Kettle读取mysql数据存入Hive分区表中,使用Impala查询

操作步骤
1)TmpBstAggZwTktModelD
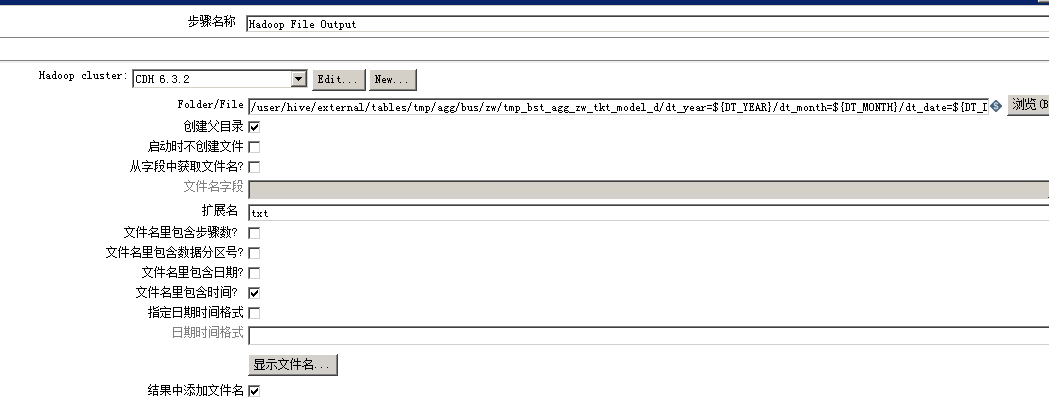
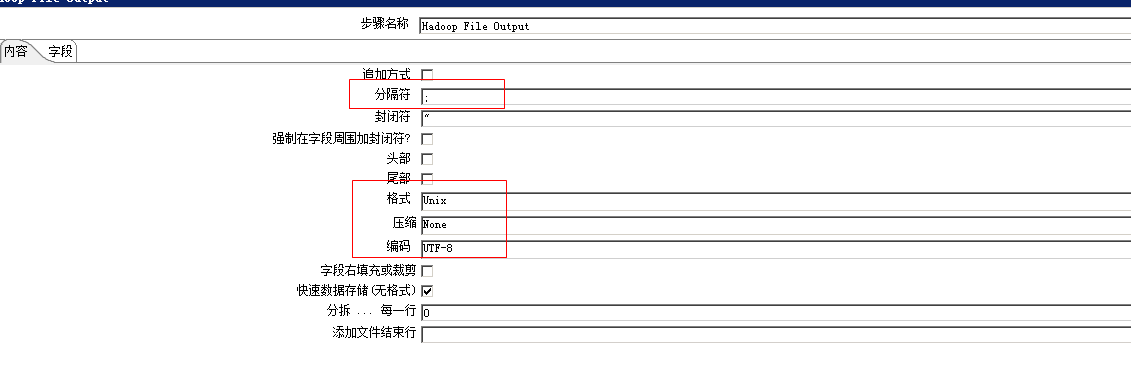
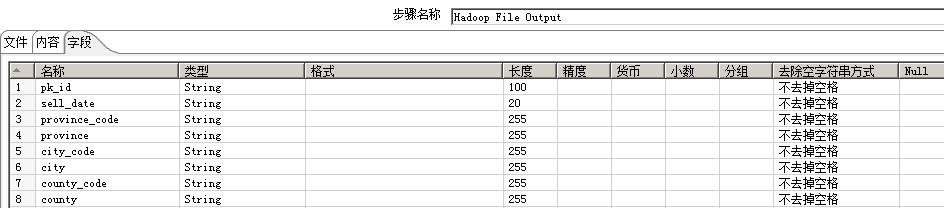
按天读取Mysql表数据bst_agg_zw_tkt_model_d,存入hive临时表tmp_bst_agg_zw_tkt_model_d(临时表采用txt格式,按年月日进行分区)

