
Hadoop分布式集群搭建
一、 集群规划
| hostname | ip | hdfs | yarn |
| hadoop01 | 192.168.31.5 | namenode、datanode | nodemanager |
| hadoop02 | 192.168.31.6 | datanode | resourcemanager、nodemanager |
| hadoop03 | 192.168.31.7 | datanode、secondary namenodes | nodemanager |
二、环境准备
hadoop3.0.0
jdk1.8
1)3台虚拟机准备,配置静态ip,修改主机名,修改host映射
vi /etc/hosts
hadoop01 192.168.31.5
hadoop02 192.168.31.6
hadoop03 192.168.31.7
2)关闭3台机器的防火墙
systemctl status firewalld 查看防火墙状态
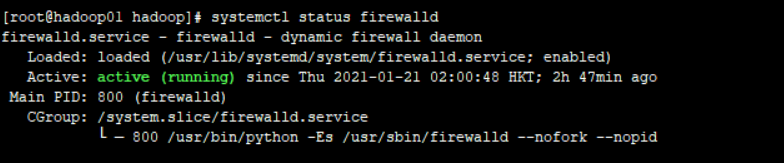
systemctl stop firewalld 关闭防火墙

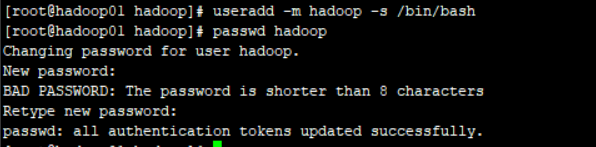
3)创建hadoop账户
useradd -m hadoop -s /bin/bash 创建hadoop账户
passwd hadoop 设置密码,我这里设置的是123456
4)配置hadoop账户拥有root权限
修改/etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示

注意/etc/sudoers 文件只是可读的,要修改内容,可先将该文件添加可写权限,然后编辑
hadoop ALL=(ALL) ALL
保存
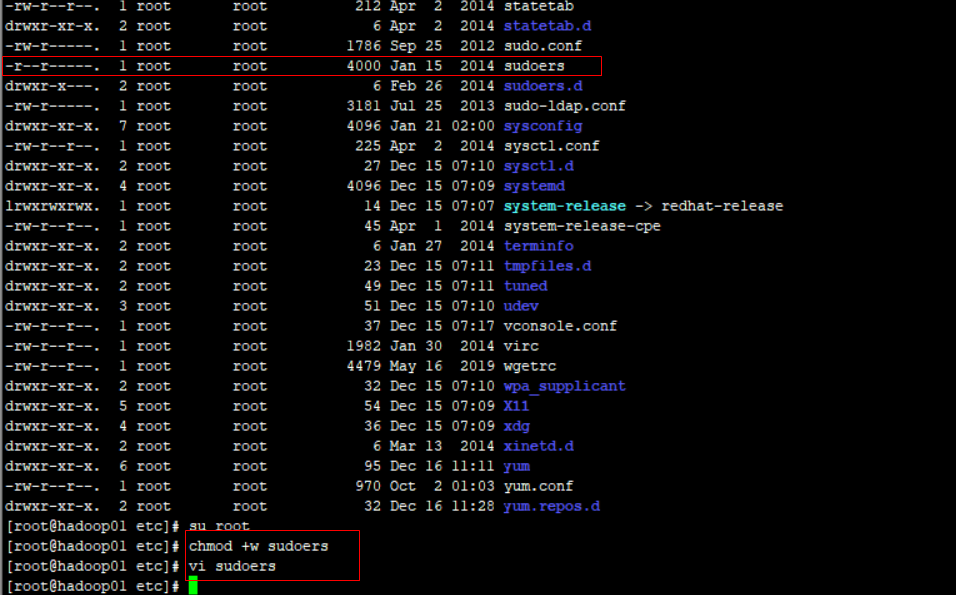
保存完毕后,再将文件权限修改回去即可
chmod -w /etc/sudoers
5) 安装jdk
先卸载现有的JDK
rpm -qa | grep java #查询是否安装JDK
rpm -qa | grep java | xargs rpm -e --nodeps #卸载所有带java关键字的包
① 自行下载安装包手动安装,可自定义安装目录
将下载好的jdk上传到服务器上,解压重命名为jdk1.8

