
以Webdriver实例了解Webdriver
Webdriver是一个自动化测试软件,也是处理Ajax渲染之一的爬虫工具。
本文以一个实际案例(今日头条的阳光宽频(365yg.com))来了解它有什么作用,它能做什么。相关的爬取思路也可应用在其他相类似的网站。
分析思路
第1步:首先进入https://365yg.com确定爬取的目标,本例爬取视频的下载链接、视频标题和作者

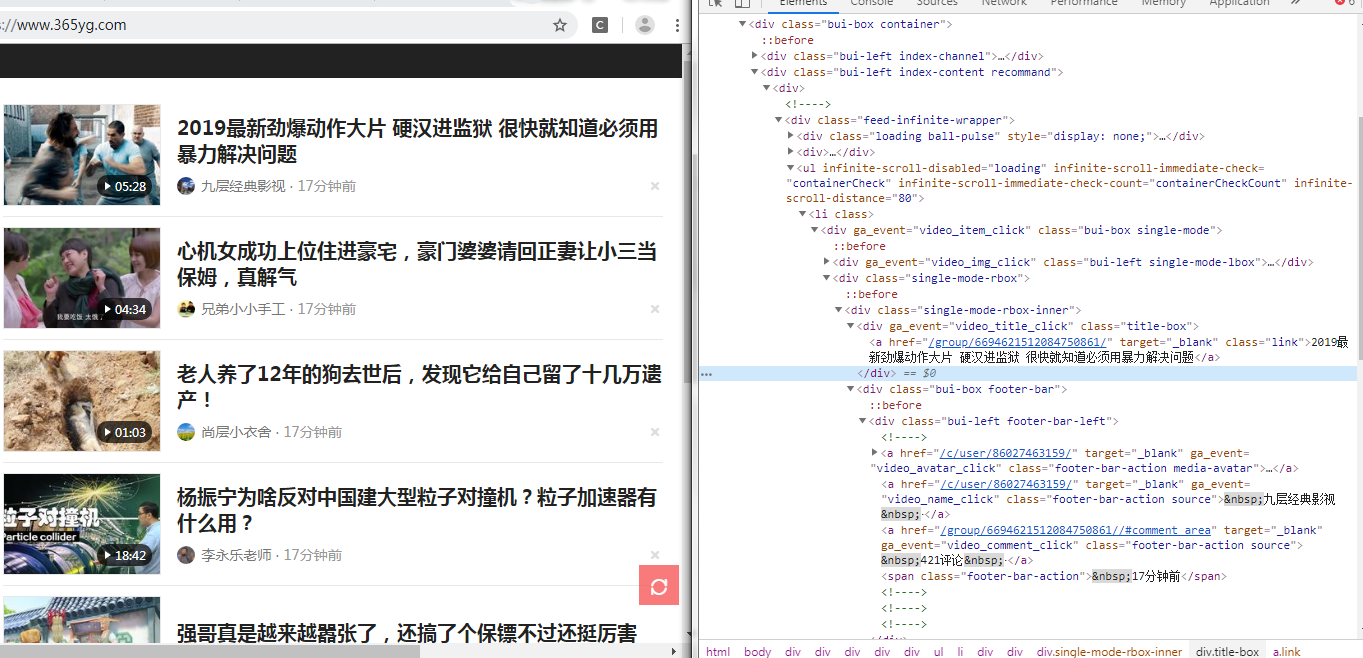
