
pandas常见操作
pandas 适用于处理以下类型的数据:
- 与 SQL 或 Excel 表类似的,含异构列的表格数据;
- 有序和无序(非固定频率)的时间序列数据;
- 带行列标签的矩阵数据,包括同构或异构型数据;
- 任意其它形式的观测、统计数据集, 数据转入 Pandas 数据结构时不必事先标记
pandas的主要数据结构为:一维数据Series(带标签的一维同构数组)和二维数据DataFrame(带标签的二维的异构表格)。pandas基于numpy开发,可以与其他科学计算支持库完美集成。
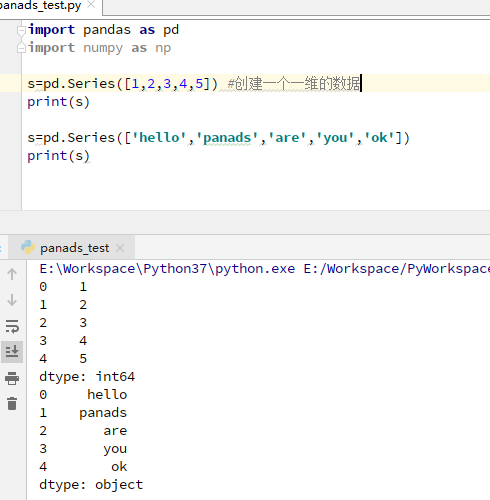
1)创建Series,Series有着相同的数据类型
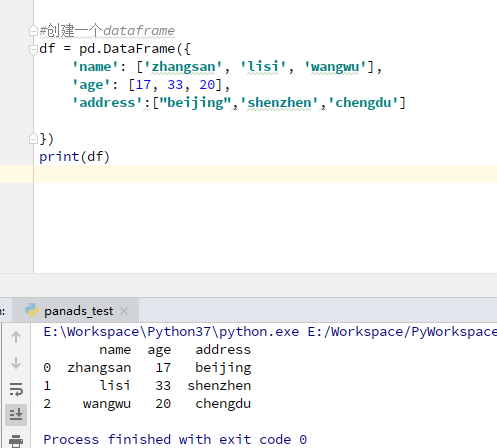
2)创建DataFrame,DataFrame列有着不同的数据类型
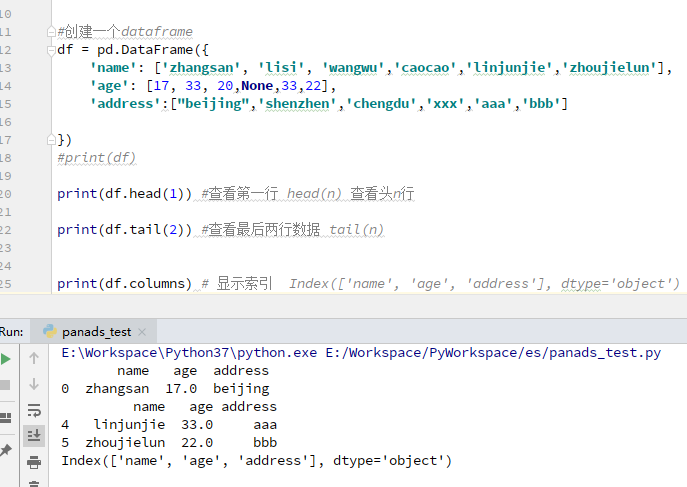
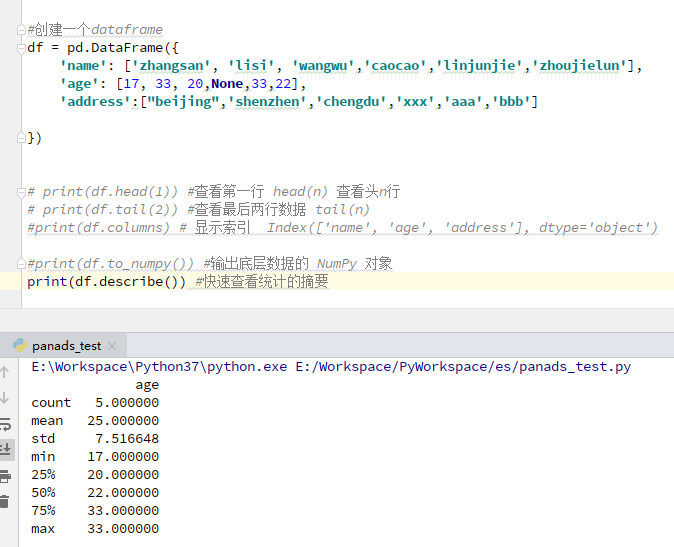
3)查看数据
df.head(n) #查看头部,默认查看前5行
df.tail(n) #查看尾部,默认查看后5行
df.columns #显示索引
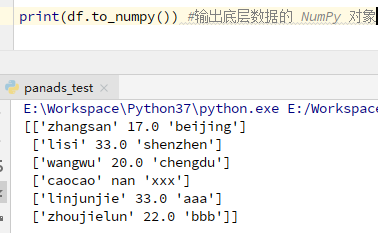
df.to_numpy() #输出底层的Numpy对象 输出不包含索引和列标签
df.describe()快速查看统计的摘要
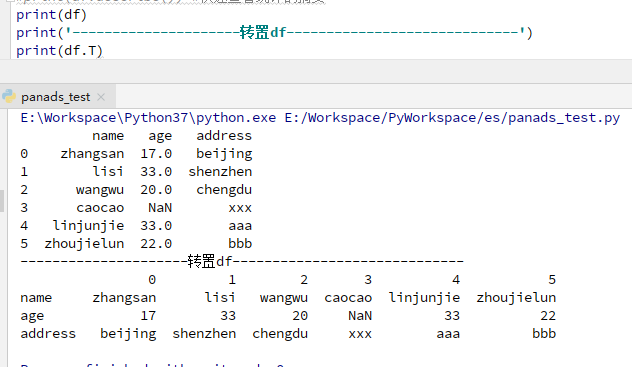
4) 转置
df.T #对df进行转置
DataFrame常用的属性:
df.size # 返回df中元素的个数