2)HiveBstAggZwTktModelD
连接hive,将临时表tmp_bst_agg_zw_tkt_model_d的数据加载到bst_agg_zw_tkt_model_d(采用orc压缩,按年月日进行分区)
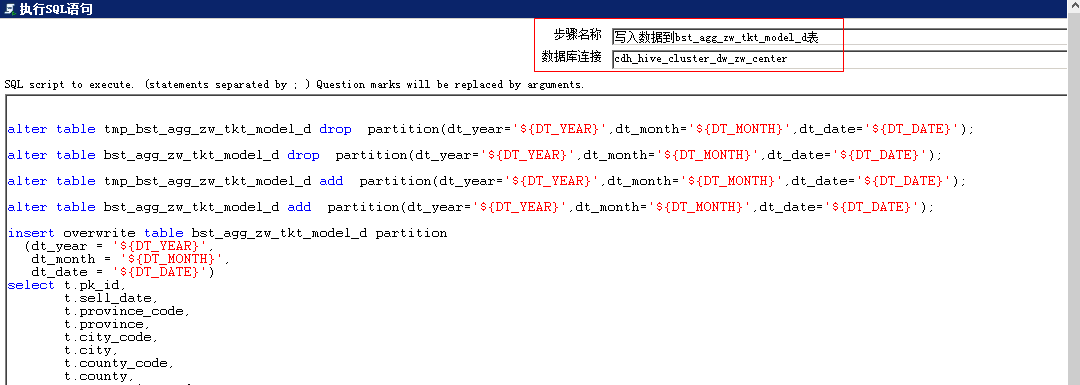

3)连接impala,刷新bst_agg_zw_tkt_model_d表

20200728更新
上面存在的问题:
Hadoop File Output 组件设置如下
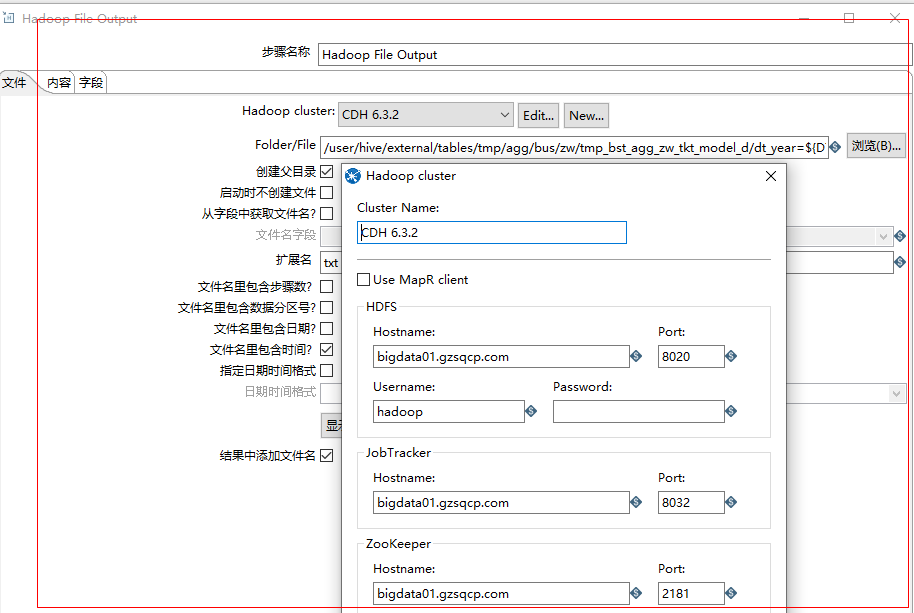
Hadoop File Output ip写死为bigdata01,HDFS HA下,bigdata01,bigdata02两台机器会切换成active,standby状态,如果kettle中Hadoopcluster组件写死一个ip,比如bigdata02(当前bigdata02状态为active),当bigdata02状态变成standby时,输出将会报错