第2步:单击鼠标右键选择检查或按键盘F12调出谷歌浏览器抓包工具进行分析
多次查看不同的视频内容发现它们的视频超链接、视频标题和作者的网页结构完全一样,没有反爬点,无需其他的处理
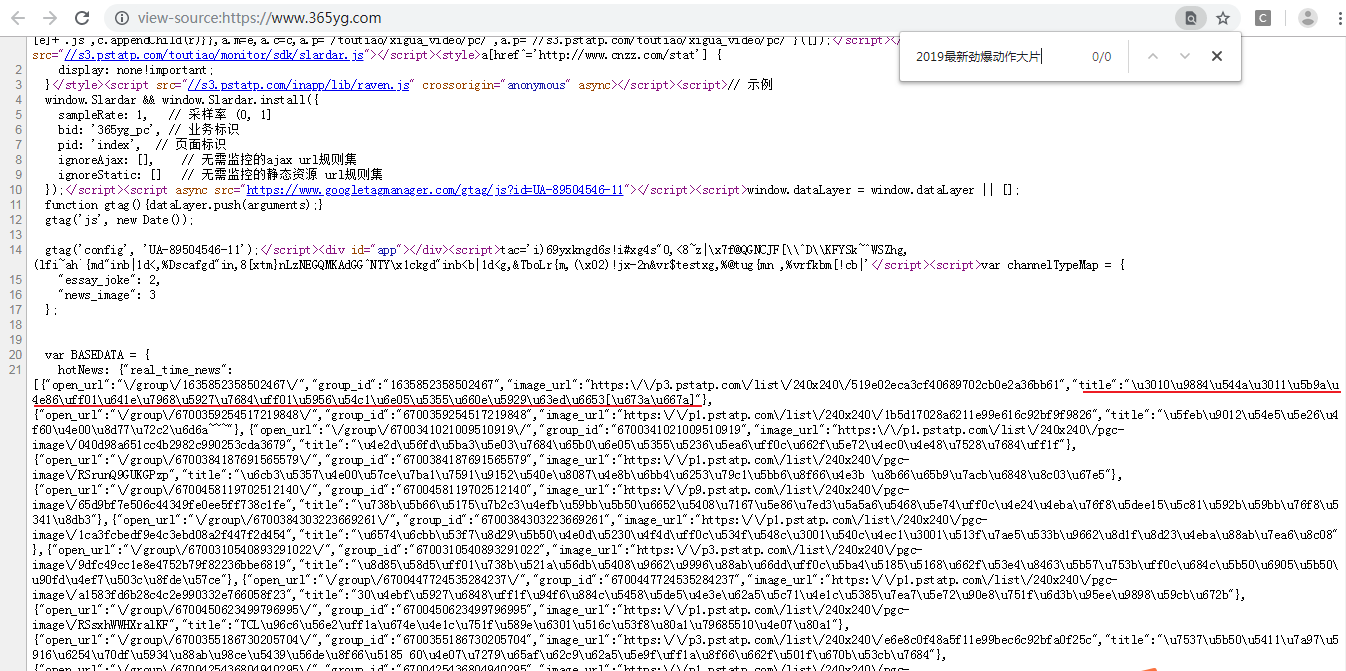
第3步:单击鼠标右键选择查看网页源代码查看是否被Ajax渲染
3.1从搜索结果上看该网页很有可能已被Ajax渲染,但是仔细看发现下面这个区域有些关键字与我们需要的内容很相似,而且相关内容带有\u****等字样,有可能是将返回的中文转化为Unicode!!
