结对作业二
一、作业基本信息
| 这个作业属于哪里 | 2021春软件工程实践 S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 221801432 ; 221801429 |
| 这个作业的目标 | 实现顶会热词统计、Web项目的部署 |
| 其他参考文献 | Flask,SQLAlchemy相关文档手册 |
二、GitHub仓库链接和代码规范链接
三、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 480 | 500 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 20 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 50 | 60 |
| • Coding | • 具体编码 | 700 | 800 |
| • Code Review | • 代码复审 | 40 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 40 | 40 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1520 | 1710 |
四、项目访问链接
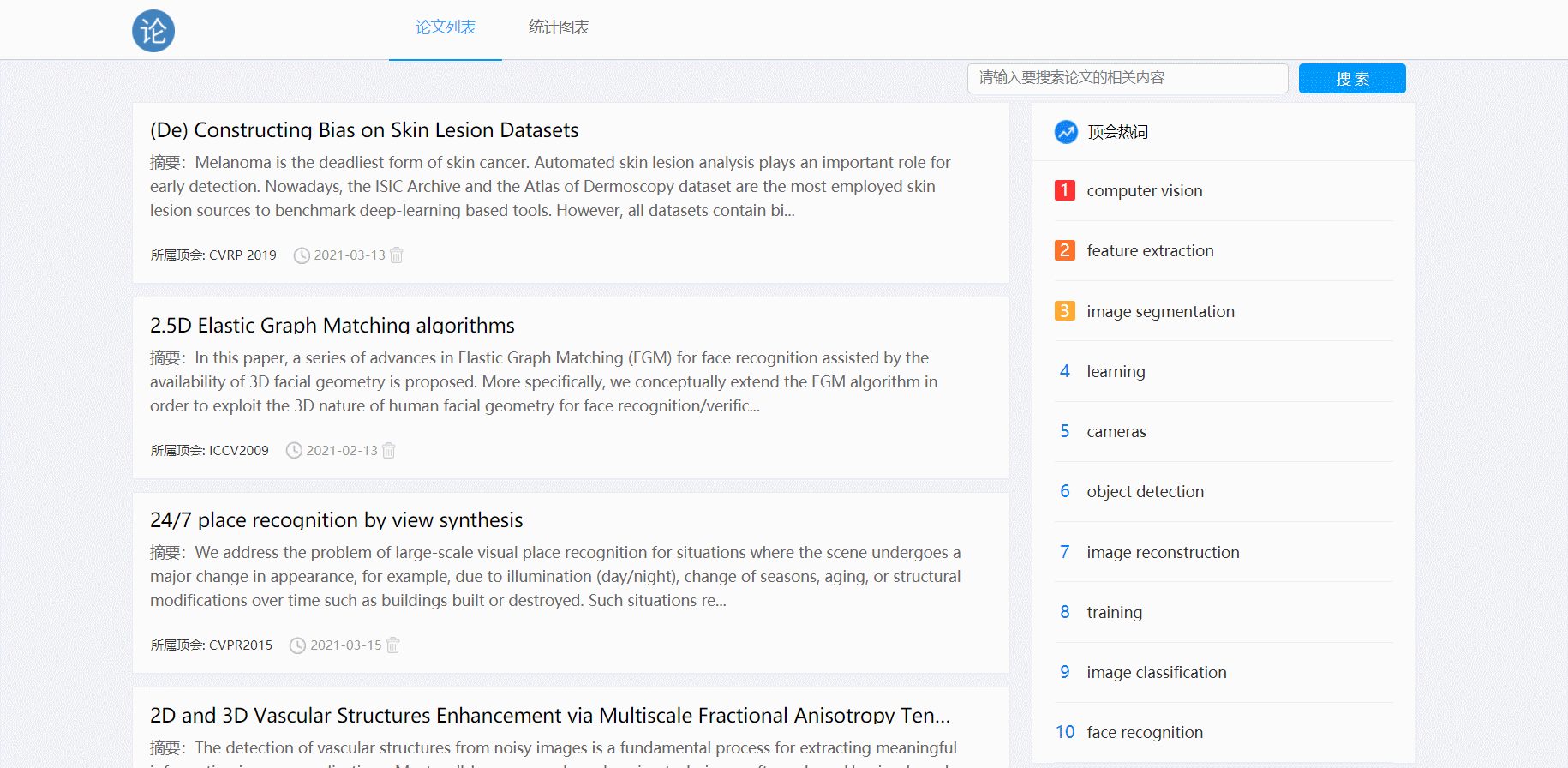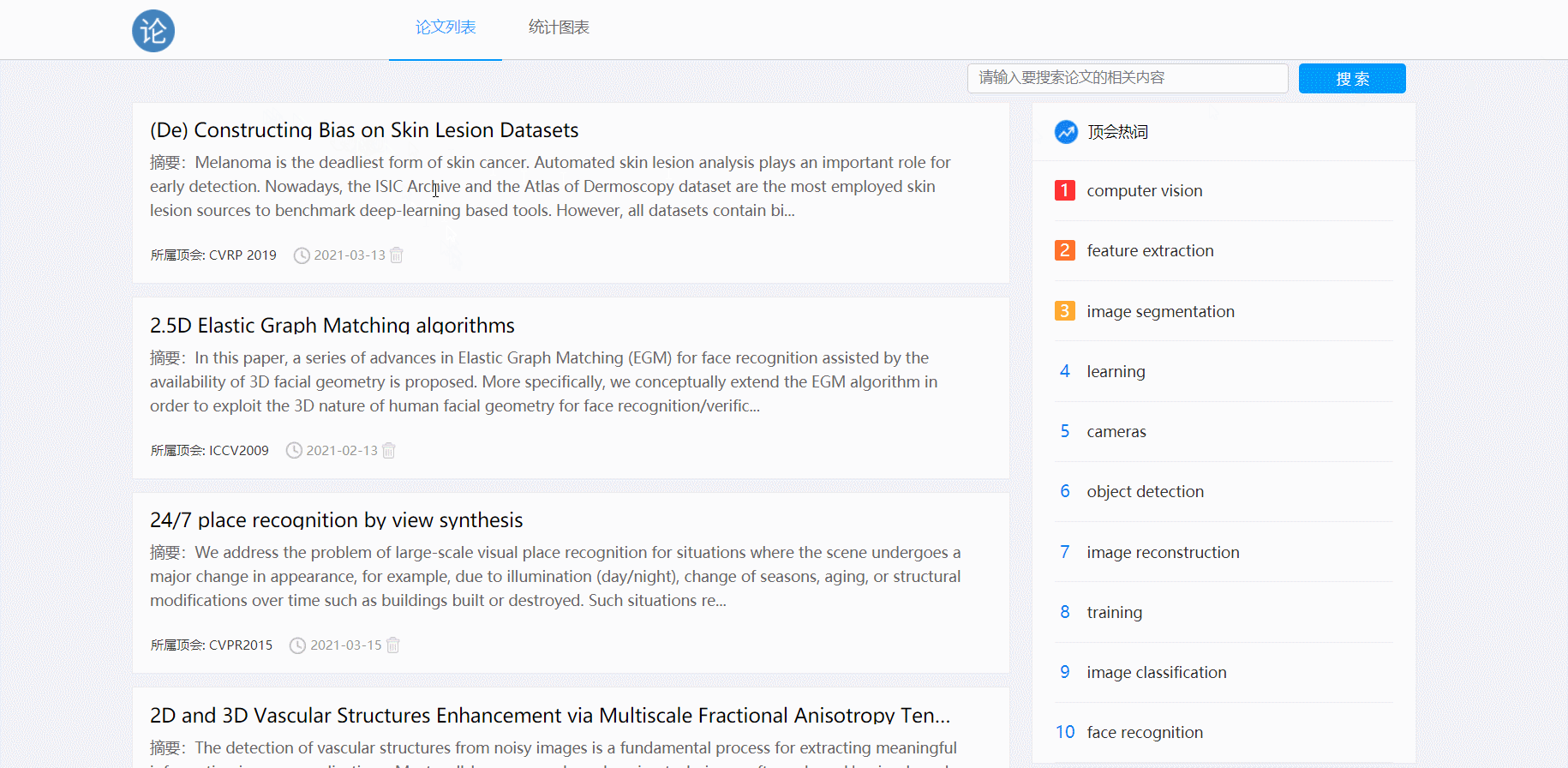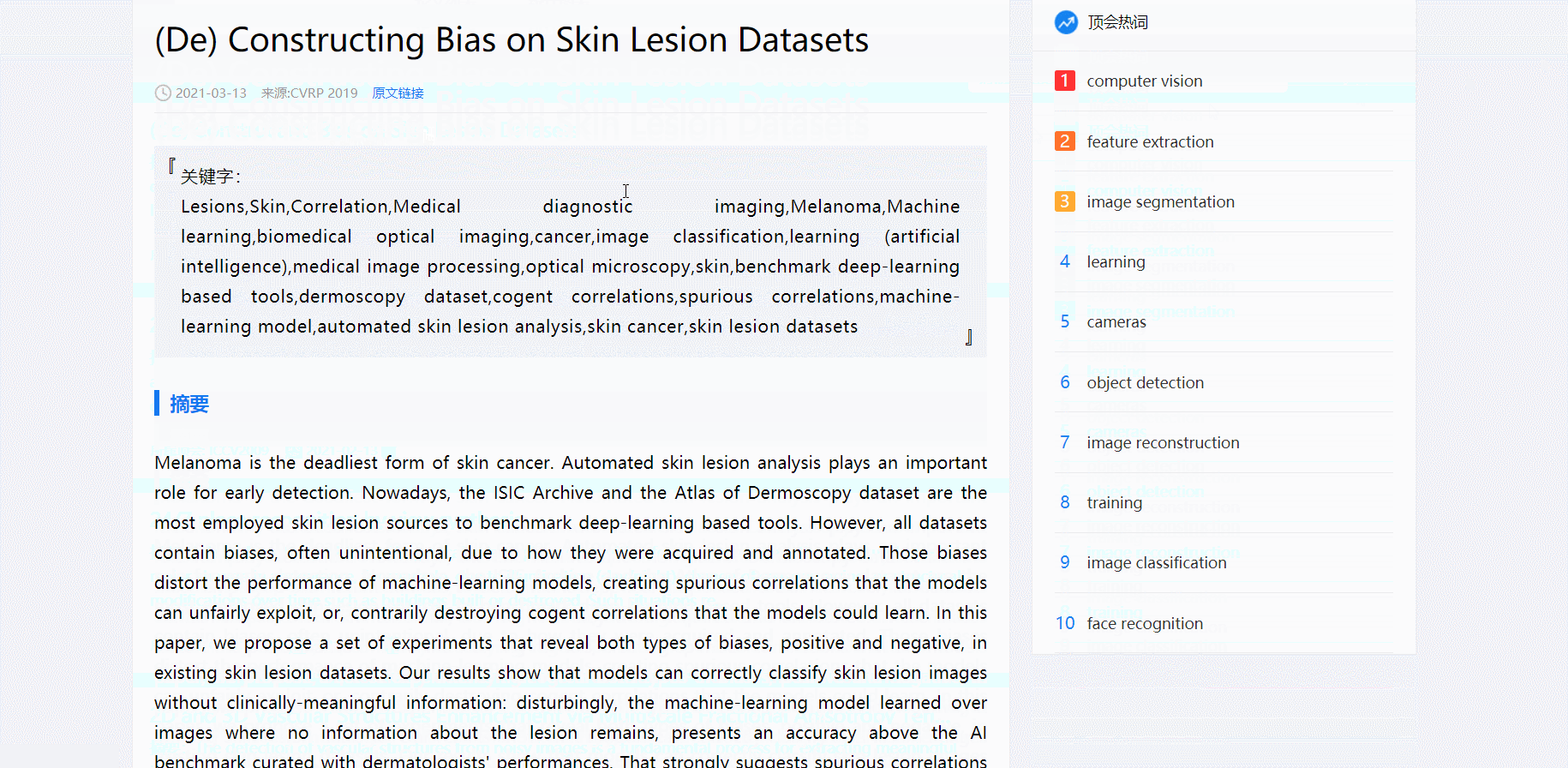