df.shape[0], df.shape[1] #返回df的行数和列数 df.shape为df的维度元组
df.dtypes #返回df中的数据类型
df.empty #df是否为空,为空时为True,否则为False
df.ndim #返回df的维度,默认为2维
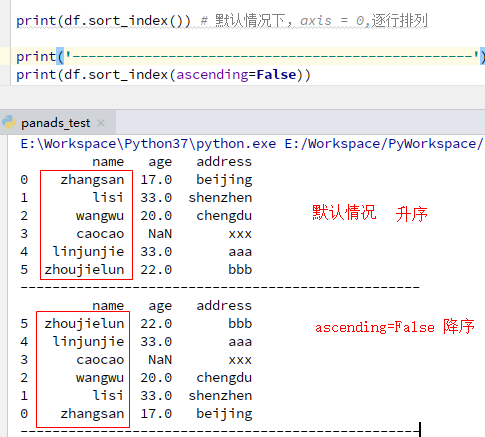
5)排序
按标签排序:使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序
按行排序
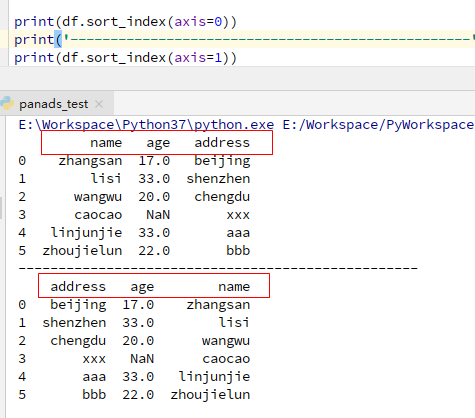
按列排序
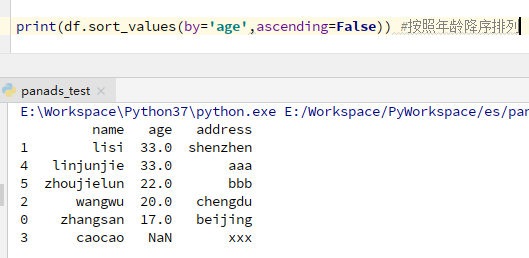
按值排序:
df.sort_values(by='age',ascending=False)
6)数据选择
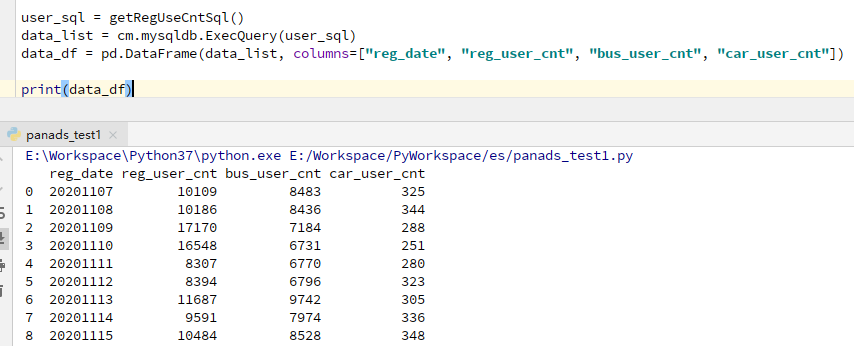
将list转成dataFrame:
data_df = pd.DataFrame(data_list, columns=["reg_date", "reg_user_cnt", "bus_user_cnt", "car_user_cnt"])
print(data_df.loc[:]) 等价于print(df) #查看所有数据
![]()
loc()主要基于标签(label)的,包括行标签(index)和列标签(colums),即行名称和列名称,可以使用def.loc[index_name, col_name]选择指定位置的数据,主要用法有:
- 单个标量标签,如果