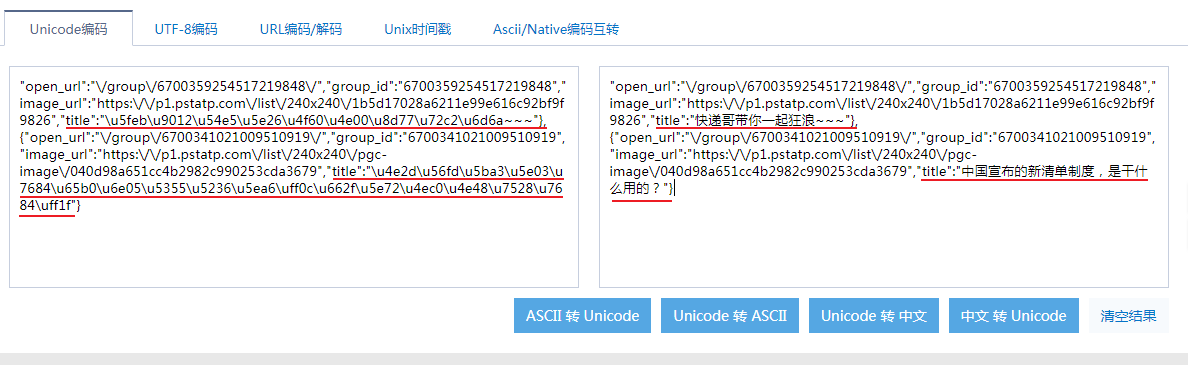
3.2复制部分内容进行验证后发现尽管标题的内容与我们查找的标题不一样,但可确定的是首页没有被Ajax渲染,请求返回的视频标题、作者等信息会动态改变。
第4步:截止目前已解决爬取视频标题和作者、接下来着手视频的下载链接,接下来主要重复上面第1、第2、第3步
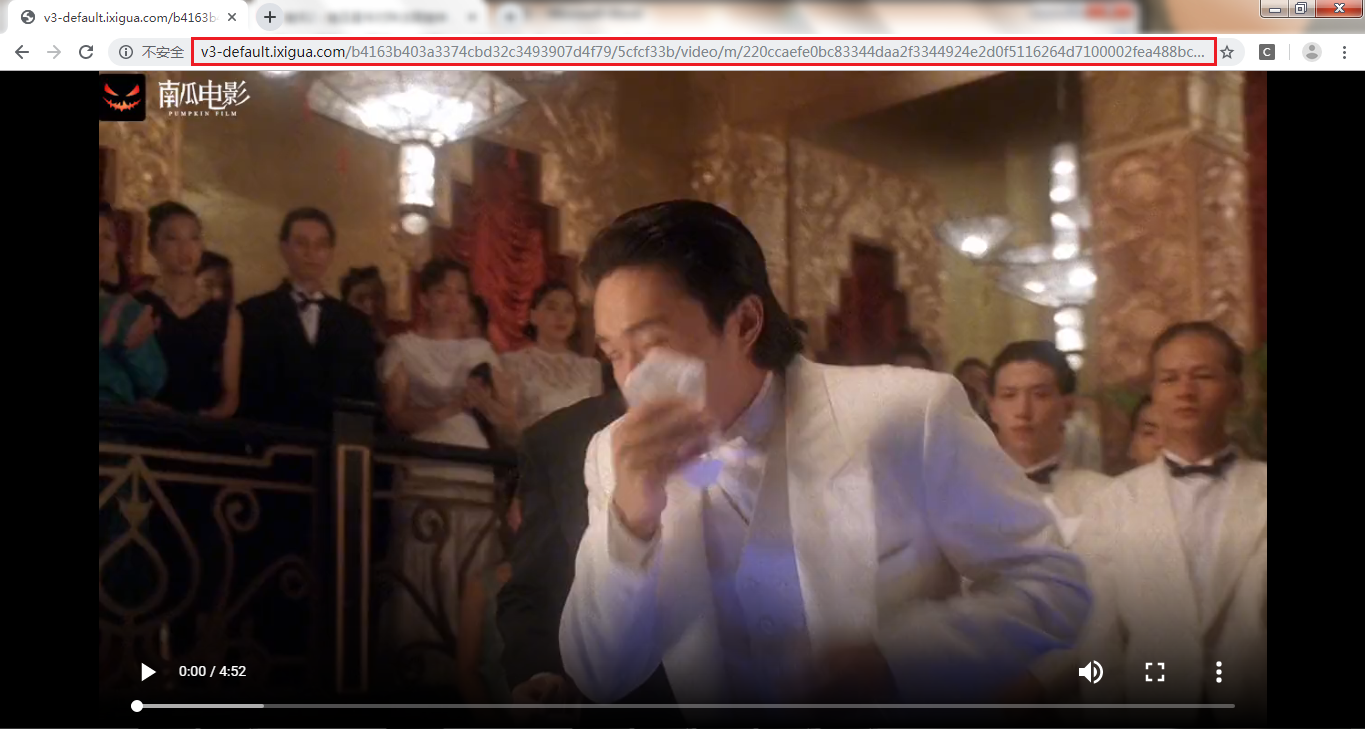
在浏览器中复制第2步获取到的a标签的链接并进入,使用与第2步相同的方式调取谷歌浏览器抓包工具进行分析,复制video标签中的src属性值的链接http://v3-default.ixigua.com/b4163b403a3374cbd32c3493907d4f79/5cfcf33b/video/m/并用浏览器打开

如图所示视频已加载出来,也就是说这个链接就是我们要找的视频下载链接!!