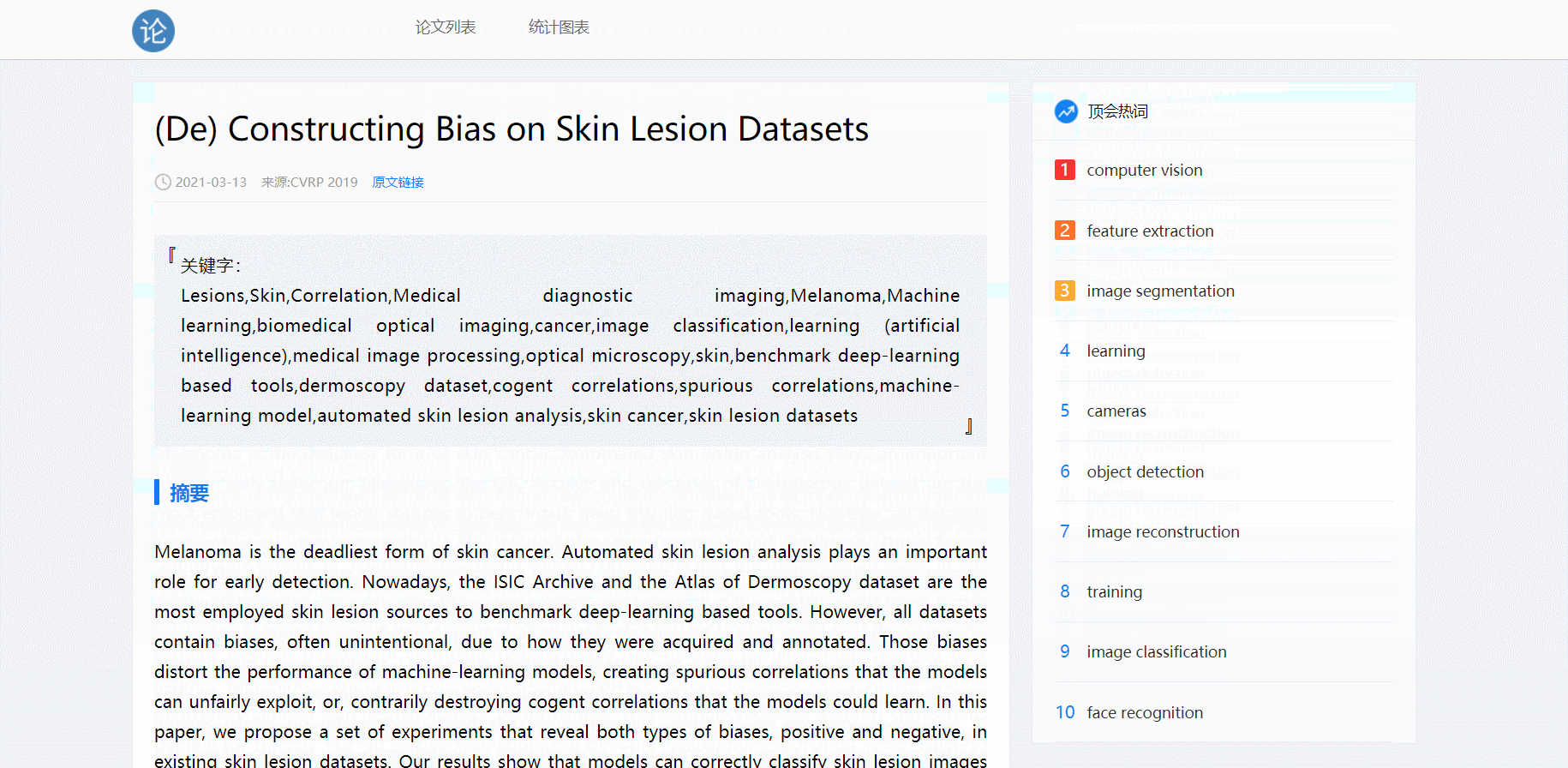
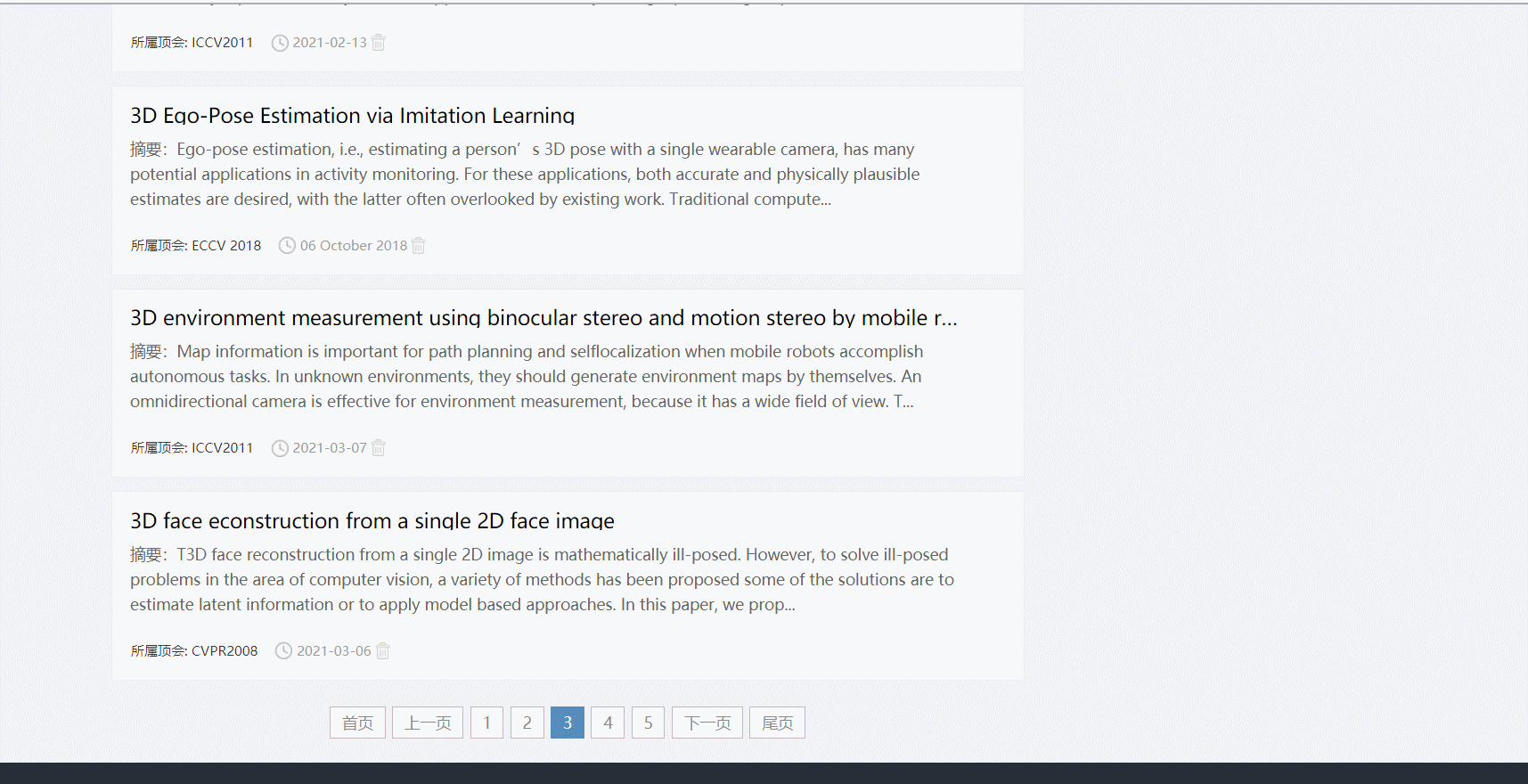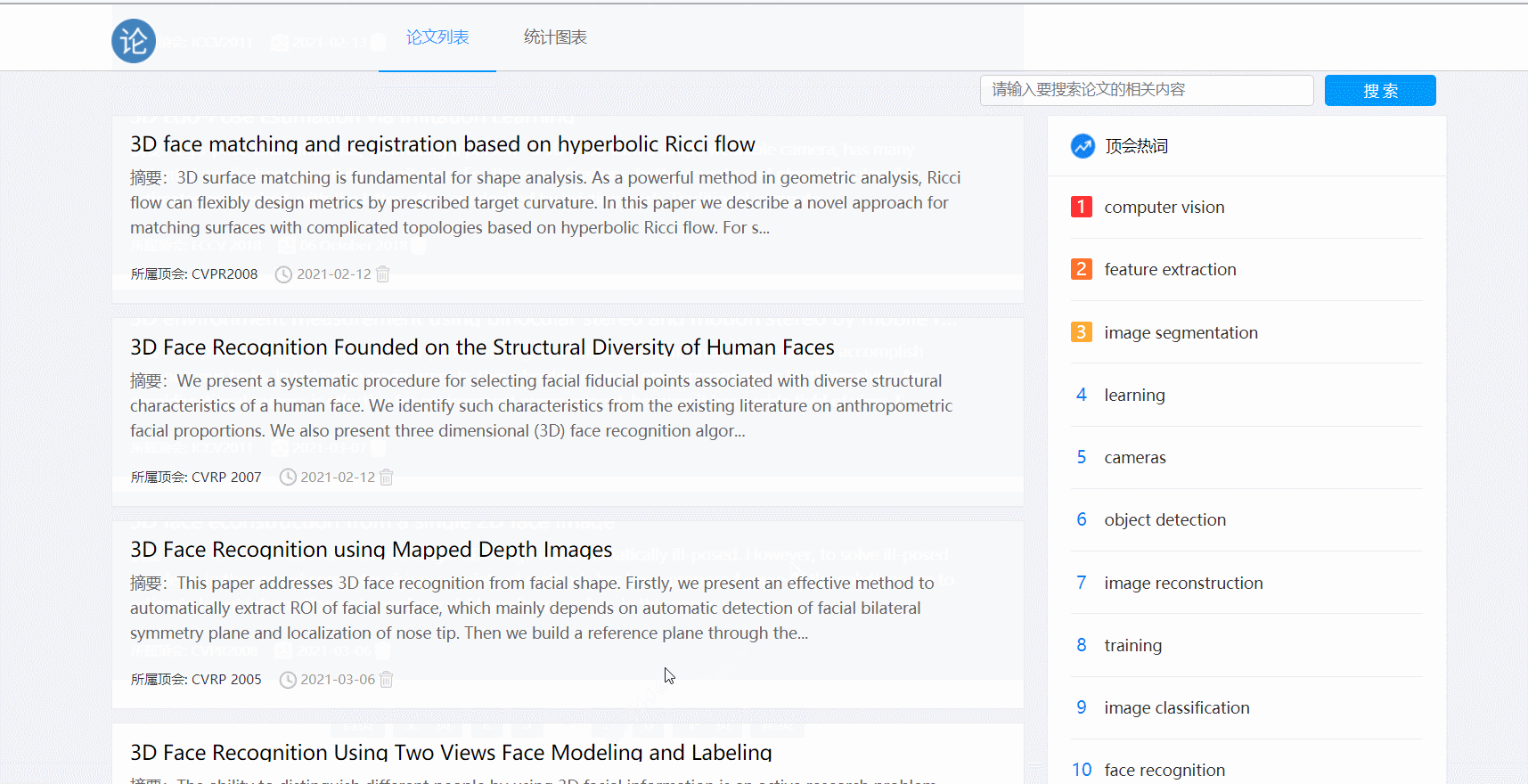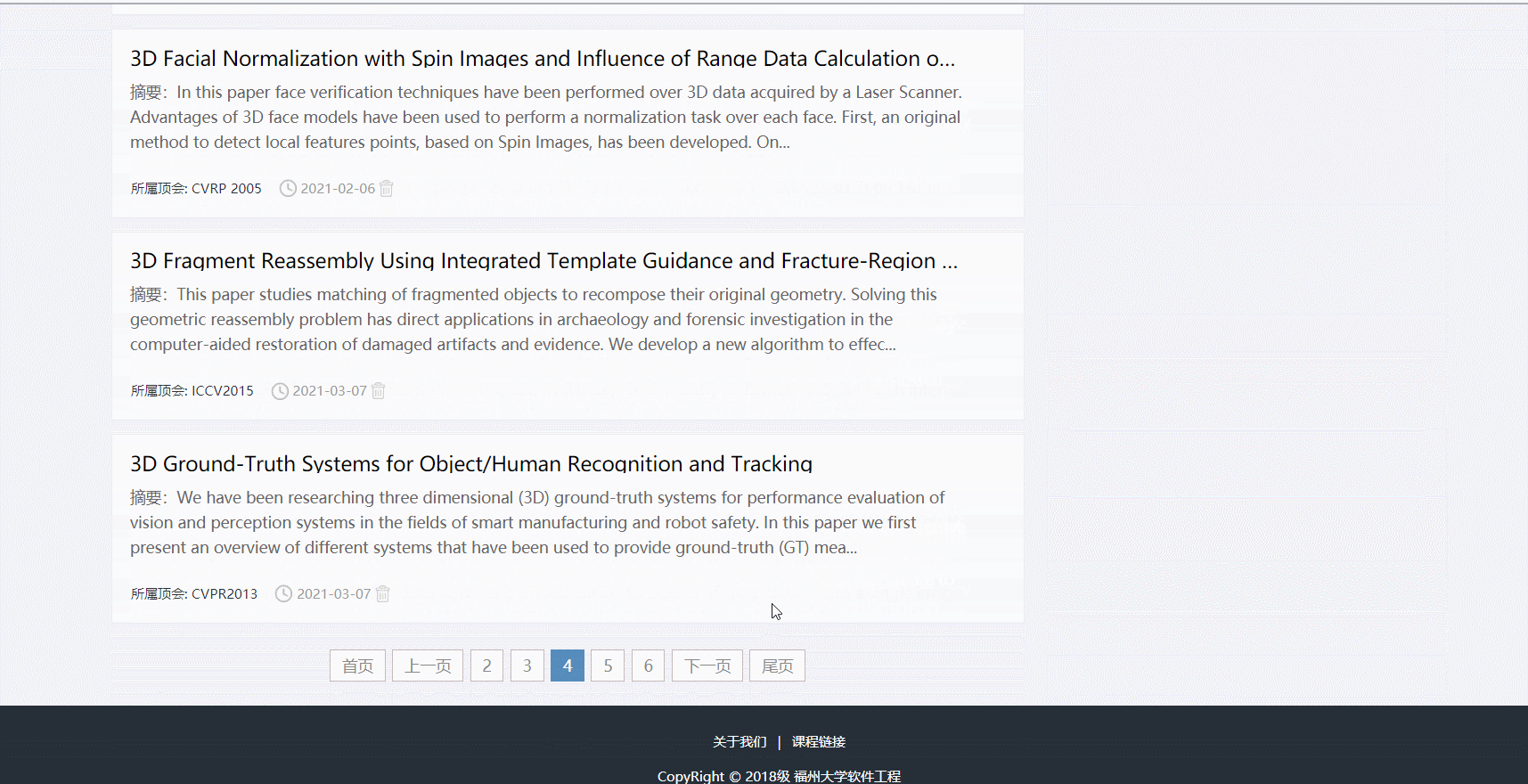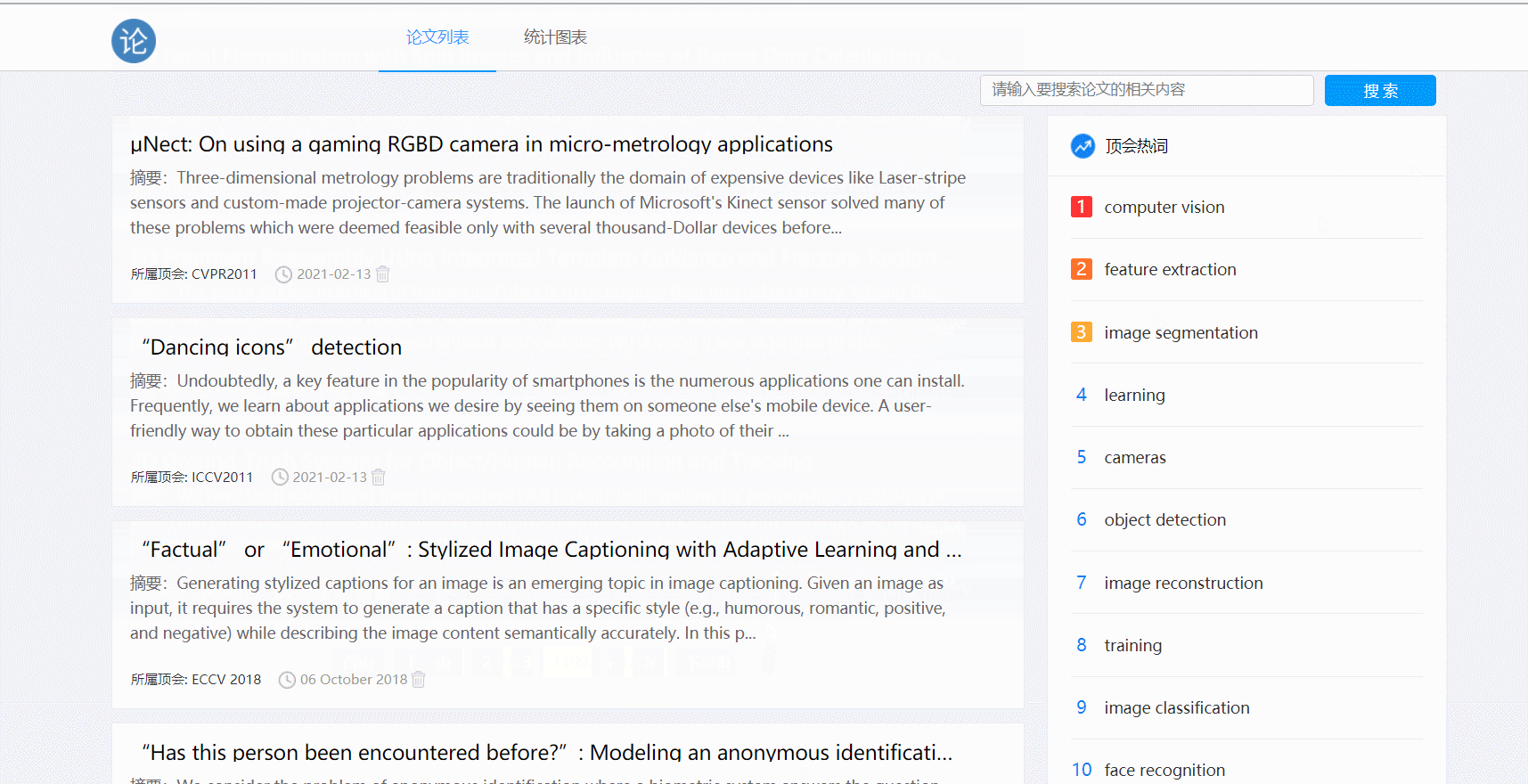
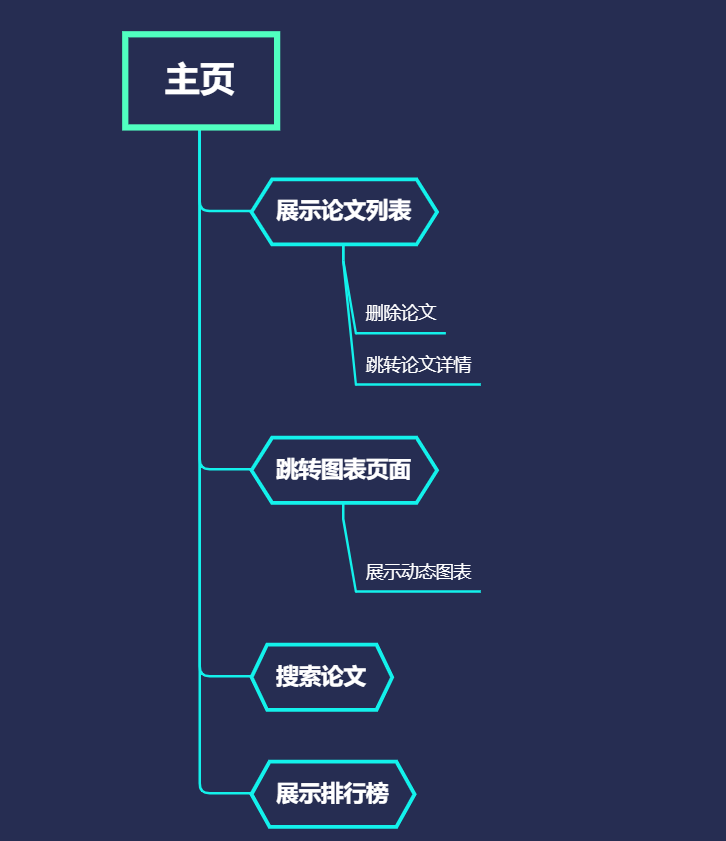
