我想统计某变量中含有某字节的数据,如audfirm字段中含“有限公司”的数据数量,为何用“*有限公司*”不管用?
d*表示所有d字母开头的变量(var),而不是变量值
统计某字段/变量中的数据含有的文字:正则表达式
我想统计某变量中含有某字节,如audfirm字段中含“有限公司”的数据数量:
count if regexm(audfirm1, "有限责任") == 1

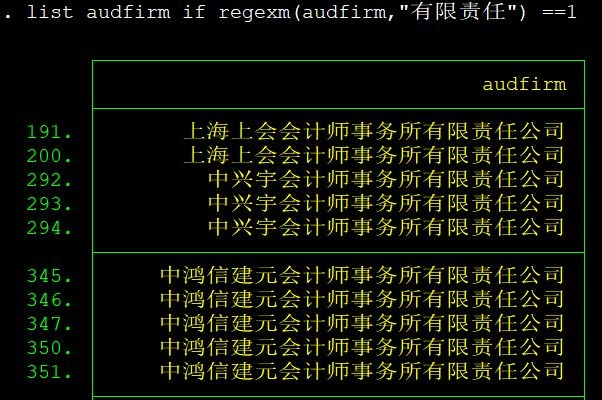
我想列出变量audfirm中含有“有限公司”数据:
list audfirm if regexm(audfirm,"有限责任") ==1
涉及正则表达式(regular expression)中的元字符
|
元字符
|
含义
|
举例
|
|
\
|
后向引用,后面跟正则表达式中的某个元字符,表示匹配该符号。类似于转义。
|
\\匹配\;\-匹配-。
|
|
^
|
在表达式的开头位置,表示接下来的表达式所要匹配的内容位于字符串的开始的位置。
|
^B表示以B开头;^\(表示以(开头
|
|
$
|
在表达式的结尾位置,表示钱买你的表达式所要匹配的内容位于字符串结尾的位置。
|
[0-9]$表示以数字结尾
|
|
*
|
表示将前一个字符或子表达式匹配任意次数,可以为0次。
|
XY*可以匹配X,也可以匹配XY,XYY,XY.....Y。(即把*前面的Y匹配 0-n 次)
|
|
+
|
表示将前一个字符或子表达式匹配至少1次。
|
XY+可匹配XY,XYY,XY.....Y,但不可匹配X。
|
|
?
|
表示将前一个字符或子表达式匹配0次或1次。
|
XY?可匹配X或XY
|
|
{n}
|
n为一个非负整数,表示将前一个字符或子表达式匹配n次。
|
XY{2}匹配XYY;只能用于以ustr开头的4个正则表达式的字符串函数中
|
|
.
|
表示可以匹配任意字符
|
.*可以匹配任意字符或者不匹配任何字符。
|
|
()
|
创建一个子表达式,可以提取或者替换括号内的子表达式对应的字符串
|
^\(([0-9]+)\) (.*)可拆成^,\(,([0-9]+),\),(.*),其中,([0-9]+),(.*)为子表达式
|
|
-
|
指定一个范围
|
a-z:字母a到字母z范围的小写字母;A-Z:字母A到字母Z范围的大写字母;0-9:数值0-9范围内的数字。
|
|
[]
|
方括号内的字符之一被用来进行匹
|
[a-z]可以匹配a-z范围内的任意小写字母
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号