第5步:别高兴得太早,仔细想一下头条的反爬就这么容易被攻破吗?以第3步相同的方式查看该网页的网页源代码,并在页面查找video标签中的src属性值的链接http://v3-default.ixigua.com/b4163b403a3374cbd32c3493907d4f79/5cfcf33b/video/m/, 并没有查找到内容,而且也无带有\u****等字样相关内容。

经Ajax渲染后的网页代码与网页源代码对比发现,网页源代码中缺少了视频下载链接相关的内容,因此可确定这网页是带有Ajax渲染的。
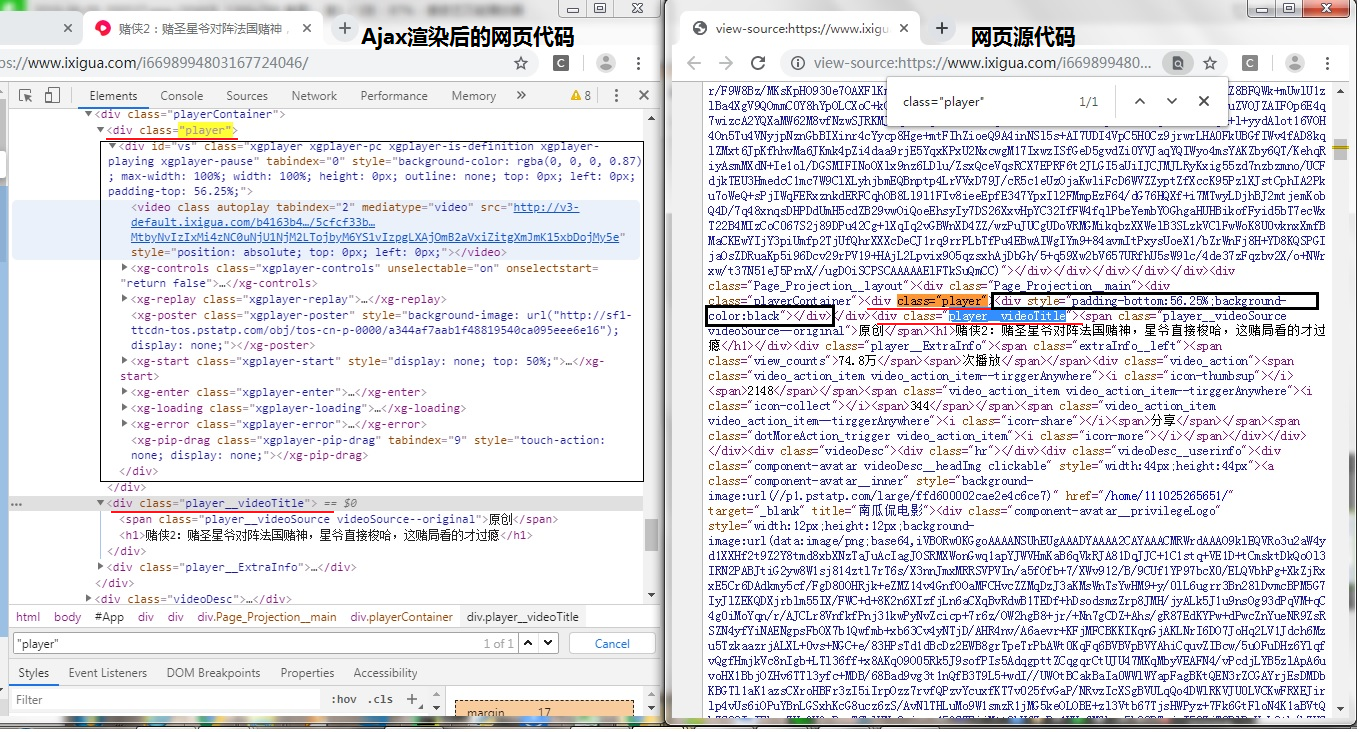
因为我们使用requests或webdriver等获取回来的网页代码就是网页源代码中相关的内容,如果我们直接使用webdriver进行解析标签就会提示没有找到该标签,使用Xpath、BeautifulSoup或Re进行解析也是类似的结果

第6步:难道就没有解决办法吗?上文有提及webdriver是处理Ajax渲染之一的爬虫工具,那如果能控制webdriver像浏览器那样等候ajax渲染后再获取该网页代码不就可以获取video标签中的src属性值的视频下载链接了吗?