五、功能展示
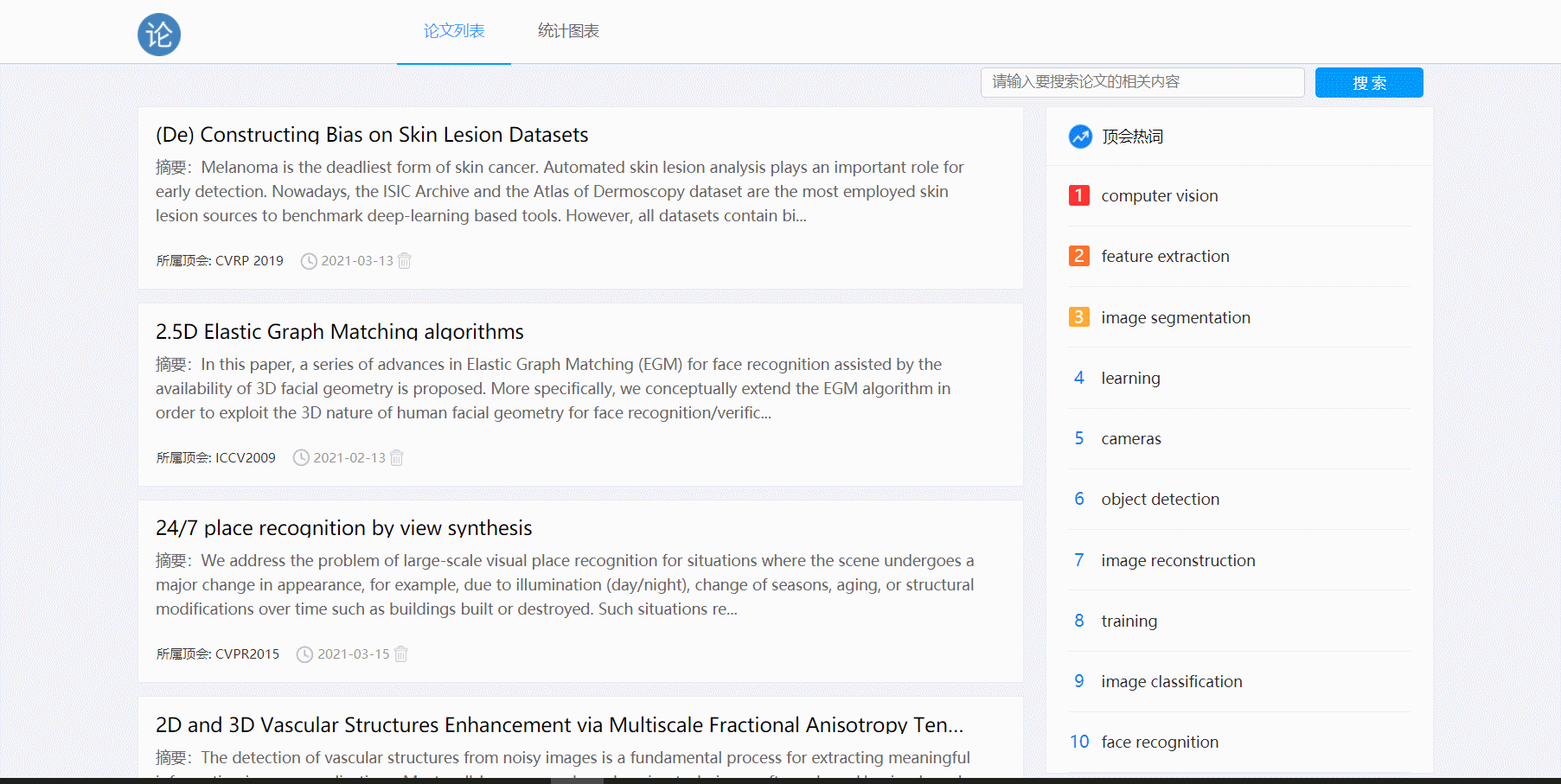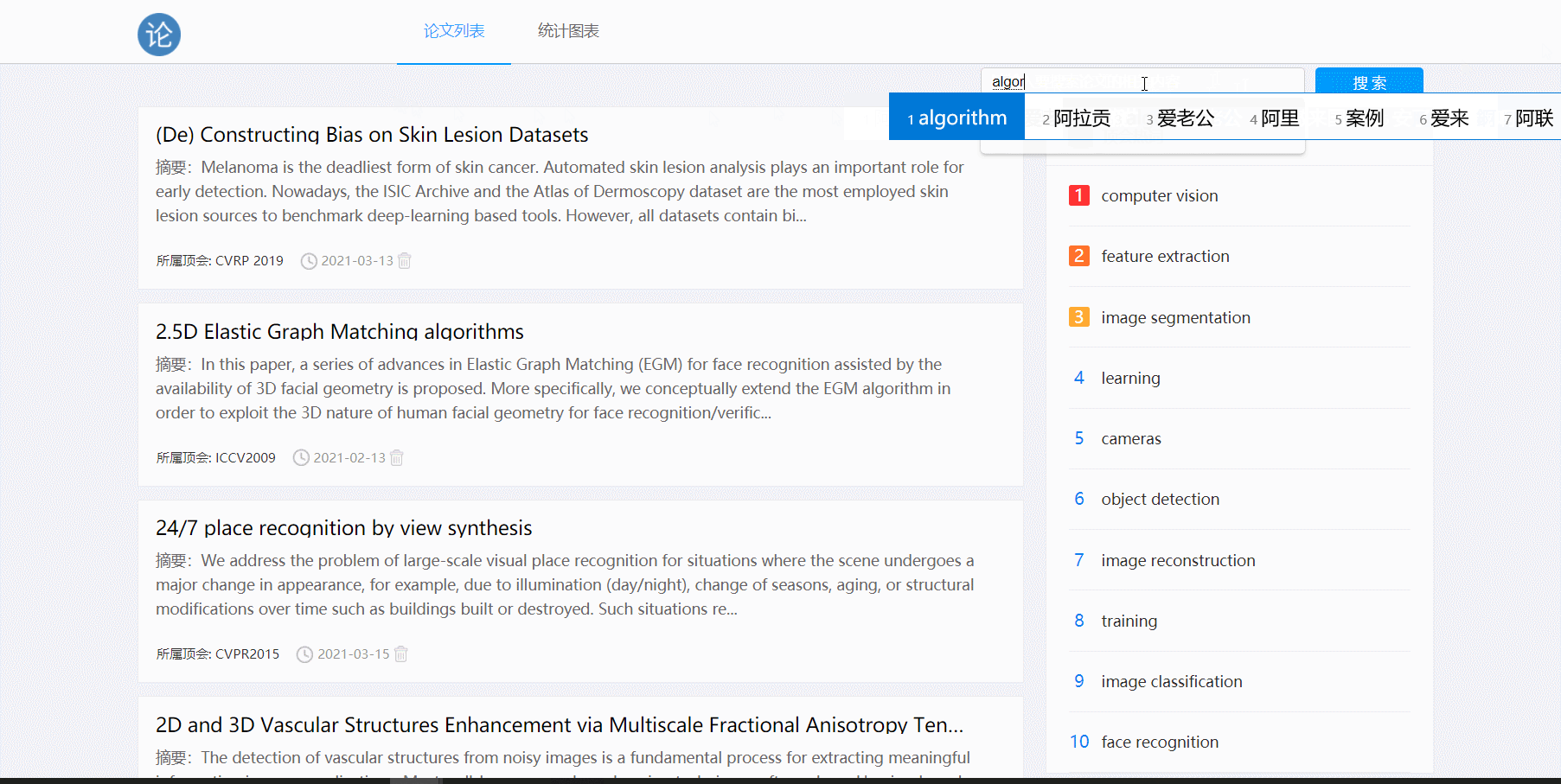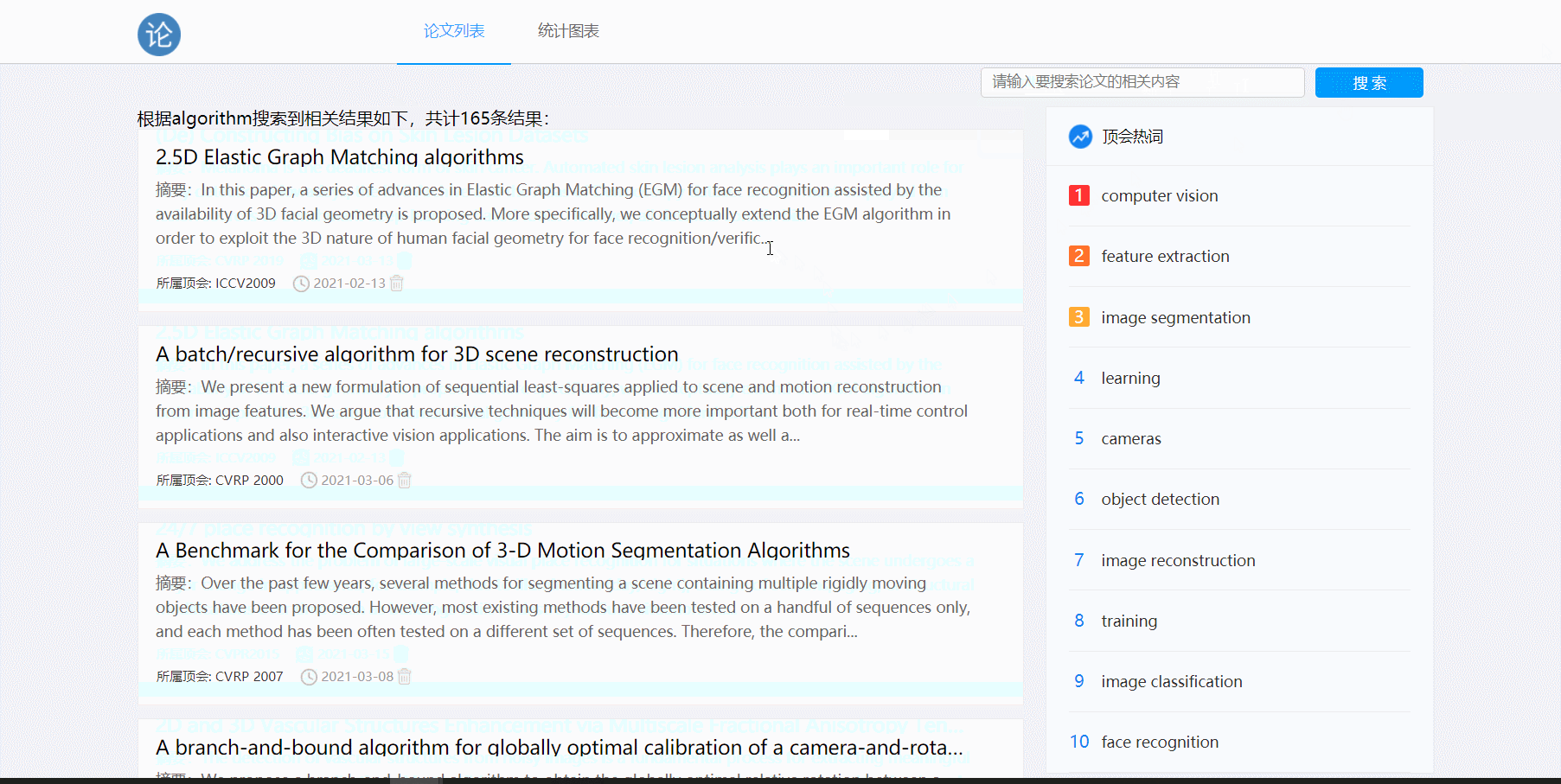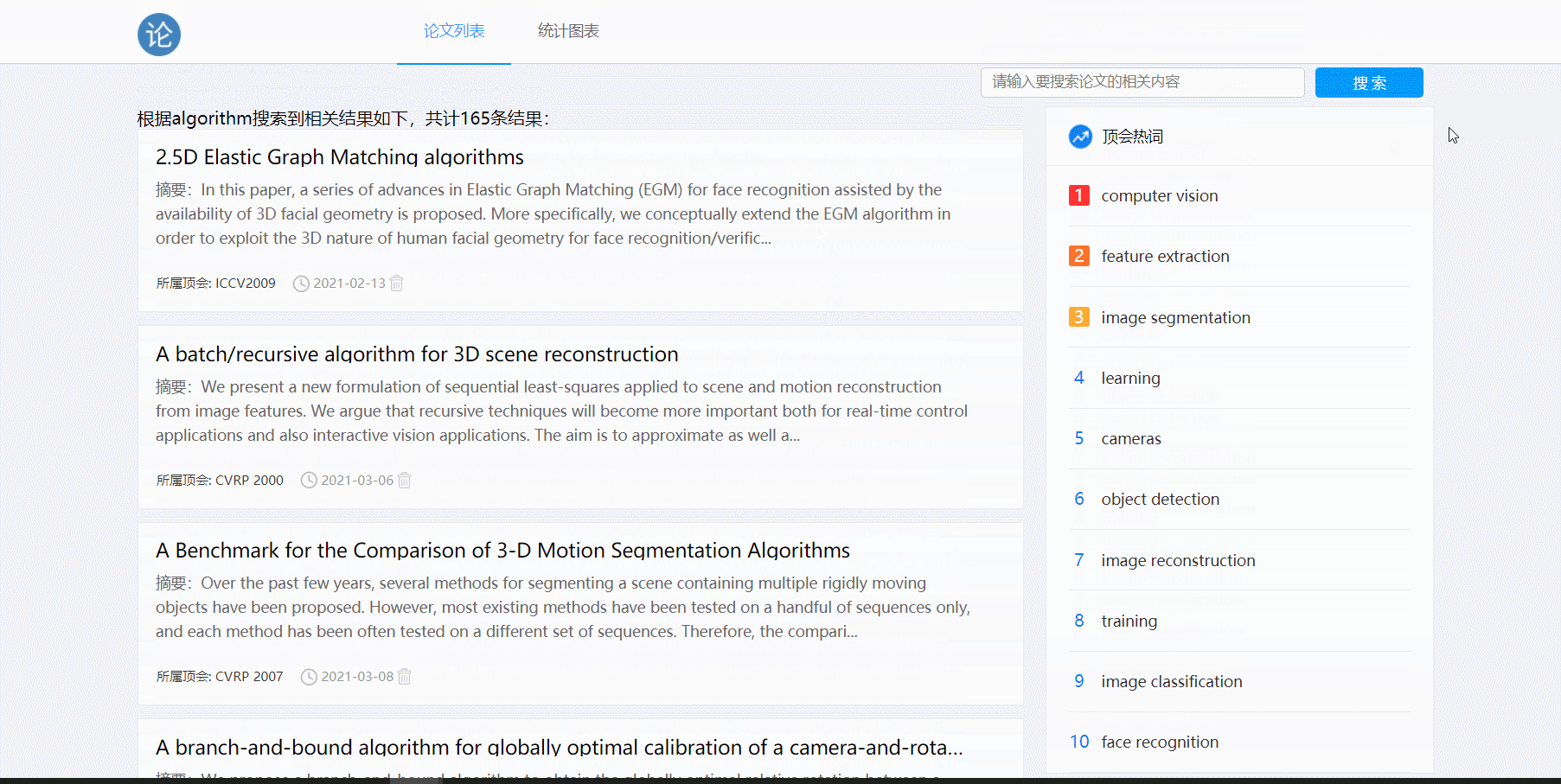
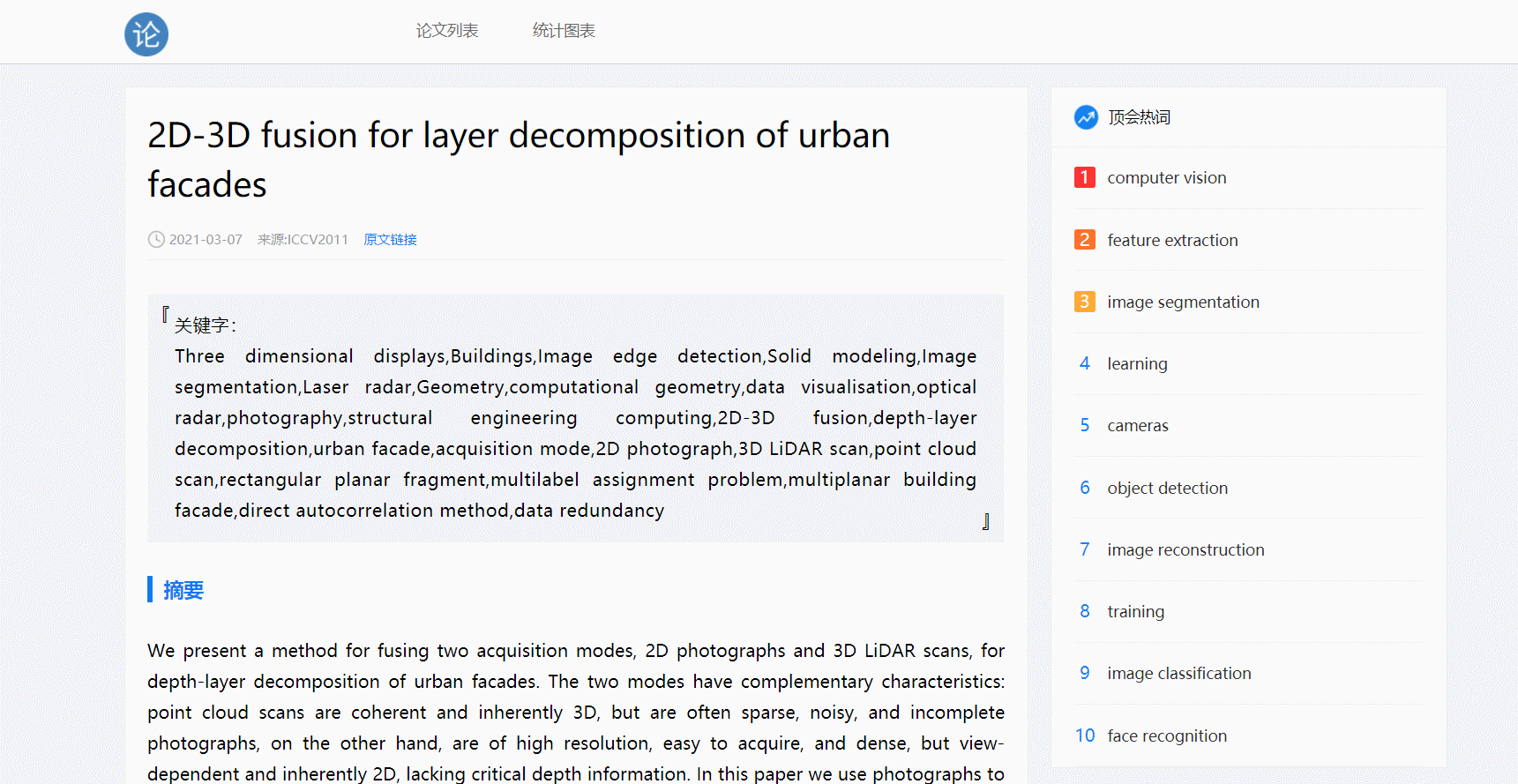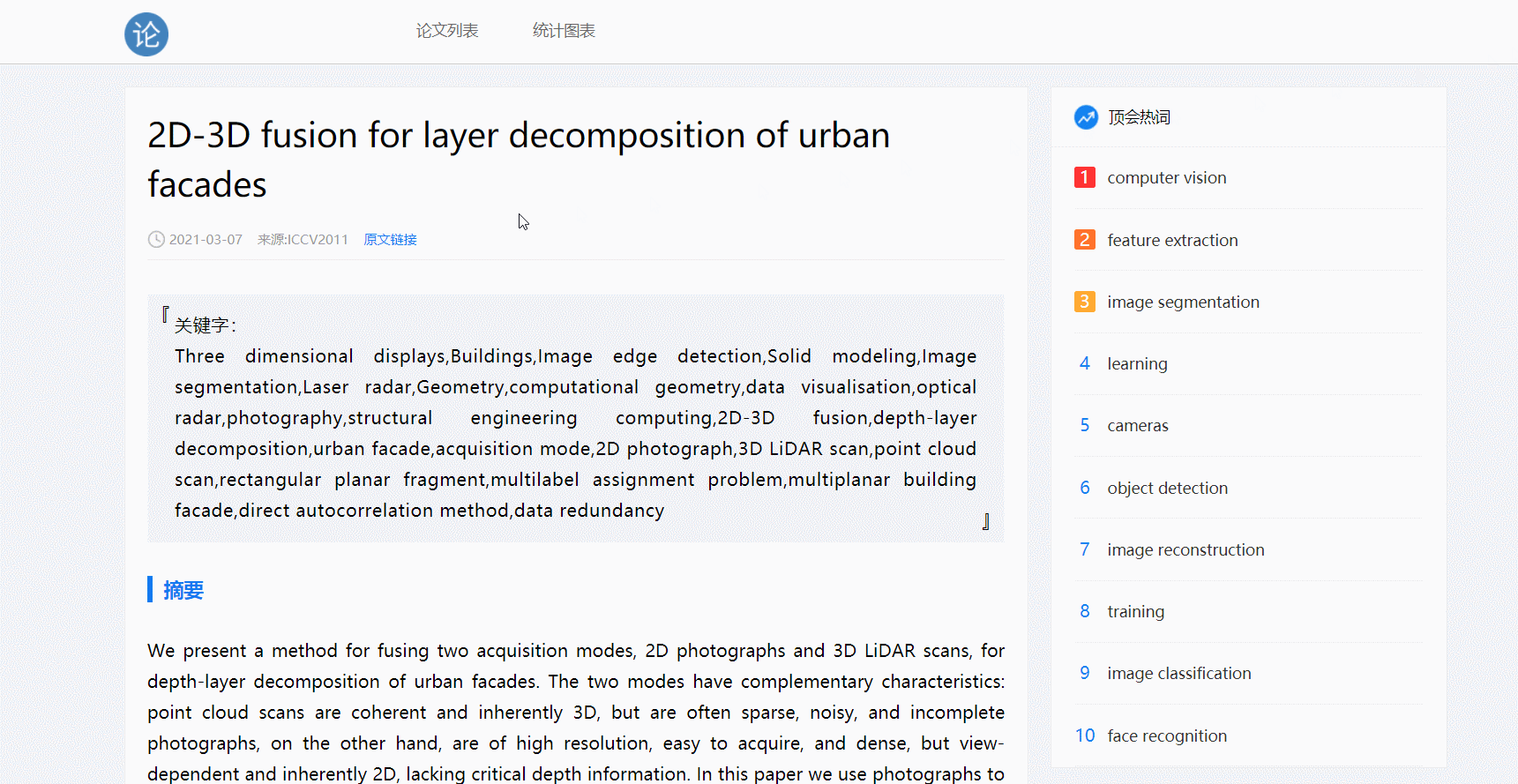