.loc中只有单个标签,那么选择的是一行。如:df.loc['a']选择的是 index 为’a’的一样。 - 标签列表,如:
df.loc[['a', 'b', 'c']],同样只选择行。 - 切片对象,与通常的 python 切片不同,在最终选择的数据数据中包含切片的 start 和 stop。如:
df.loc['c' : 'h']即包含’c’行,也包含’h’行。 - 布尔数组,用于筛选符合某些条件的行,如:
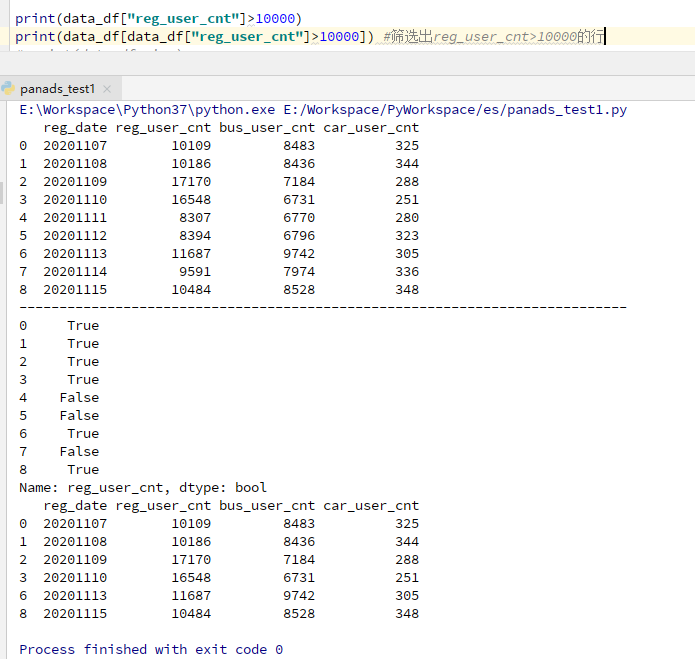
df.loc[df.A>0.5]筛选出所有’A’列大于0.5的行
iloc() 是基于整数的索引,利用元素在各个轴上的索引序号进行选择,序号超过范围产生IndexError,切片时允许序号超过范围。
各种访问方式如下 :
- 整数,与
.loc相同,如果只使用一个维度,则对行选择,小标从 0 开始。如:df.iloc[5],选择第 6 行。 - 整数列表或者数组,如
df.iloc[[5, 1, 7]],选择第 6 行, 第 2 行, 第 8 行。 - 元素为整数的切片操作,与
.loc不同,这里下标为 stop 的数据不被选择。如:df.iloc[0:3], 只包含 0,1,2行,不包含第 3 行。 - 使用布尔数组进行筛选,如
df.iloc[np.array(df.A>0.5)],df.iloc[list(df.A>0.5)]
df.loc[],df.iloc[]的区别如下:df.loc[]只能使用标签索引,不能使用整数索引,通过便签索引切边进行筛选时,前闭后闭。df.iloc[]只能使用整数索引,不能使用标签索引,通过整数索引切边进行筛选时,前闭后开。
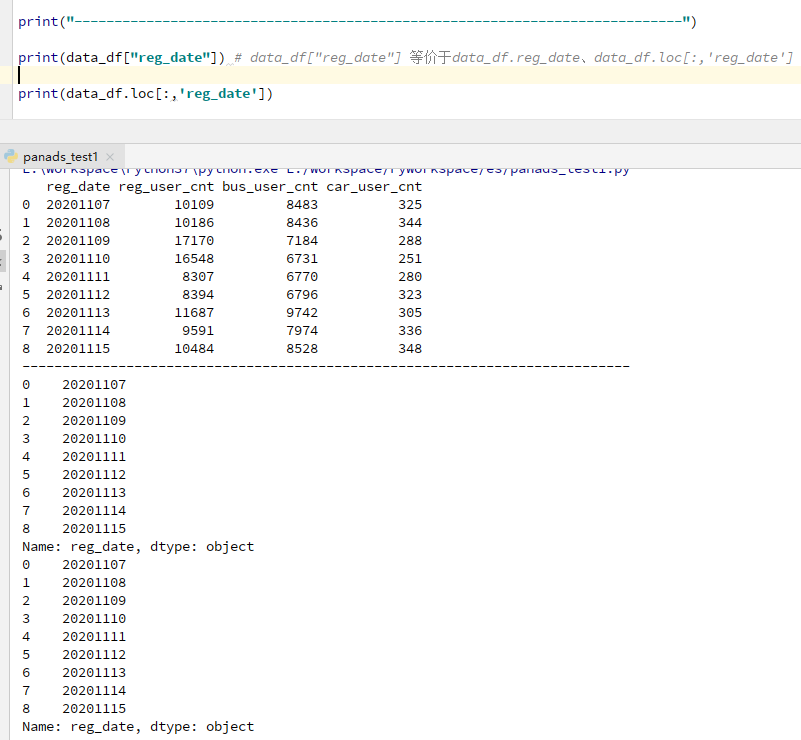