没错,强大的webdriver提供了一个WebDriverWait方法提供多种显式等候方法,调用相关方法就能控制webdriver进行不同条件的等候。
代码实现思路
1.创建爬虫类以及导入需要使用的包 -> 2.发送网络请求并获取首页所有的视频的链接、视频标题和作者 -> 3.遍历每个视频播放链接并发送网络请求 -> 4.进行延时等候直至视频标签加载出来 -> 5.解析视频标签获取真实的视频下载链接 -> 6.保存爬取的视频链接等详情
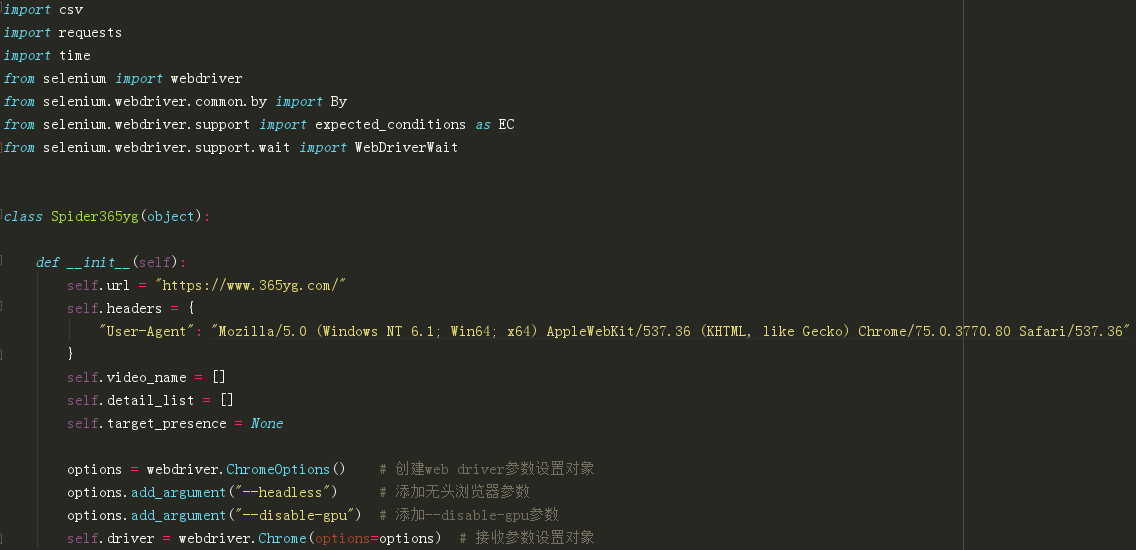
第1步:创建爬虫类以及导入需要使用的包 ->
在爬虫类的__init__方法中添加初始化url、User-Agent及创建webdriver对象
第2步:发送网络请求并获取首页所有的视频的链接、视频标题和作者 ->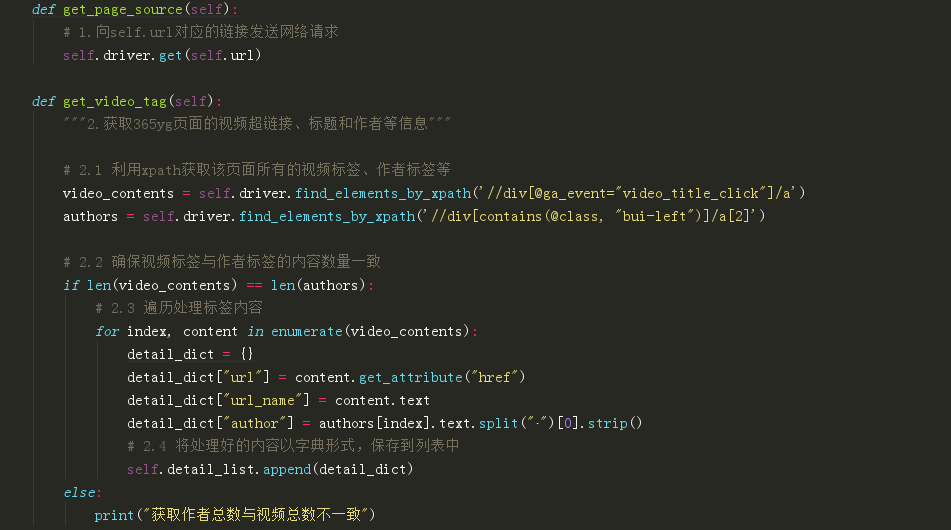