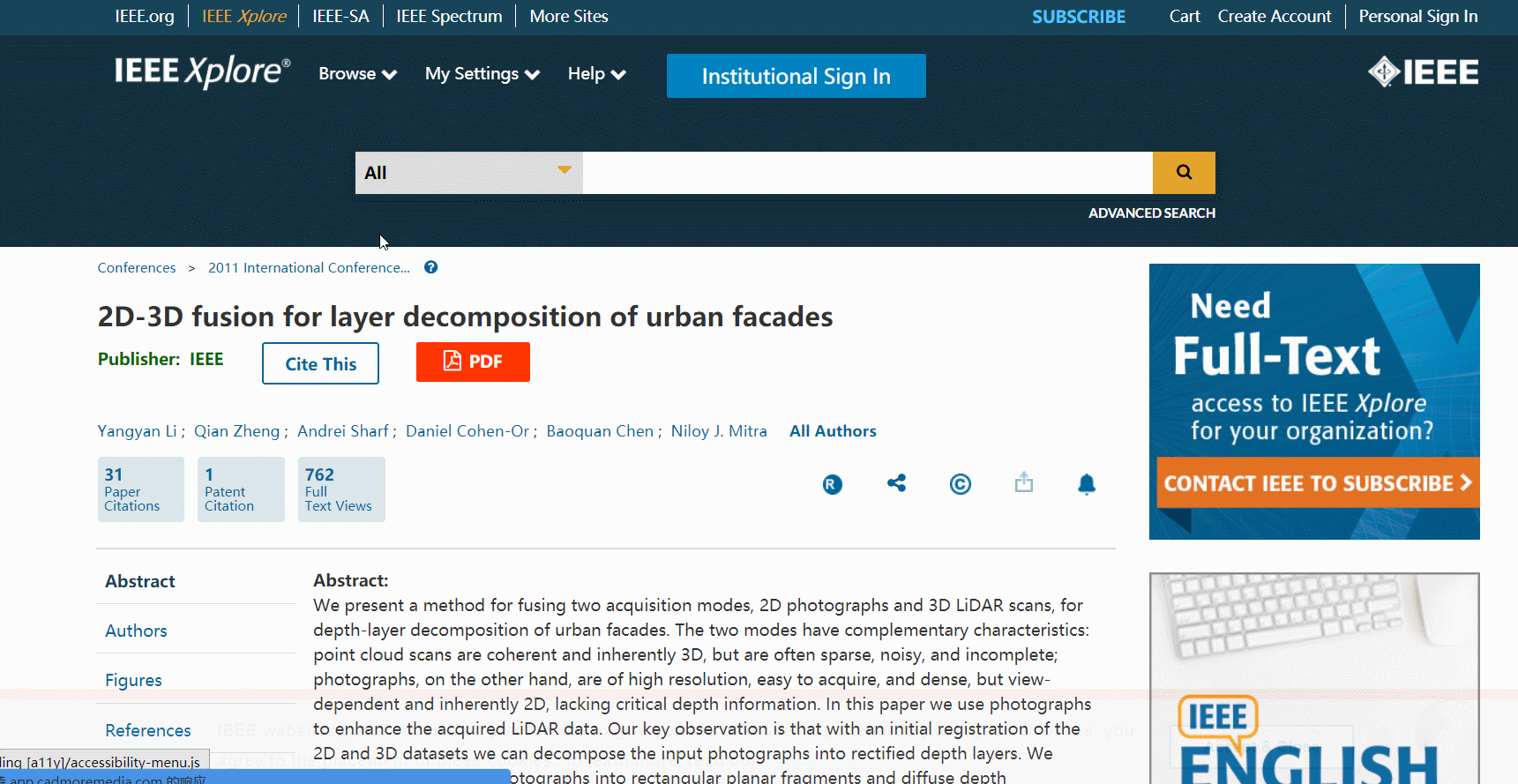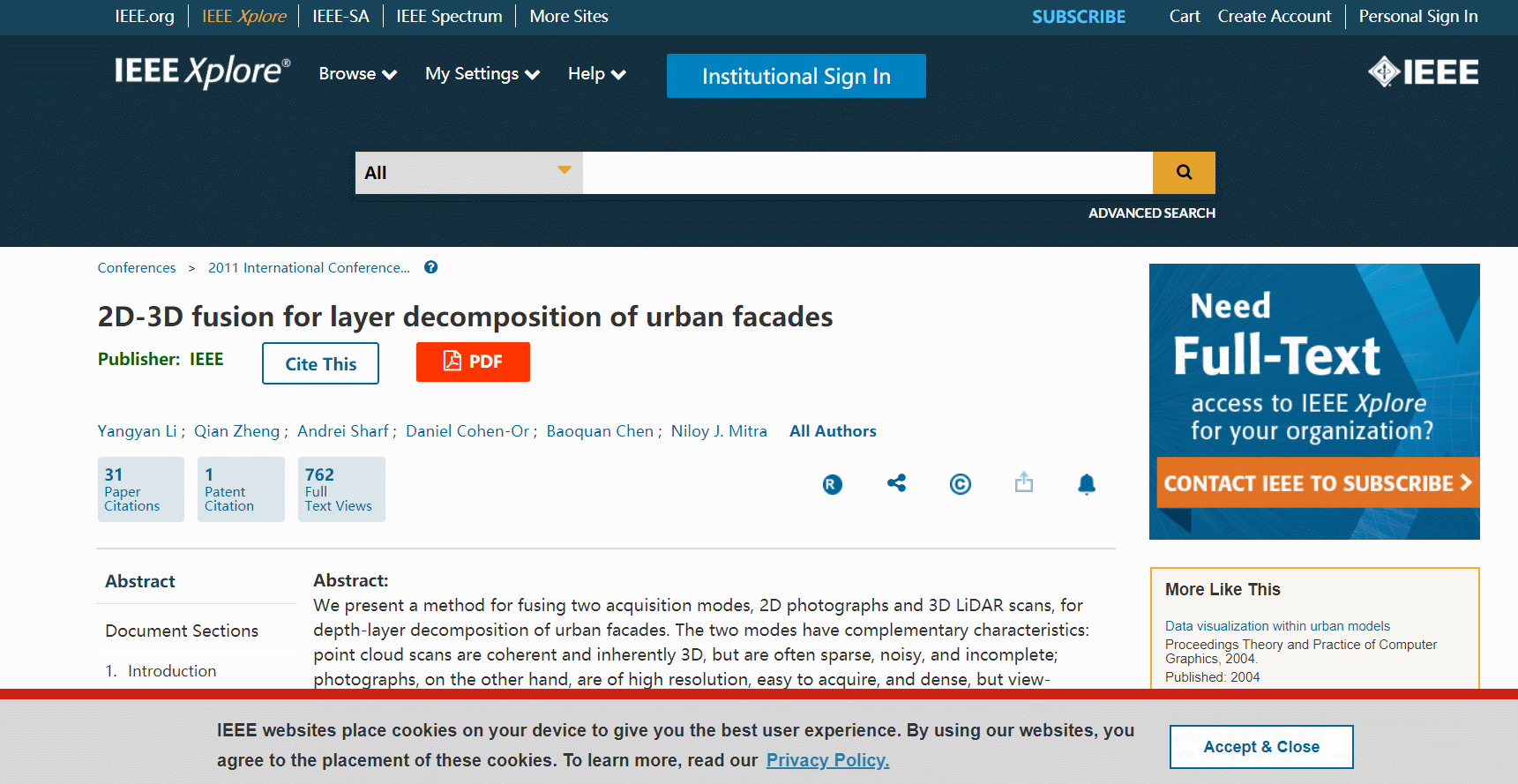
- 点击论文跳转详情页
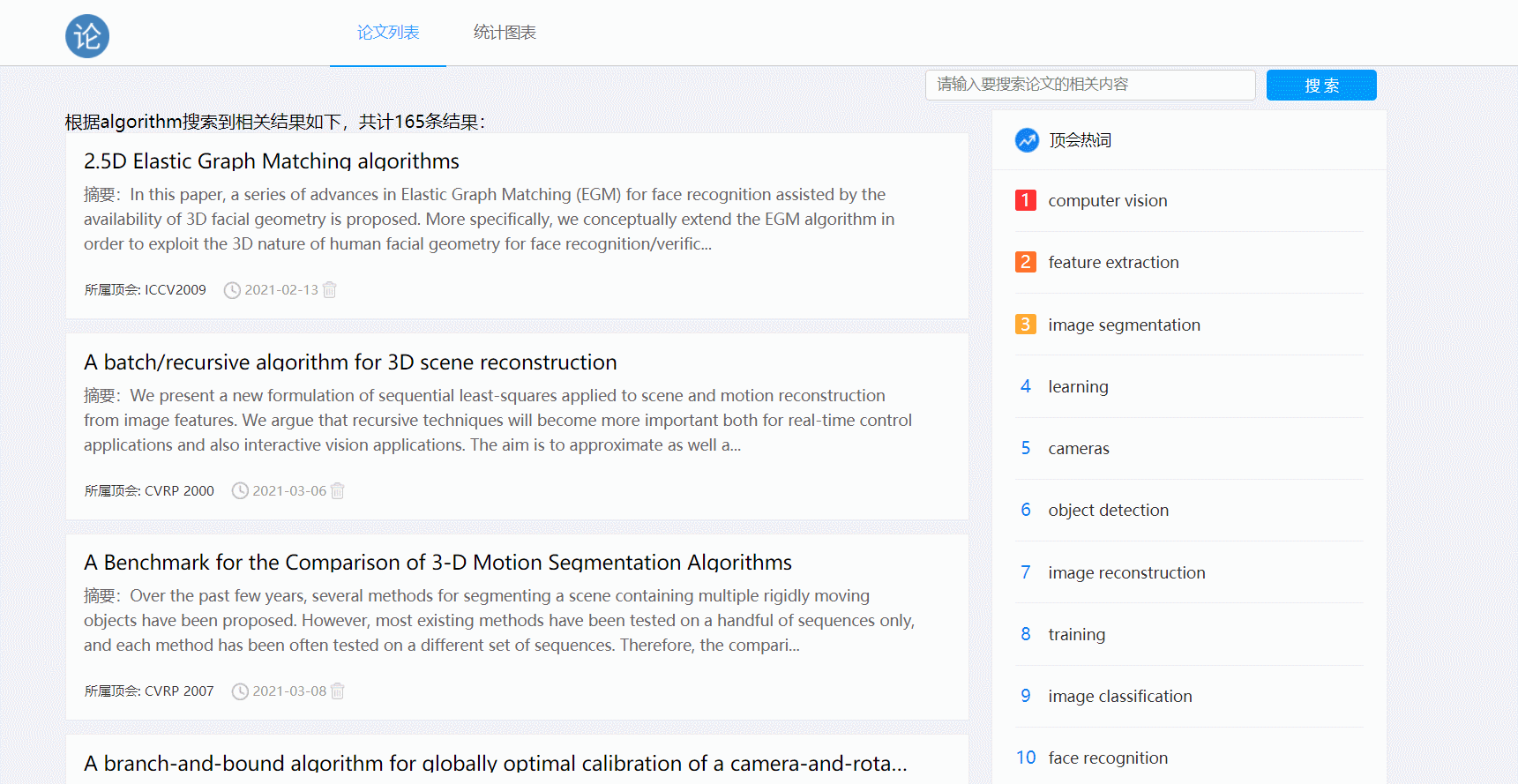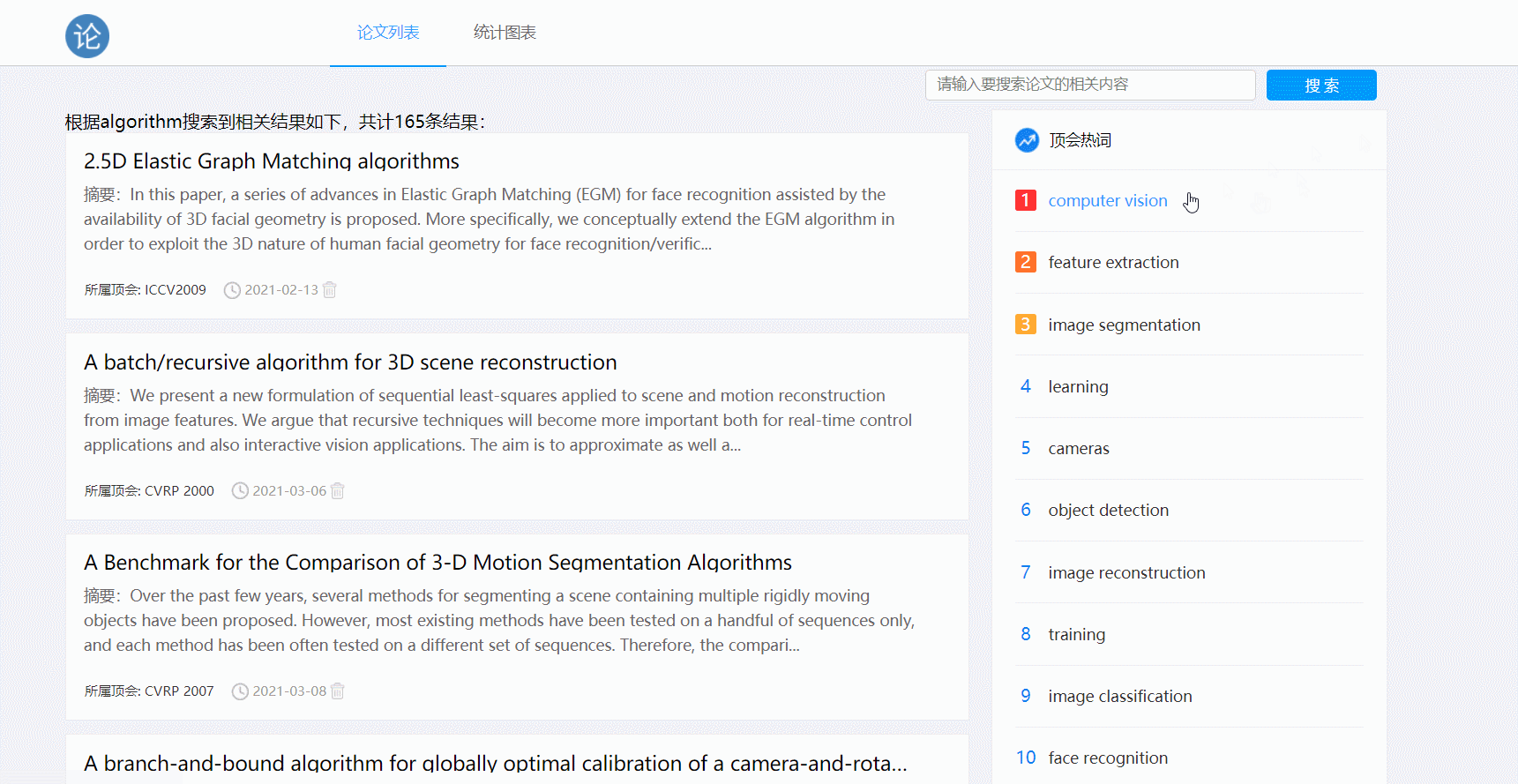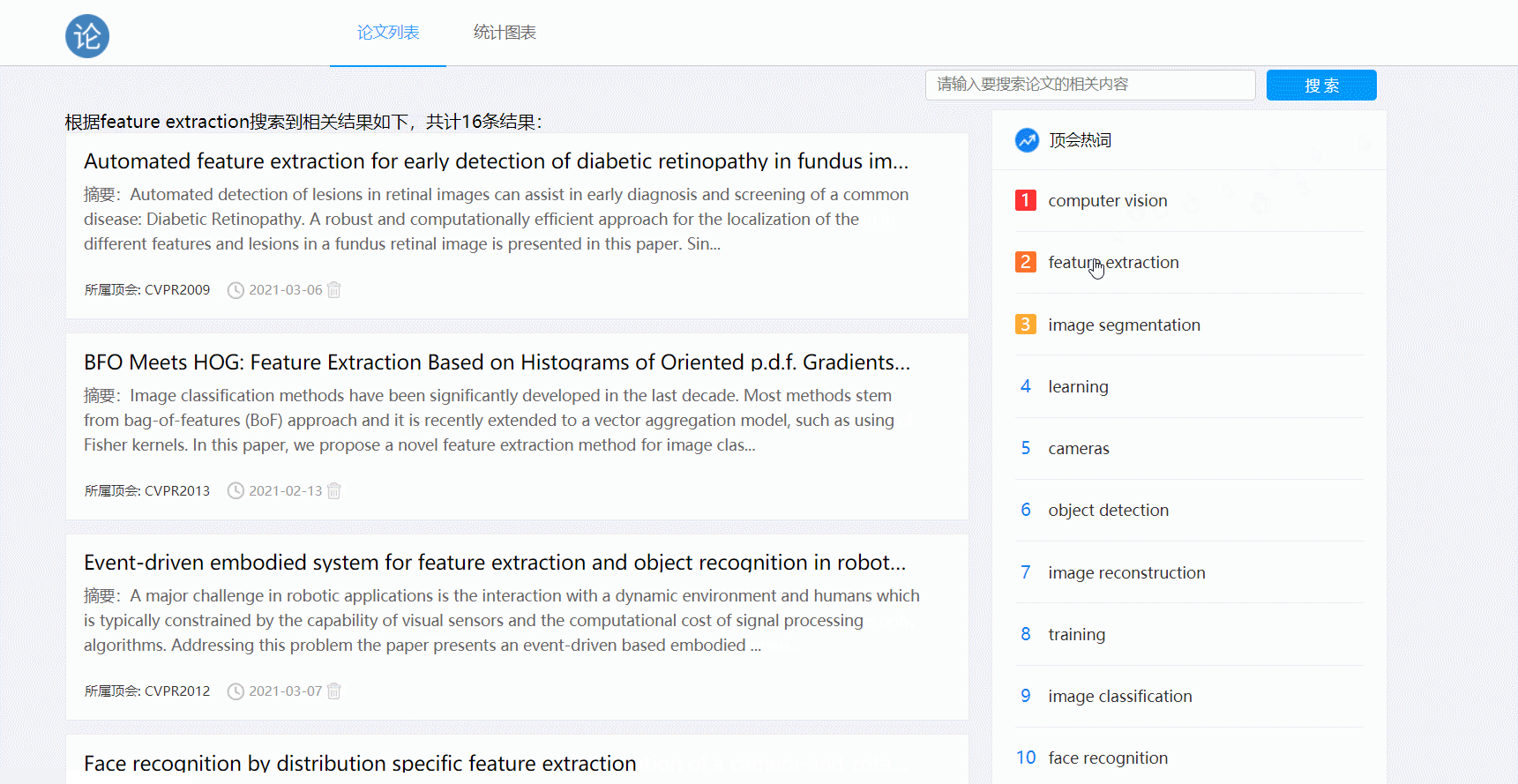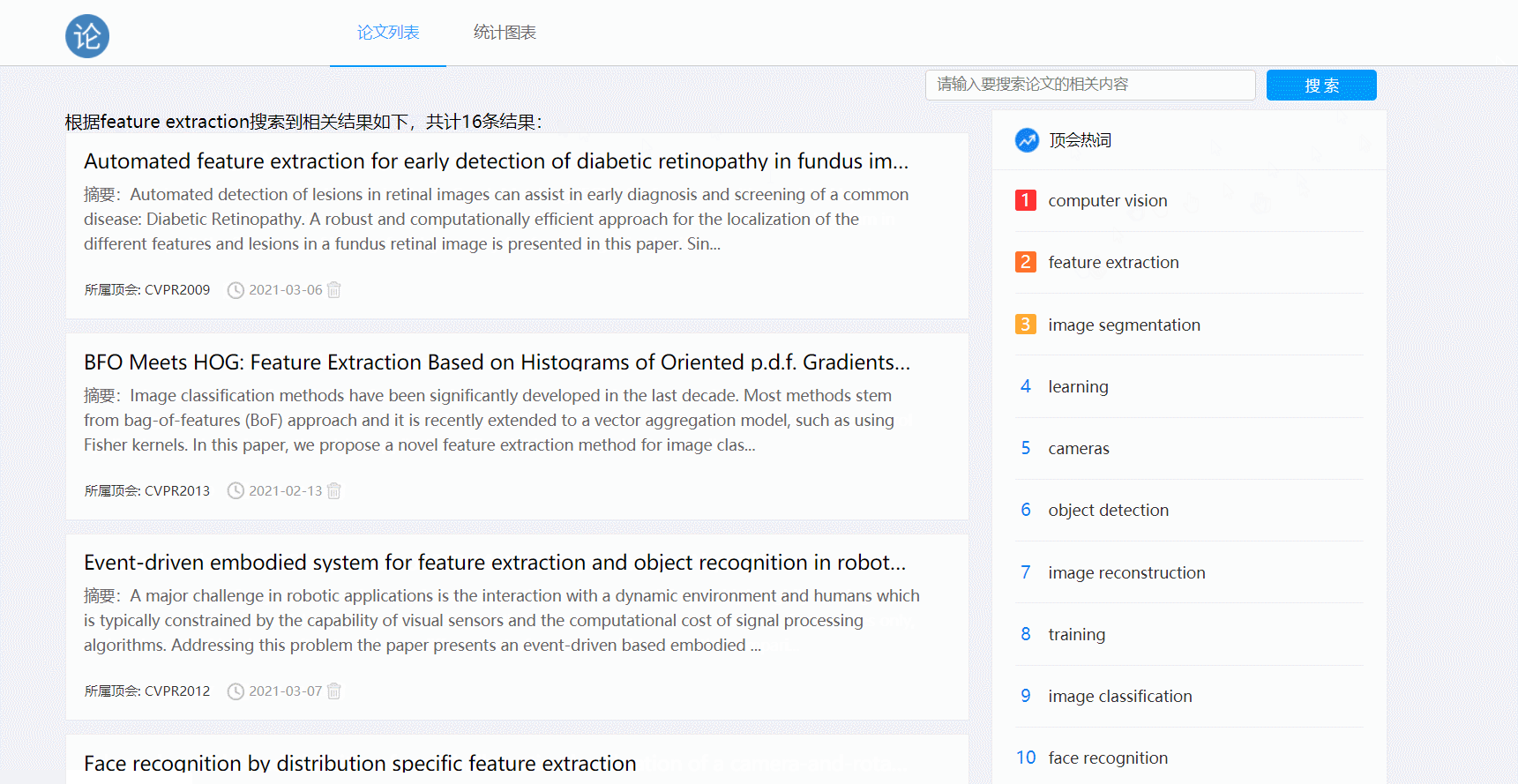
