
pandas数据连接合并
一、concat(), append()默认用来纵向连接DataFrame对象
1)df1和df2相同列合并
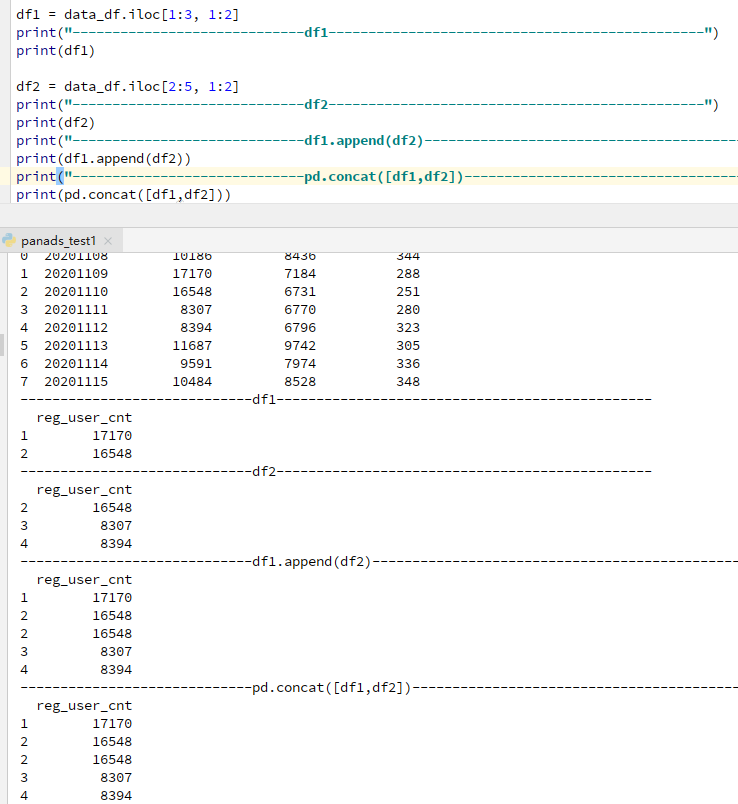
df1.append(df2) 等价于 pd.concat([df1,df2] 相当于sql中的union all
图中可以看出合并后出现了重复行,可以使用df.drop_duplicates() 删除重复行
print(df1.append(df2).drop_duplicates()) 执行后输出结果:
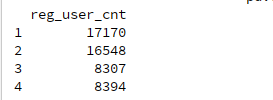
另外我们可以看到合并之后的数据行索引还是以前df的索引值,要想使新生成的df索引从0开始,可以添加: ignore_index=True
print(df1.append(df2,ignore_index=True)) 或者 print(pd.concat([df1,df2],ignore_index=True))
运行结果如下

2)df1和df2不同列合并
df1.append(df2) 同样等价于pd.concat([df1,df2])
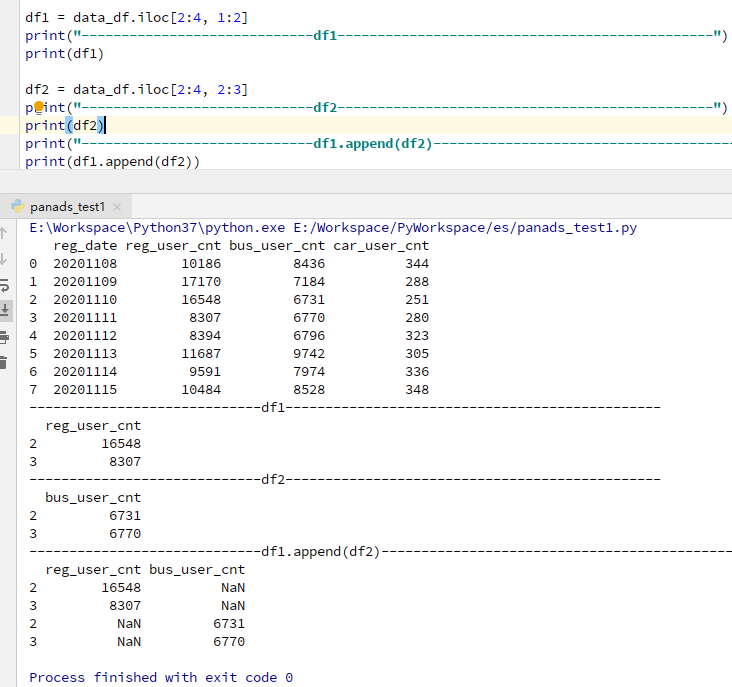
可以看到上图中,不同列时数据合并,使用了NaN进行缺失值填充
二、merge()的默认操作是横向连接两个DataFrame对象
参考我以前的 https://www.cnblogs.com/kopao/p/13527710.html
另详解append,concat,merge可参考 :https://zhuanlan.zhihu.com/p/70438557?from_voters_page=true

 浙公网安备 33010602011771号
浙公网安备 33010602011771号