第3步:进行延时等候直至视频标签加载出来 -> 解析视频标签获取真实的视频下载链接 ->

第4步:保存爬取的视频链接等详情

第5步:将所有的方法封装到start()方法,并调用start()方法运行爬虫

查看运行结果
打开代码运行后生成的csv文件,复制real_url列任意的url并在浏览器中打开
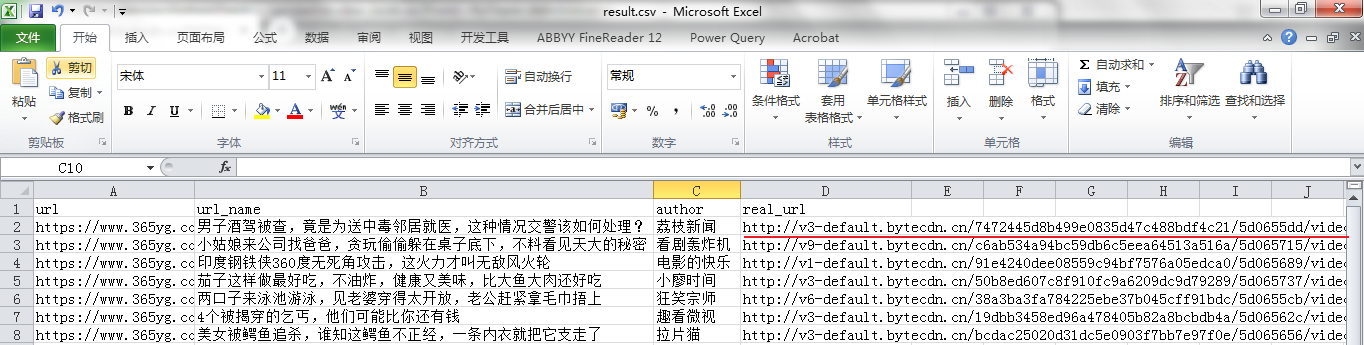
成功加载出视频!!说明已通过代码成功验证爬取构思是正确的。

结果回顾
通过以上的代码已能成功爬取阳光宽频(365yg.com)的视频,但仅有7个结果,而且爬取的real_url列的链接是有时效性,过一段时间就不能再访问,如何爬取更多视频(破解下滑加载视频)、如何更高效地爬取视频(爬得更多、更快)等就需要运用更多复杂的知识点、添加到上面的代码来实现功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号