② 在/etc/profile文件中设置JAVA_HOME

保存,是文件生效
source /etc/profile
测试 : java -version

6)配置ssh
生成秘钥:ssh-keygen -t rsa 直接回车即可
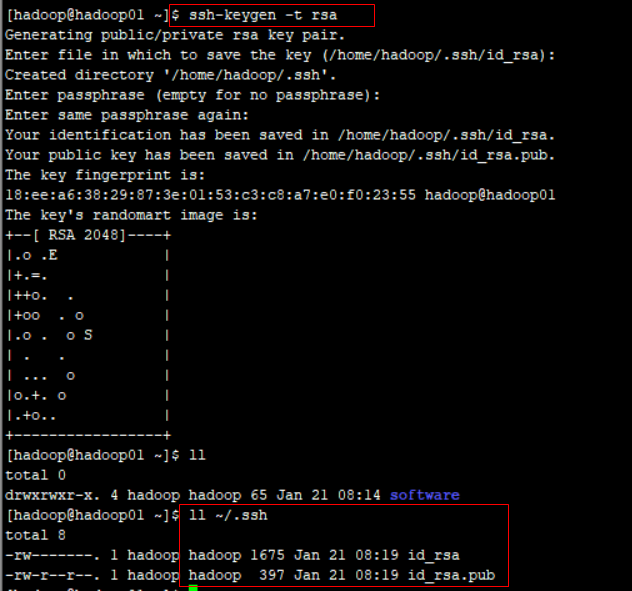
将公钥写入authorized_keys文件:
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys

测试 ssh hadoop01

hadoop-master可以无密码登录自己了
将hadoop-master的公钥传送到所有的slave上,实现hadoop-master无密码登陆到所有slave上
scp authorized_keys hadoop@hadoop02:~/.ssh/
scp authorized_keys hadoop@hadoop03:~/.ssh/
测试 ok
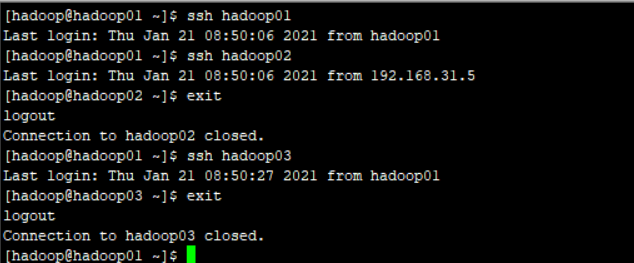
同样
设置hadoop02 能够ssh hadoop01、hadoop03
设置hadoop03能够ssh hadoop01、hadoop02
三、hadoop相关文件配置
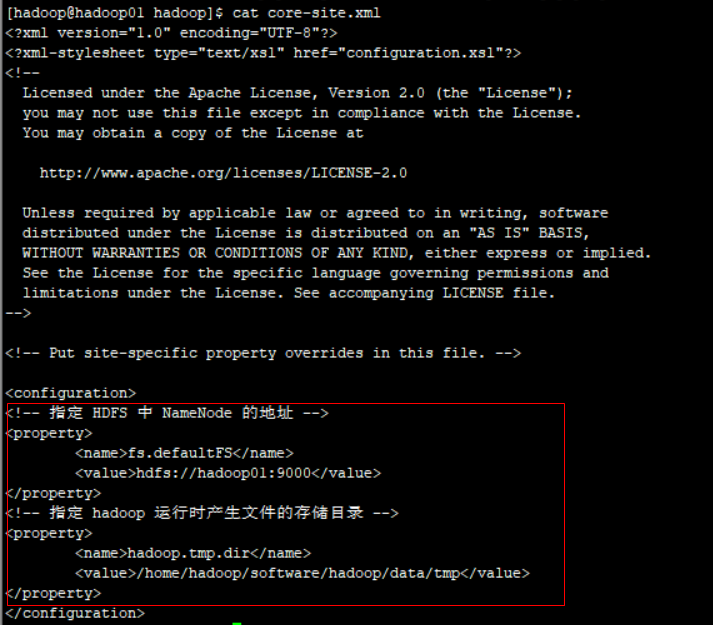
1)core-site.xml
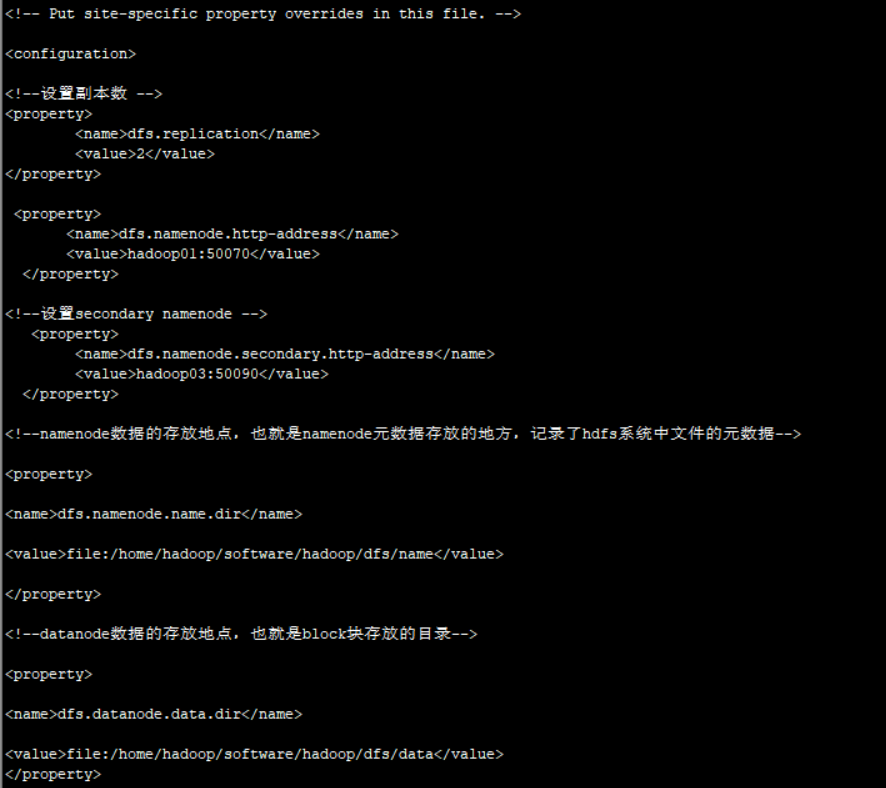
2)hdfs-site.xml
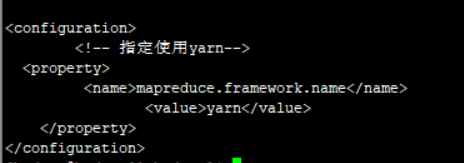
3)mapred-site.xml
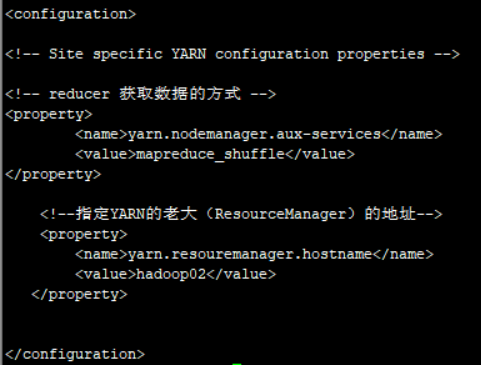
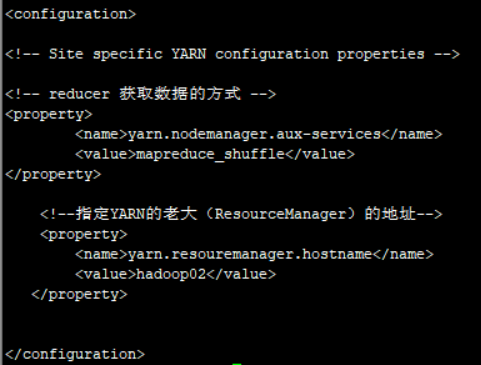
4)yarn-site.xml
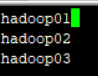
5)workers