① 选择单列
方法:
data_df["reg_date"] 、data_df.reg_date、data_df.loc[:,'reg_date']
注:使用df.loc[]进行数据筛选,方括号内必须有两个参数,第一个参数是对行进行筛选,第二个参数是对列进行筛选,两个参数用逗号隔开
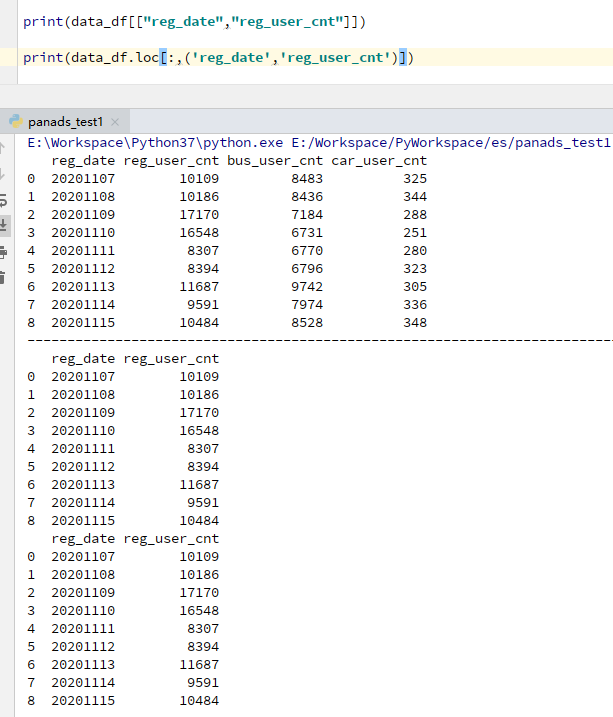
②选择多列
data_df[["reg_date","reg_user_cnt"]]
data_df.loc[:,('reg_date','reg_user_cnt')] #经过测试('reg_date','reg_user_cnt') 进行列的选择时,使用元组和列表都可以,['reg_date','reg_user_cnt']
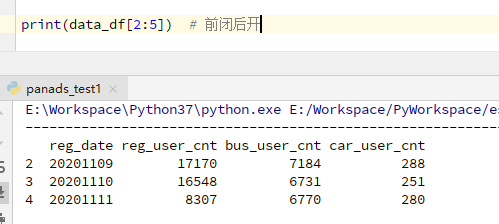
③数据切片
[行,列] #行列之间用逗号隔开
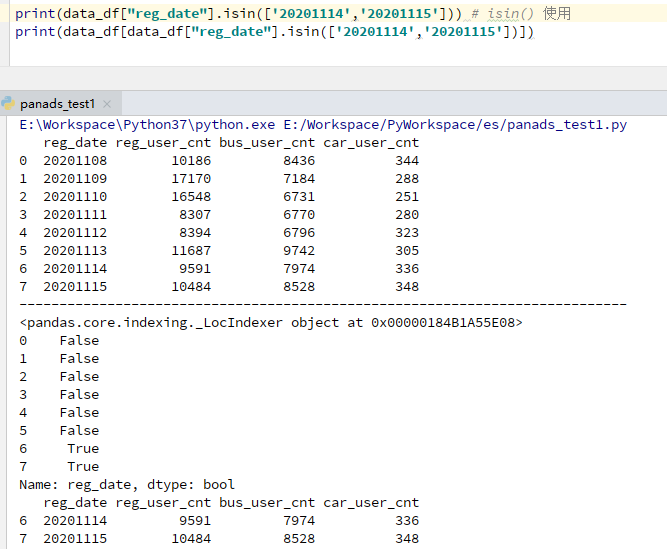
数据筛选:
缺失值,Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。
df1.dropna(how='any') #删除所有含缺失值的行
df1.fillna(value=5) #填充所有的缺失值
更多详细介绍可参考:
https://geek-docs.com/pandas/pandas-tutorials/pandas-indexes-and-select-data.html 极客教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号