目前解决办法:
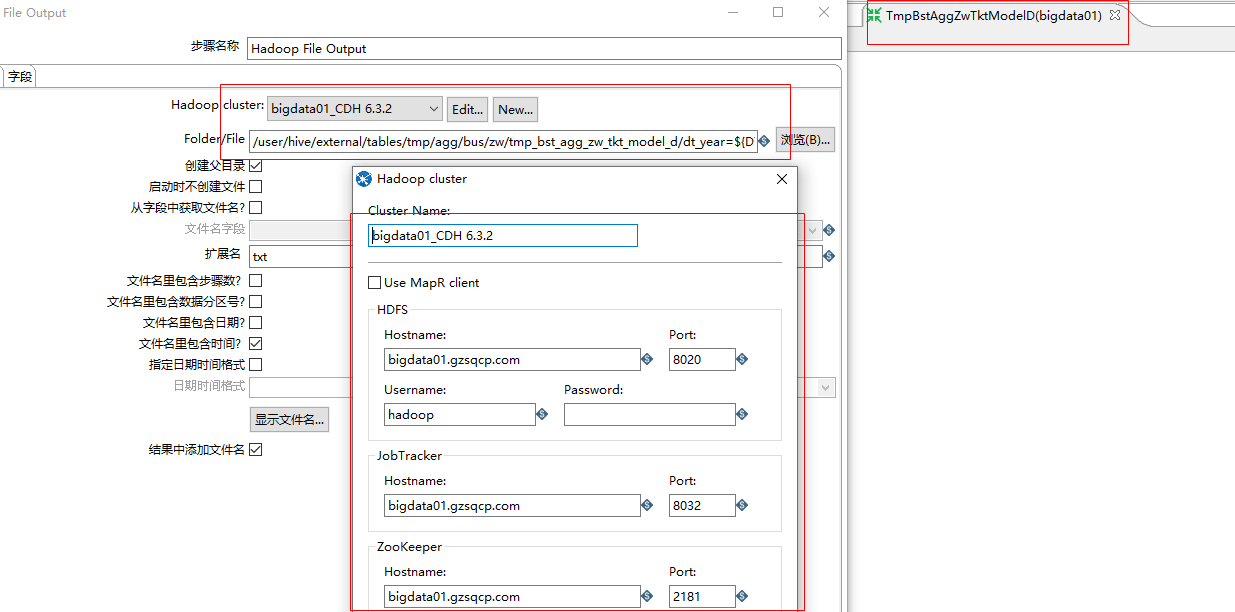
TmpBstRptYqTktSellHisD(bigdata01)
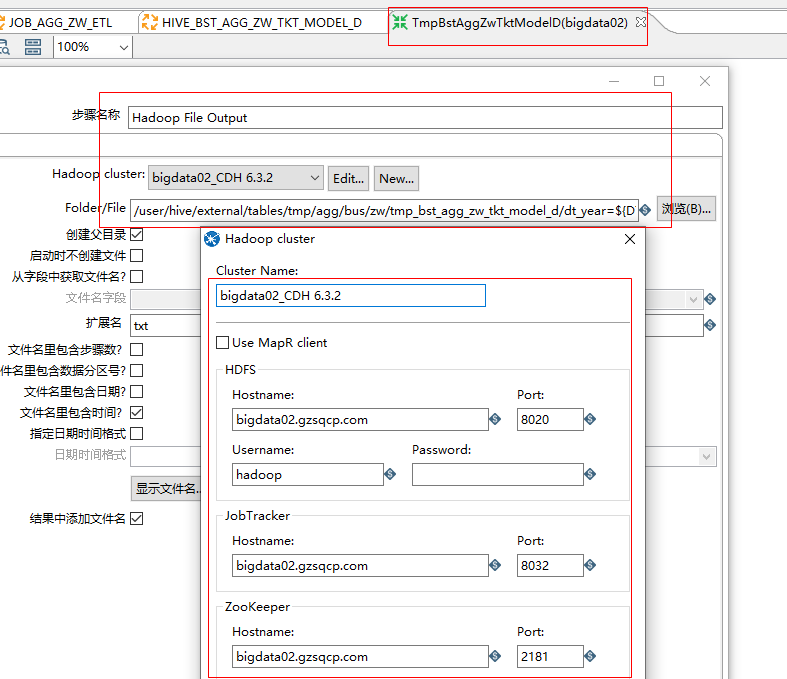
TmpBstAggZwTktModelD(bigdata02)
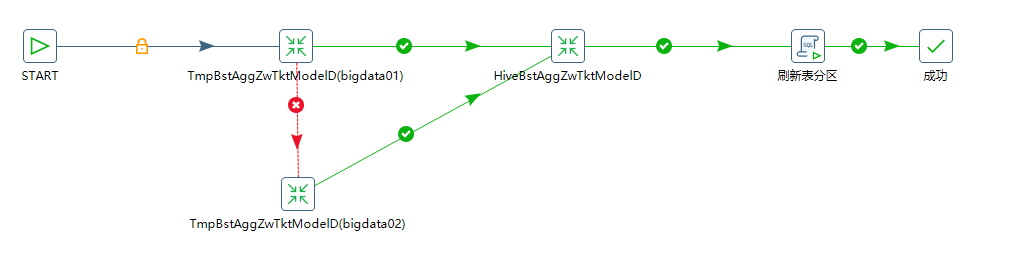
任一时刻,bigdata01,bigdata02只会存在一个状态为active
当TmpBstAggZwTktModelD(bigdata01)执行失败后(说明bigdata01状态为standby,bigdata02为active),会执行TmpBstAggZwTktModelD(bigdata02),HiveBstAggZwTktModelD->刷新表分区
当TmpBstAggZwTktModelD(bigdata01)执行成功后(说明bigdata01状态为active,bigdata01为standby),直接依次执行HiveBstAggZwTktModelD->刷新表分区
办法虽笨,但还是能解决问题,若后续有更好的处理方法,再更进

 浙公网安备 33010602011771号
浙公网安备 33010602011771号