6)hadoop-env.sh、mapred-env.sh、yarn-env.sh中配置JAVA_HOME
export JAVA_HOME=/home/hadoop/software/jdk1.8
四、文件分发
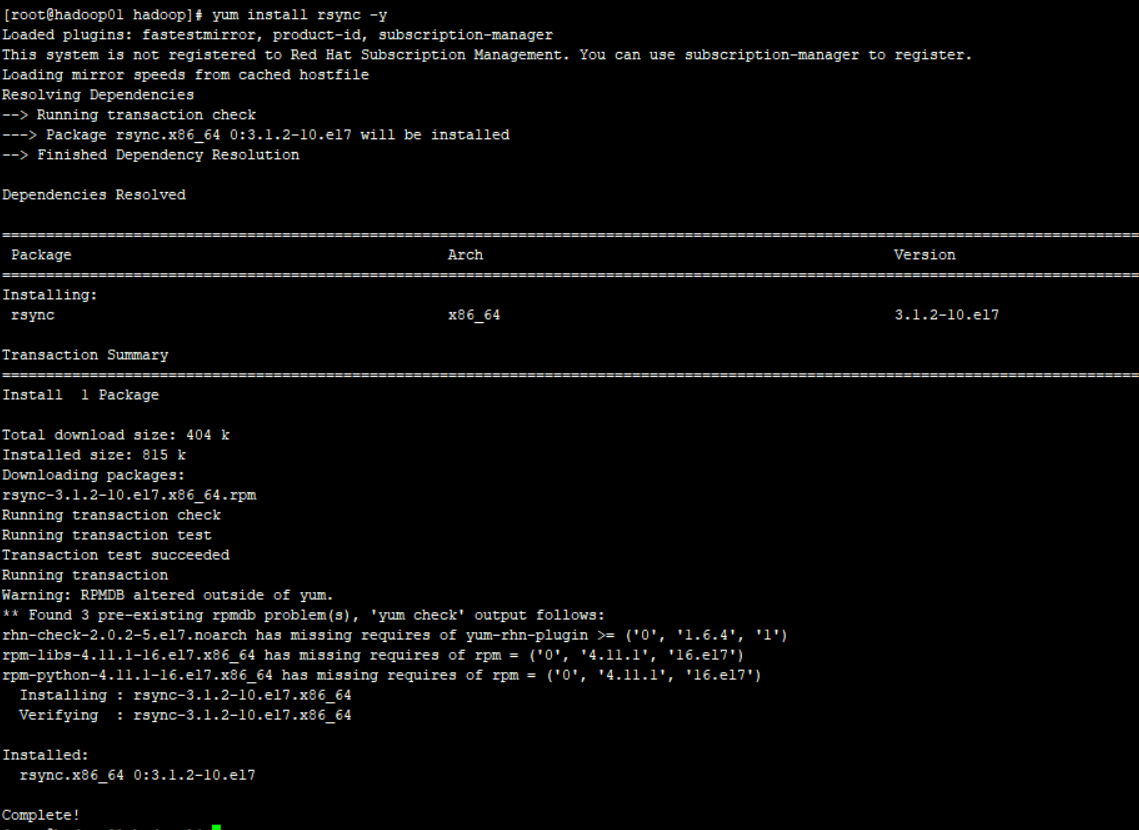
① 安装rsync
切换到root账号,yum install rsync -y
注意:3台机器上都要安装rsync
②、编写同步脚本
mdkir script
cd script
vi xrsync.sh
#!/bin/sh
# 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args...;
exit;
fi
# 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
# 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
# 获取当前用户名称
user=`whoami`
# 循环
for((host=2; host<=3; host++)); do
echo $pdir/$fname $user@hadoop0$host:$pdir
echo ==================hadoop0$host==================
rsync -rvl $pdir/$fname $user@hadoop0$host:$pdir
done
chmod +x xrsync.sh
文件分发
