

最近又重新拾起了,对python的热情.
贴个地址: https://github.com/d1y/lovepack/blob/master/kuaishou.py
前戏说明
因为我近乎癫狂的喜欢一个女孩三年,算上今年是第四年,但是可悲的我只是鱼塘的一"只"(注意我说的是动词)
我想联系她,我想找到她,但是我发现根本没有她的联系方式, 戏剧性的一幕,我有她的快手,所以每天都只有对着快手目睹佳人
但是我并不喜欢快手,这让我有点难堪,所以当时我就觉得做一个小玩意,用来下载他的视频和图片
技术相关
第一次有这个想法的时候,我在考虑用什么技术, nodejs | php | python 都可以
最终我考虑选择使用python来写这个小玩意.
我开始考虑从抓包手机端出手,但是发现这货的接口要研究好久,网上也没有现成的轮子,我就考虑在 web 端去抓取

哦,后面的ID需要传值
_api = 'https://live.kuaishou.com/profile/'
_headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
_r = requests.get(_api+id, headers=_headers)
在这里有一个小坑,如果你不传递 userAgent 就无法获取到内容
当拿到了html片段之后,就可以拿到想要的东西了

当然了,我一开始想要正则式的方式拿到需要的东西,我就花了几天的时间去学习这个

有点东西,我放弃了,最后采用的方案是使用: pyquery 而不是使用 bs4
from pyquery import PyQuery as pq
仔细的研究了一下这个web端口, 发现它这个fontsc用的太狠了
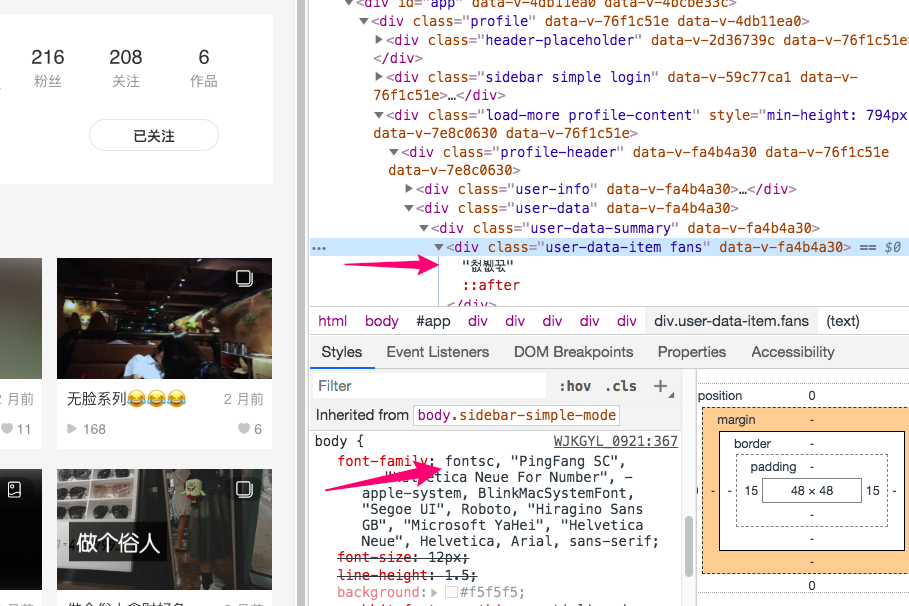
我就不下手了
我开始细细研究这些数据该怎么拿到,在我查看源码的时候我发现一个小东西

大部分数据都在这个对象里,当然这时候就要看一下这个对象到底是什么玩意了~
window.__APOLLO_STATE__ = {
"defa...":{}
}
细节部分就不给大家看了,就给大家看看我是怎么解决的:
import json
from pyquery import PyQuery as pq
def str2JSON( html, flag = False ):
'''
@tips { 先把拿到的数据转为`dict` }
@param {str} - html
@return {dict}
'''
_html = pq(html)
_con = _html('#app').next().next().text()
_firstStr = _con.index('{')
_lastStr = _con.rindex('}')
_code = _con[_firstStr:_lastStr]
_code = _code[: int( _code.rindex('}') )+1]
data_obj = json.loads(_code)['defaultClient']
if flag:
_title = _html('.profile-user-name').text()
return {
"title": _title,
"data": data_obj
};
return data_obj;
这样就拿到了python的一个dict,但是在拿到了dict之后,我们该怎么做呢?
当然是找到它的作品的key

通过分析,格式大致为:
_key = '$ROOT_QUERY.publicFeeds({"count":24,"pcursor":"","principalId":"'+id+'"})'
她的每一个作品那么就分别为:
data_obj = str2JSON(_r.text)
_lists = data_obj[_key]
_result = [];
for _index,_list in enumerate(_lists['list']):
_now = _key + '.list.' + str(_index)
_result.append(
data_obj[_now]
)
非常好,那么现在我们就拿到了作品的list,现在我们写一个小循环来依次下载
for list in lists:
_lists = list['imgUrls']['json'] # 注意这里!
for i,img in enumerate(_lists):
pass
如果你是跟着我的节奏来的话,到这里就应该出问题了,第一就是她的数据类型有几种
- video - 就是视频
- other - 其他
通过观察发现video资源还通过访问其他 url 才能获取到,所以这里要判断他们的类型,下面是伪代码:
type = 'video'
if (type == 'video'):
pass
else:
pass
还有就是你会发现拿到的图片是.webp格式,这格式是google开发在chrome的,有点小众,你得把它转换成 .jpg 这就要用到著名的 PIL,下面是伪代码
from PIL import Image
_im = Image.open(_file).convert('RGB')
_im.save( _now, 'jpeg' )
os.unlink(_file)
把.webp文件创建,然后通过这个包转换,接下来就删除 .webp 这个文件,嗯,对,这是正确姿势