- 论文搜索功能
- 点击排行榜可对热词进行搜索
- 分页功能
- 点击导航栏‘统计图表’可跳转图表页面
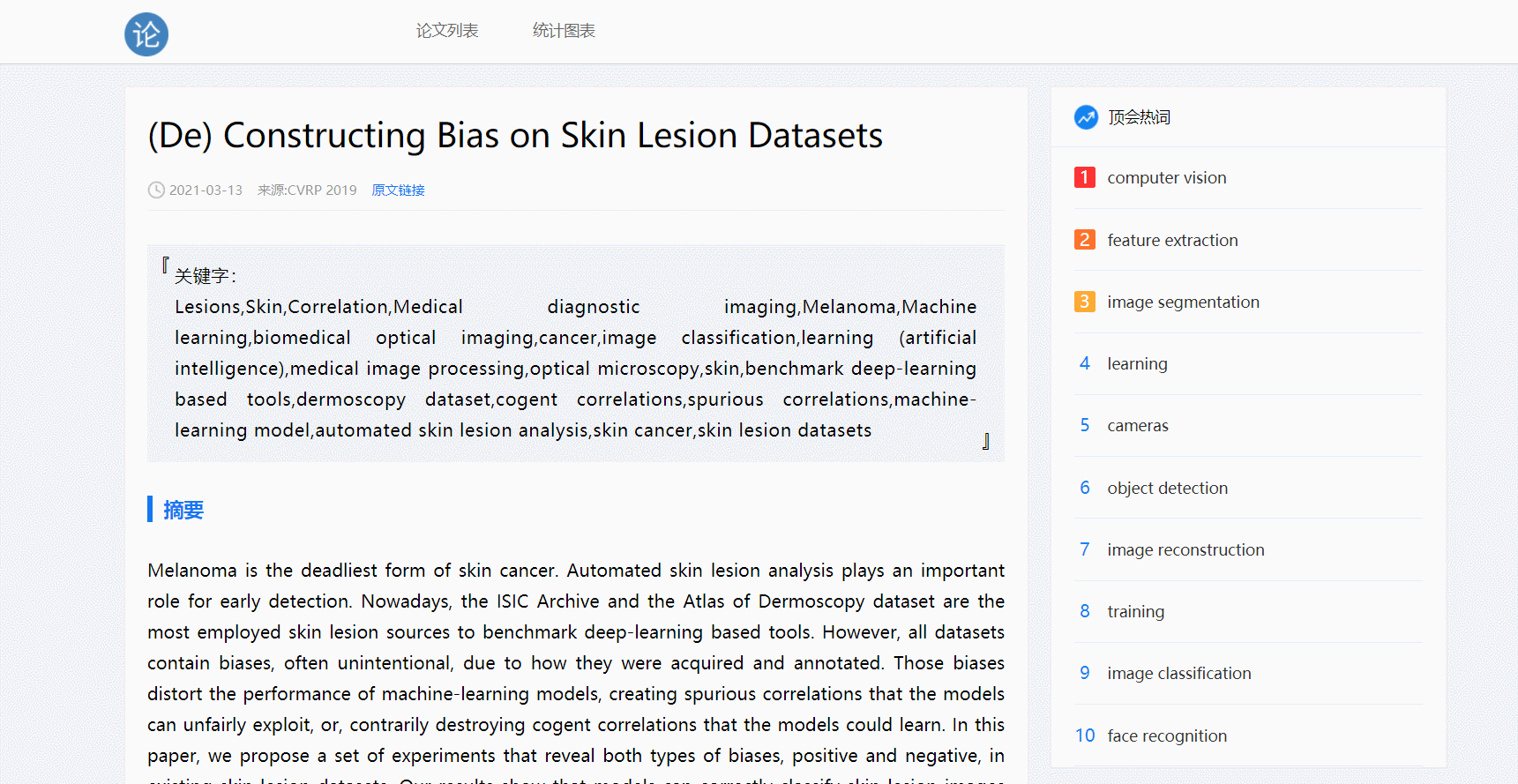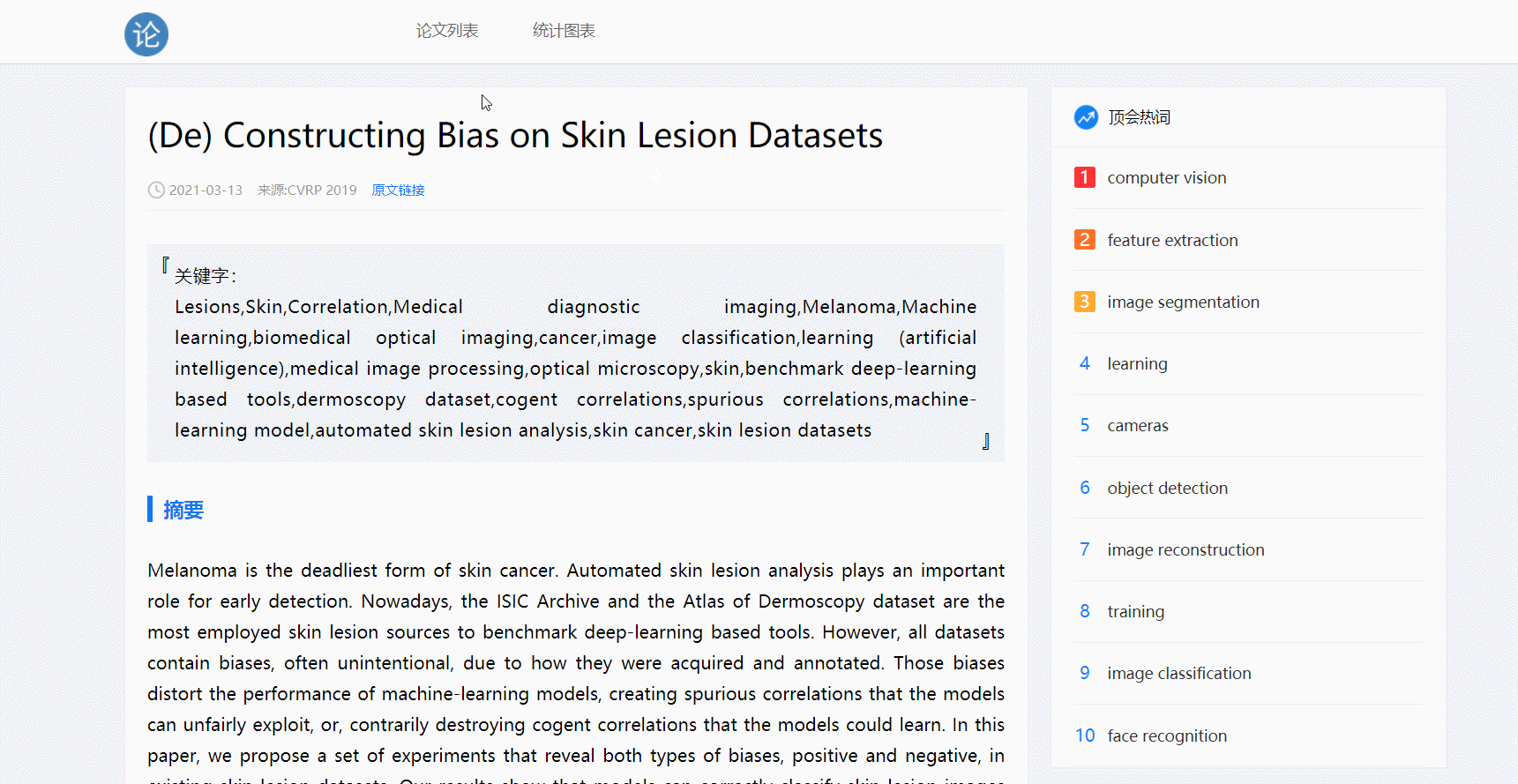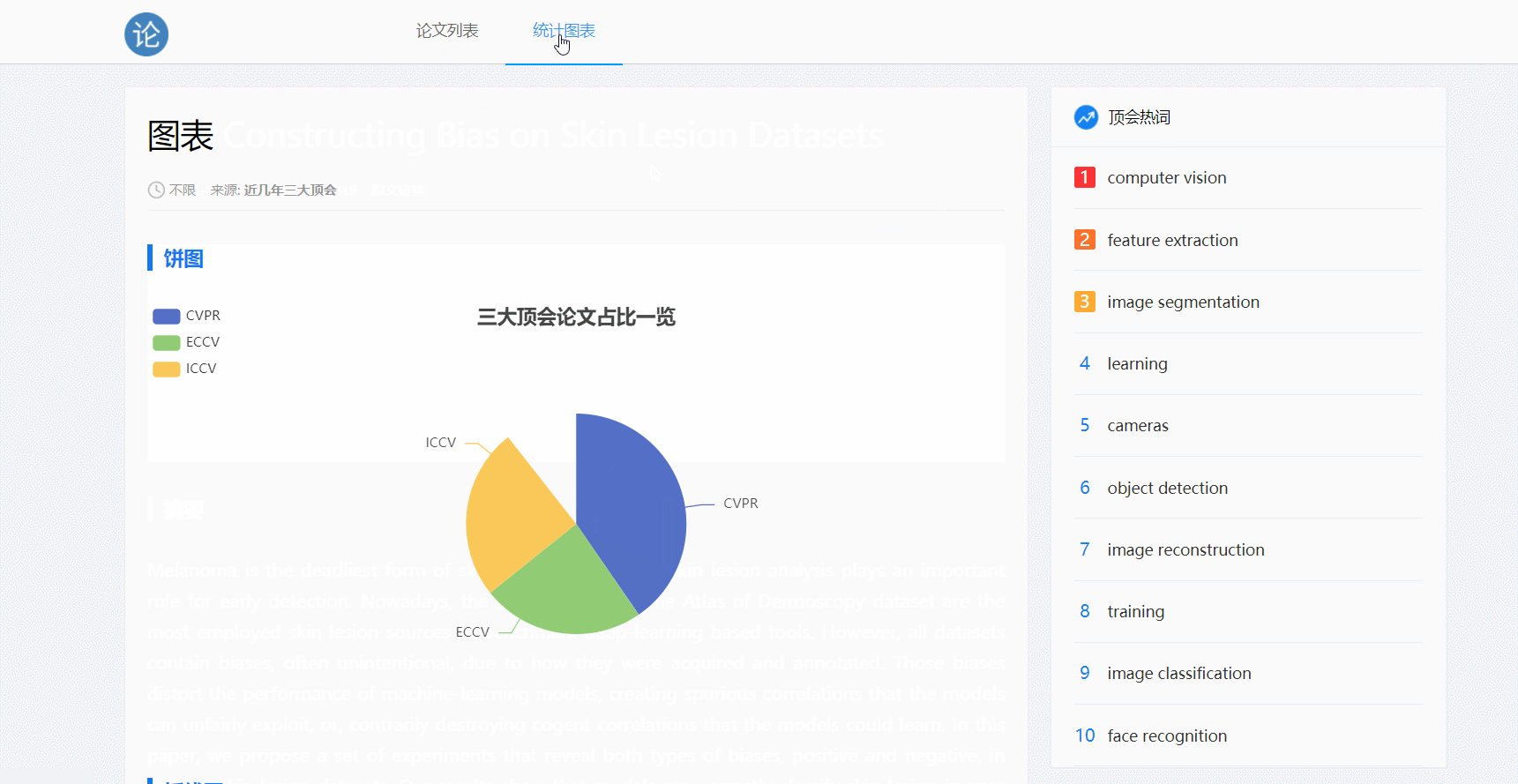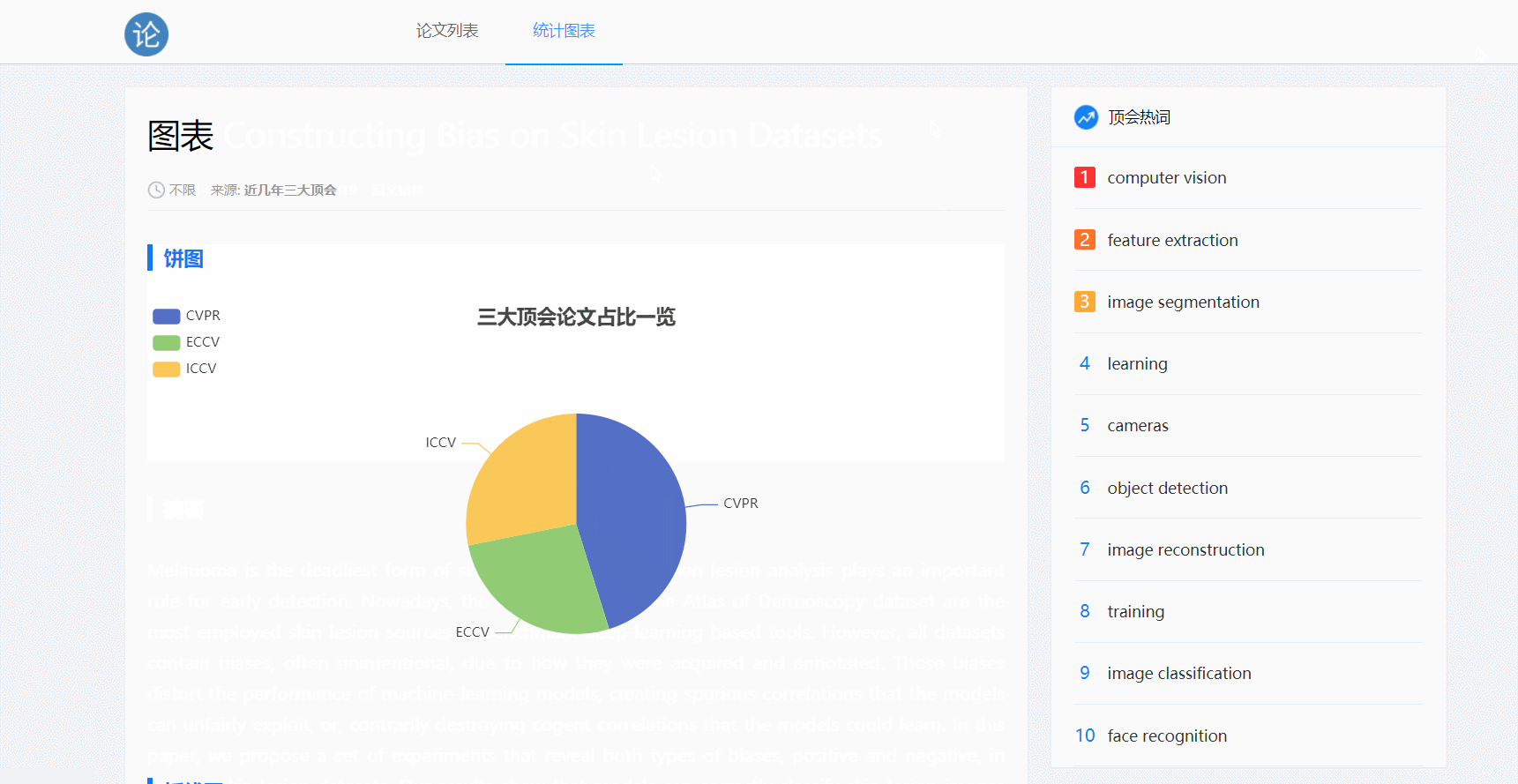