sh xrsync.sh /home/hadoop/software/hadoop
五、配置 hadoop环境变量
vi ~/.bash_profile
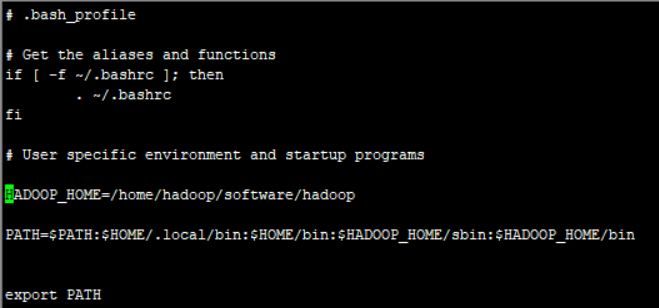
source ~/.bash_profile
分发到另外两天机器上,同时使之生效
六、格式化namenode
在hadoop01上 : bin/hadoop namenode -format 格式化namenode,
七、启动集群
在hadoop01上 :
sbin/start-dfs.sh 启动hdfs
在hadoop02上启动 yarn
sbin/start-yarn.sh
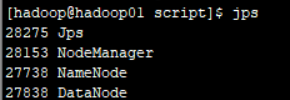
查看启动状态
hadoop01:
hadoo02:
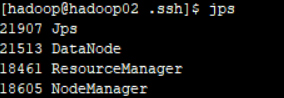
hadoop03:
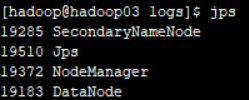
安装成功
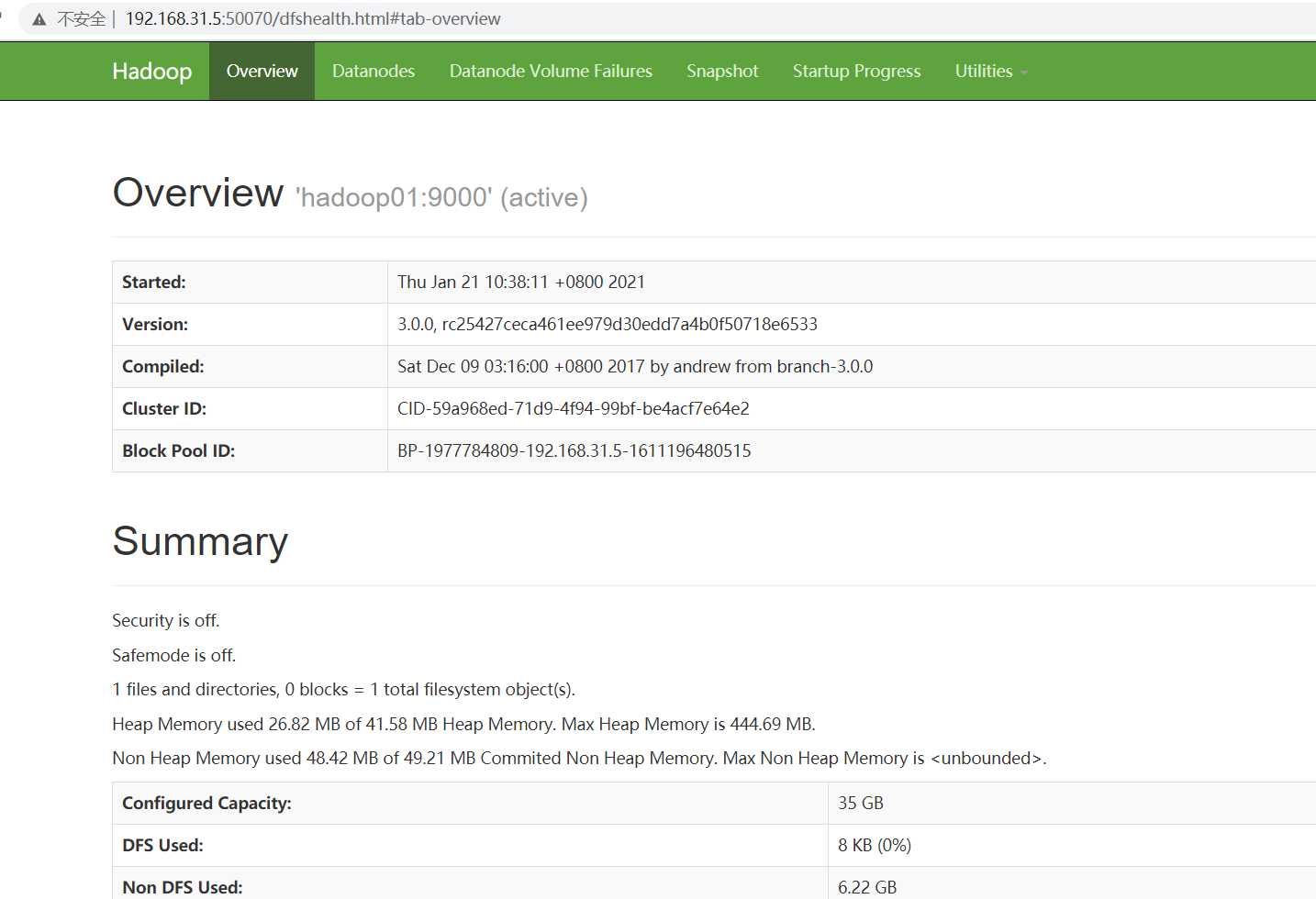
测试文件上传:hadoop fs -put ~/software/script/xrsync.sh /

数据上传成功!
注:
启动hadoop集群脚本 start-hadoop.sh

停止hadoop集群脚本 stop-hadoop.sh


 浙公网安备 33010602011771号
浙公网安备 33010602011771号