接下来就到了说说视频怎么下载了

看到了吗,后面的那个 did 不要管,你会发现有两个超乱的字符串,相信你通过观察也能看出来这个第一个乱码就是 用户的 id 乱码,后面那个就是作品的id

你肯定想问这货从哪里得知,其实很简单
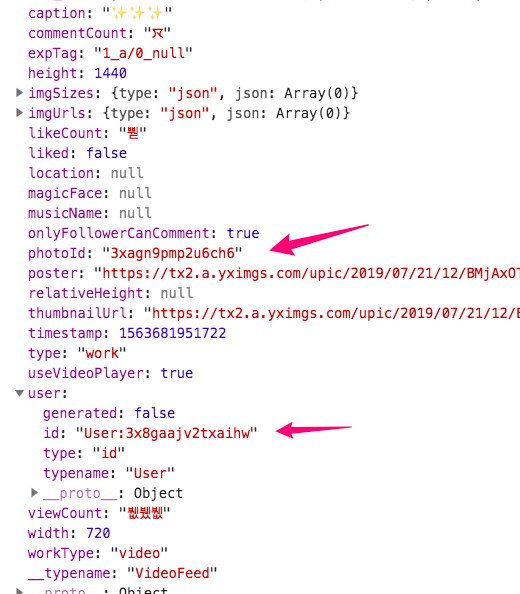
简单吧
fuck_str = 'User:xjkfljdslkjdfjds'
result = fuck_str.split(':')[1]
后面的拿到视频链接就不用我说了吧!
分享完咯~
用法
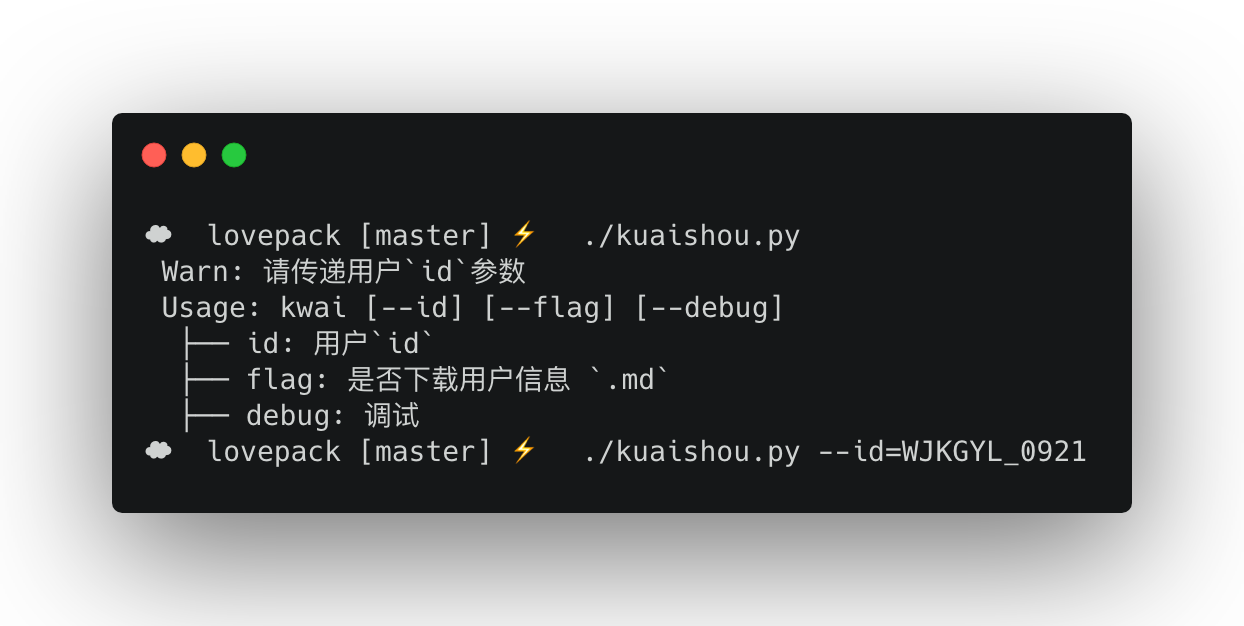
用法很简单
在你拿到对方的id之后, 你可以传入 --id=xxx' 这样,这里说一下 ``--flag 这个参数是用来生成用户的.md文件的, 还有 --debug 参数是用来测试的
注意啊, 所有生成的文件是在 ~/lovepack 下面的, 此处的 ~ 表示为 HOME PATH

 浙公网安备 33010602011771号
浙公网安备 33010602011771号