方案A的属性C下的评估值的感知是收益和损失;的设eij 的均值 是服从均匀分布的变量,密度函数为f(eij 的均值),前景价值为Vij 。
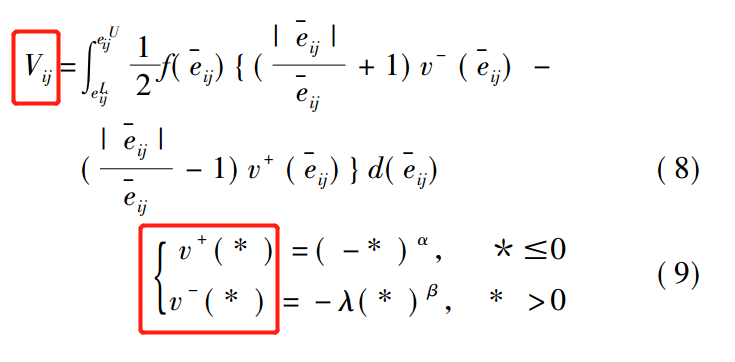
构建效用满意度函数Fij,公式如下所示:
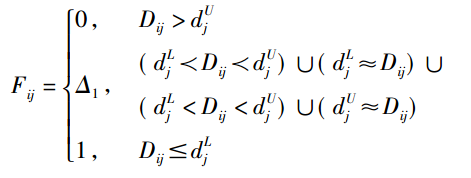
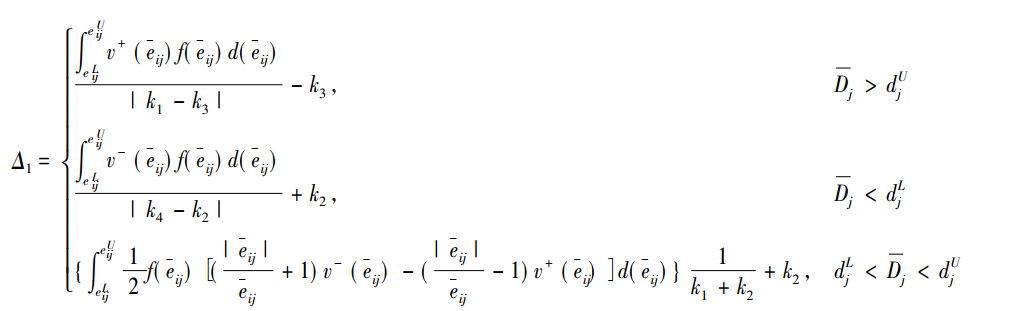
其中Fij满足
(1) Dij低于 djL或高于 djU 时,方案满意度分别取最大和最小值,即Fij = 1和 Fij = 0;
(2) Dij在[djL,djU]内时:
1) Dj 在[djL,djU]内时,若Dij超过 Dj ,则Fij是 凹函数,若 Dij低于 Dj ,则Fij是凸函数;
2) Dj超过djU时,Fij是凸函数;
3) Dj低于djL时,Fij是凹函数。
步骤3:计算公平满意度函数B
灾民对于方案属性的评估也有期望区间,评估值在区间范围内,根据不公平厌恶模型与最优地区相比,当前灾区的收益处于优势和劣势的时灾民会感到不公平。计算当前灾区Eh和相对最优地区的差距:
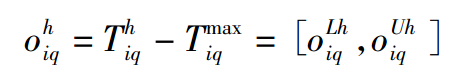
通过oiqLh >0和oiqUh <0分别表示灾区Eh的收益优于最优灾区和劣于最优灾区;设oiq h的均值和Tiq h的均值是服从均匀分布的变量,密度函数分别为f(oiq h的均值)和f(Tiq h的均值),公平效用为Viq h的平均值求得。
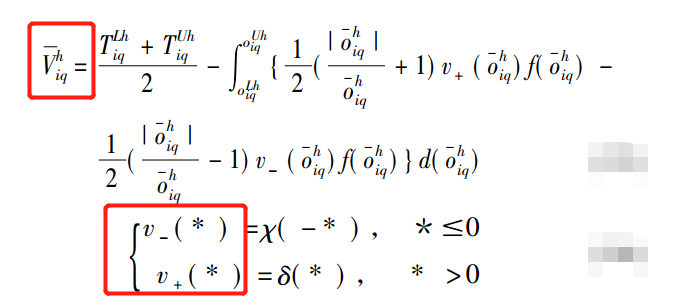
构建公平满意度函数Biqh,公式如下所示:
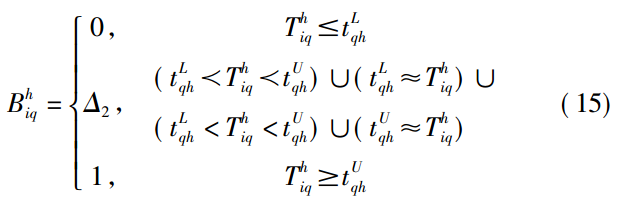
其中△2如下所示:

据此,方案Ai在属性Gq上的满意度Biq为:
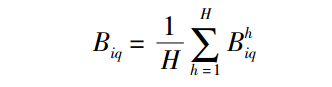
步骤4:计算权重wj和gq
其中,方案在属性下的综合满意度越大越好。各个方案在某一个属性下的满意度具有较大的差异时,则该属性被赋予更大的权重。因此,基于统一属性下,两个方案之间满意度的最小偏差最大化和综合满意度最大化原则建立的目标优化模型。
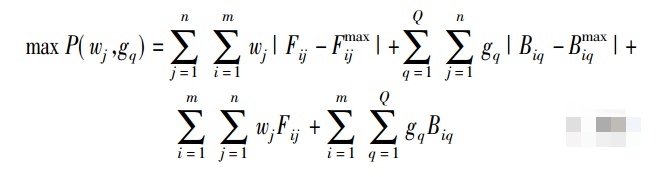
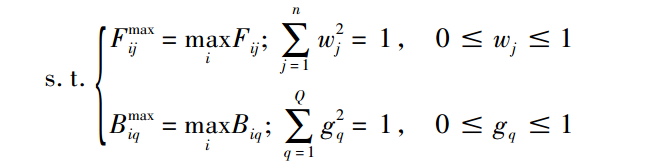
构造拉格朗日函数 L( wj ,gq,λ1,λ2 ) :
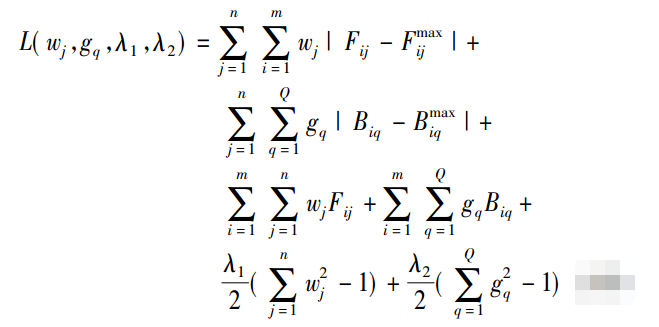
令拉格朗日函数L关于 wj ,gq,λ1,λ2的偏导为0,可求得属性权重wj和gq分别为:

步骤5:计算F与B的综合满意度BF,BF值越大,方案A越优,可得最优方案。
令 μ(0<μ<1) 表示决策者对两种满意度的偏好系数,则可得方案的综合满意度 BF( Ai) :
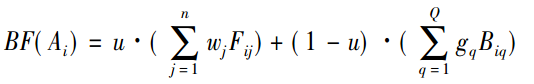
理论+实践结合:
暂无

 浙公网安备 33010602011771号
浙公网安备 33010602011771号