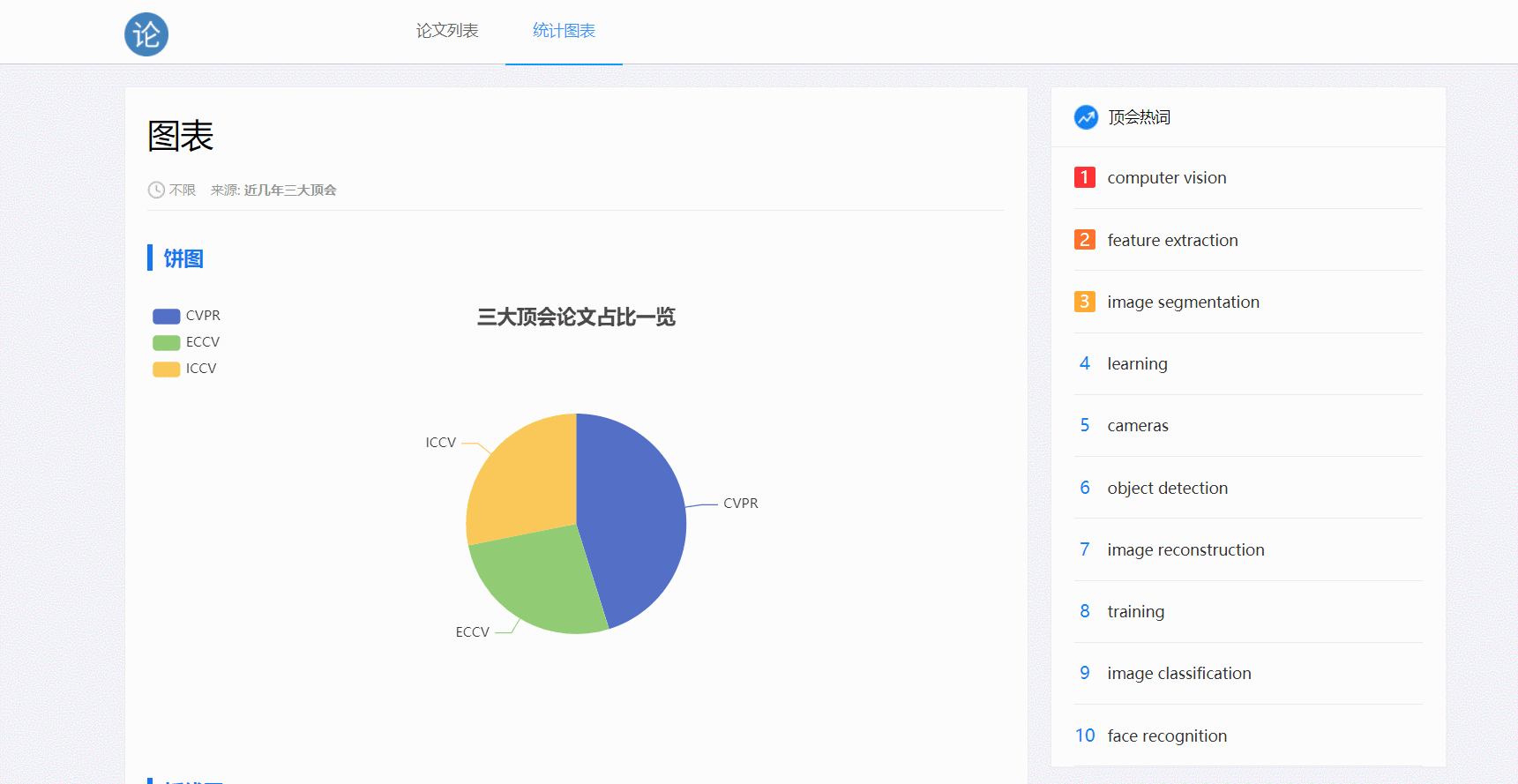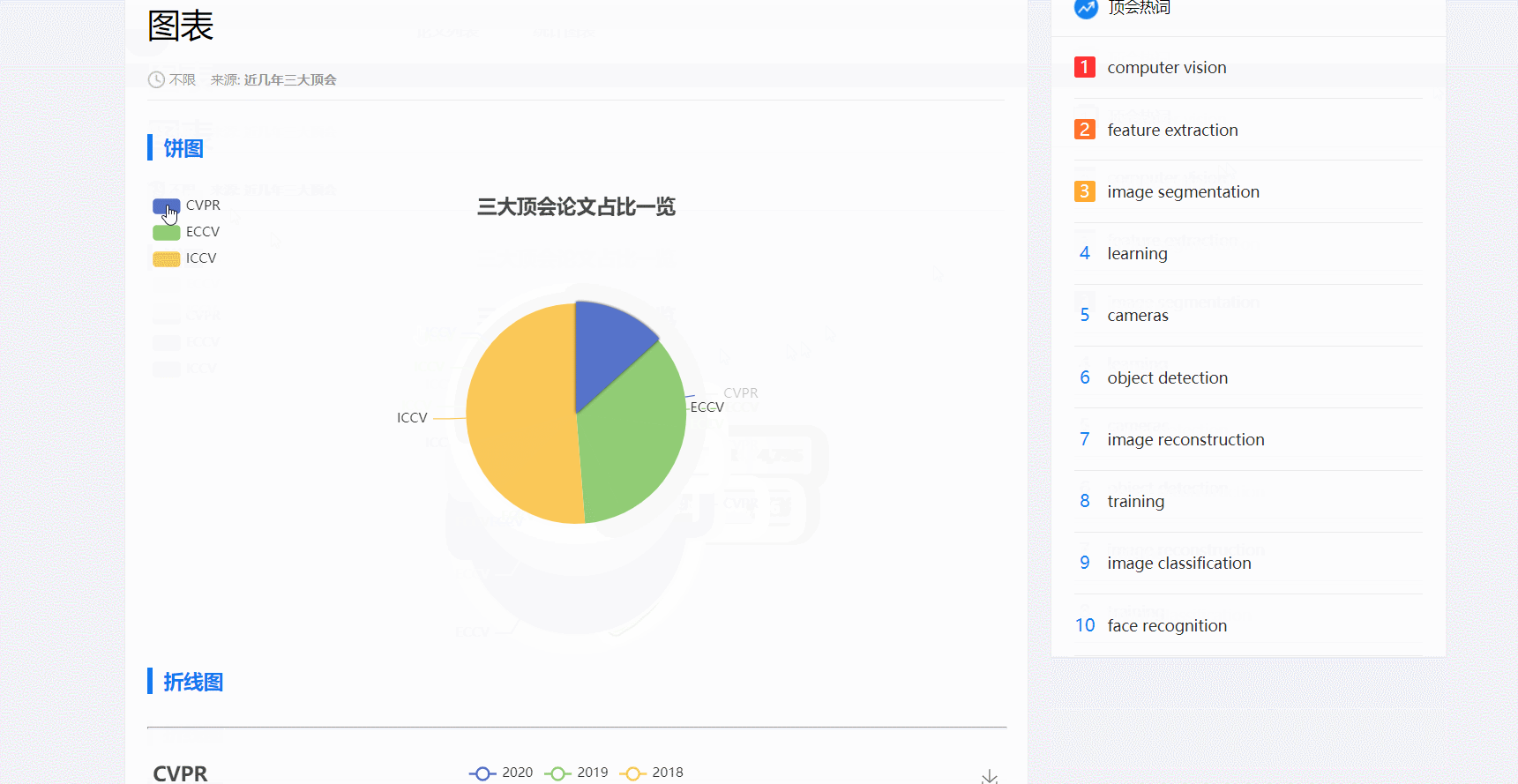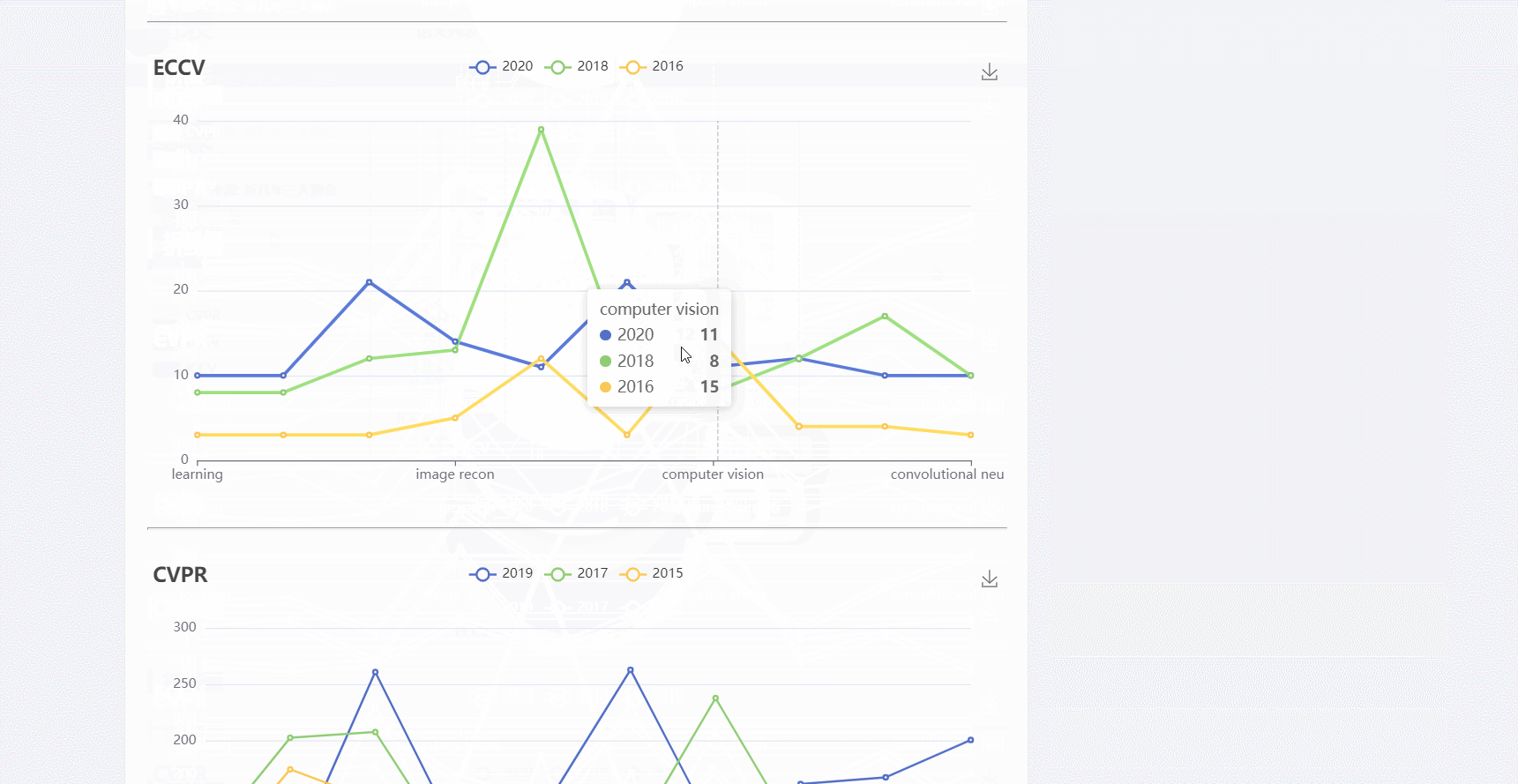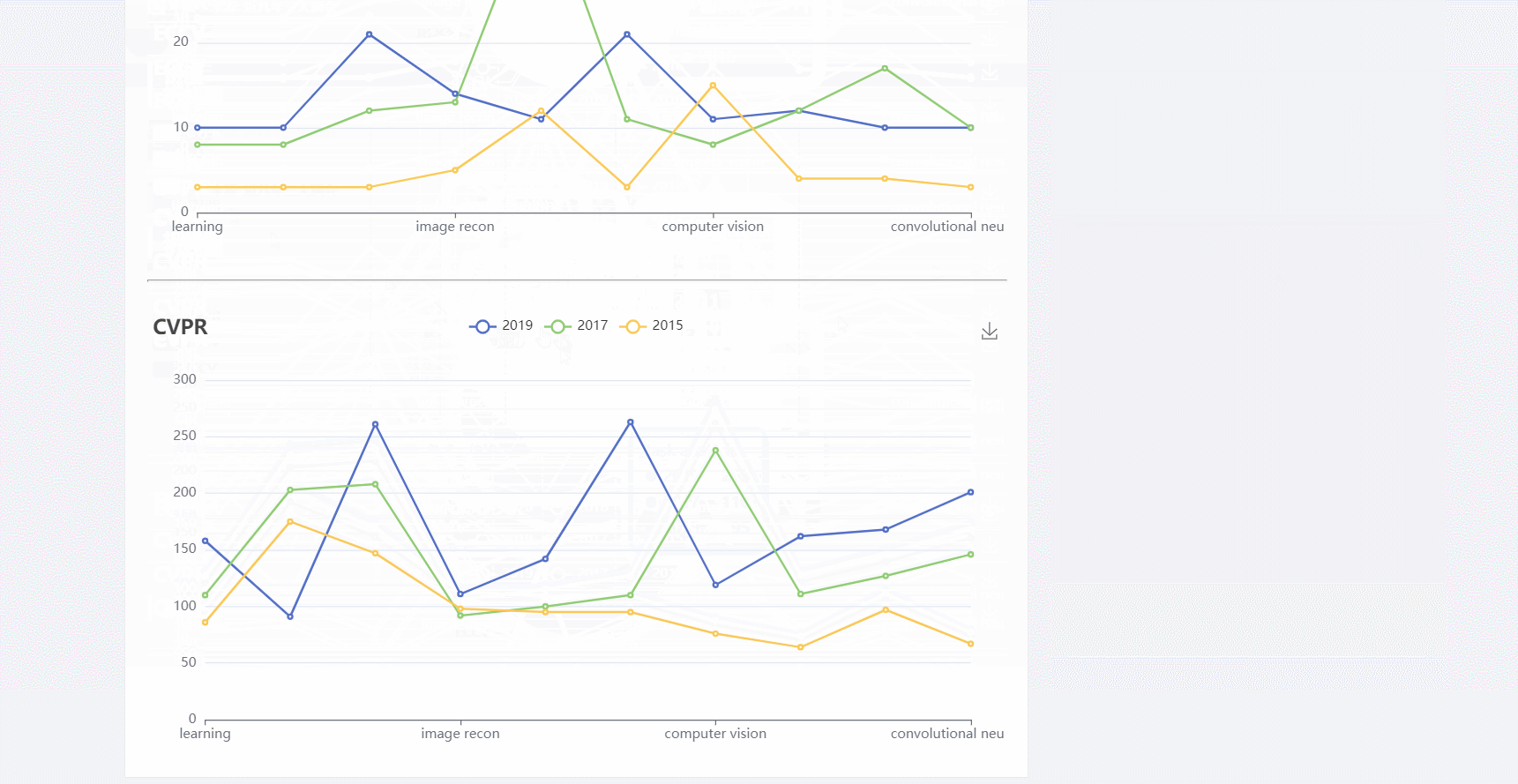
- 图表是动态的,包含饼图和折线图
- 论文删除功能,点击删除按钮
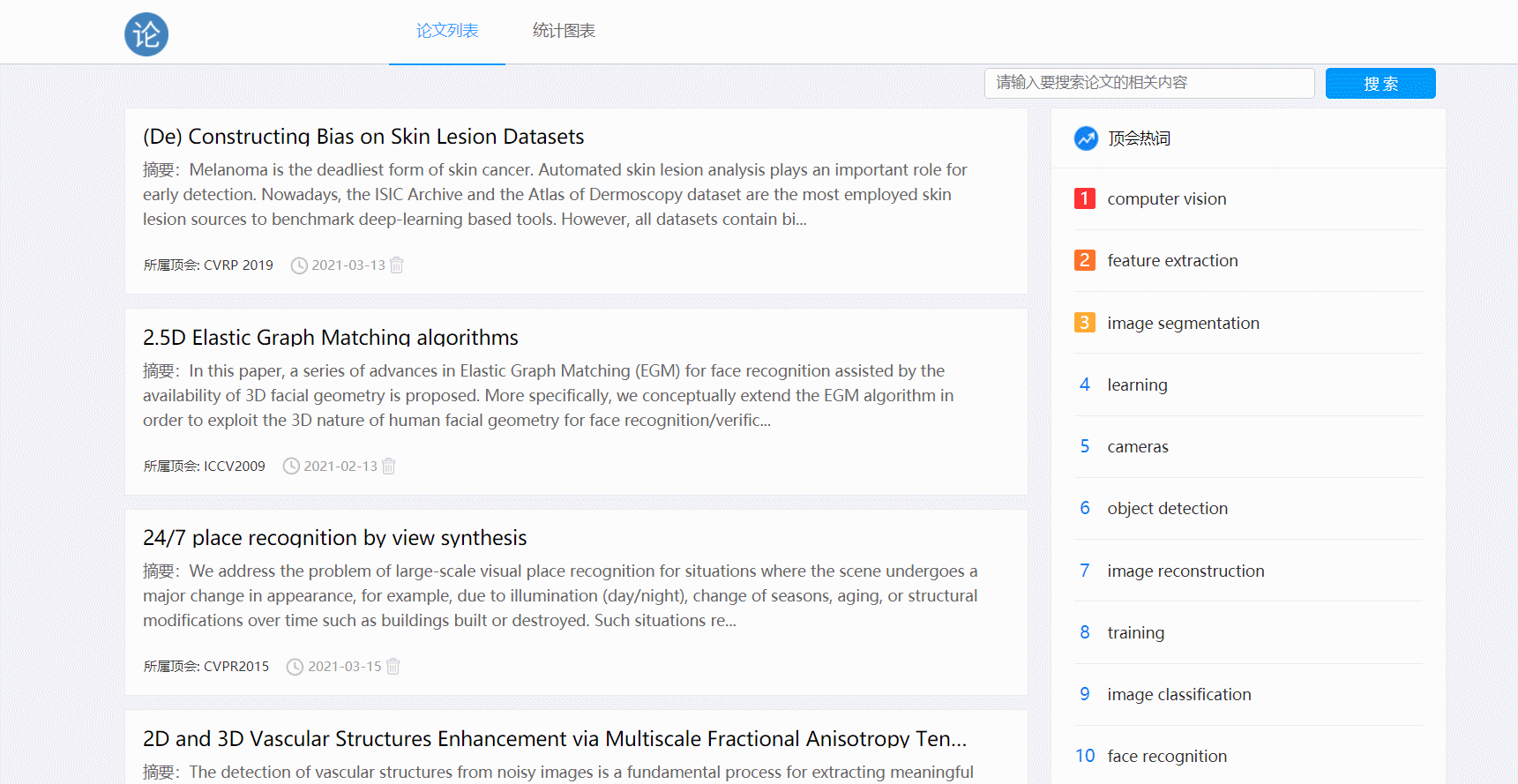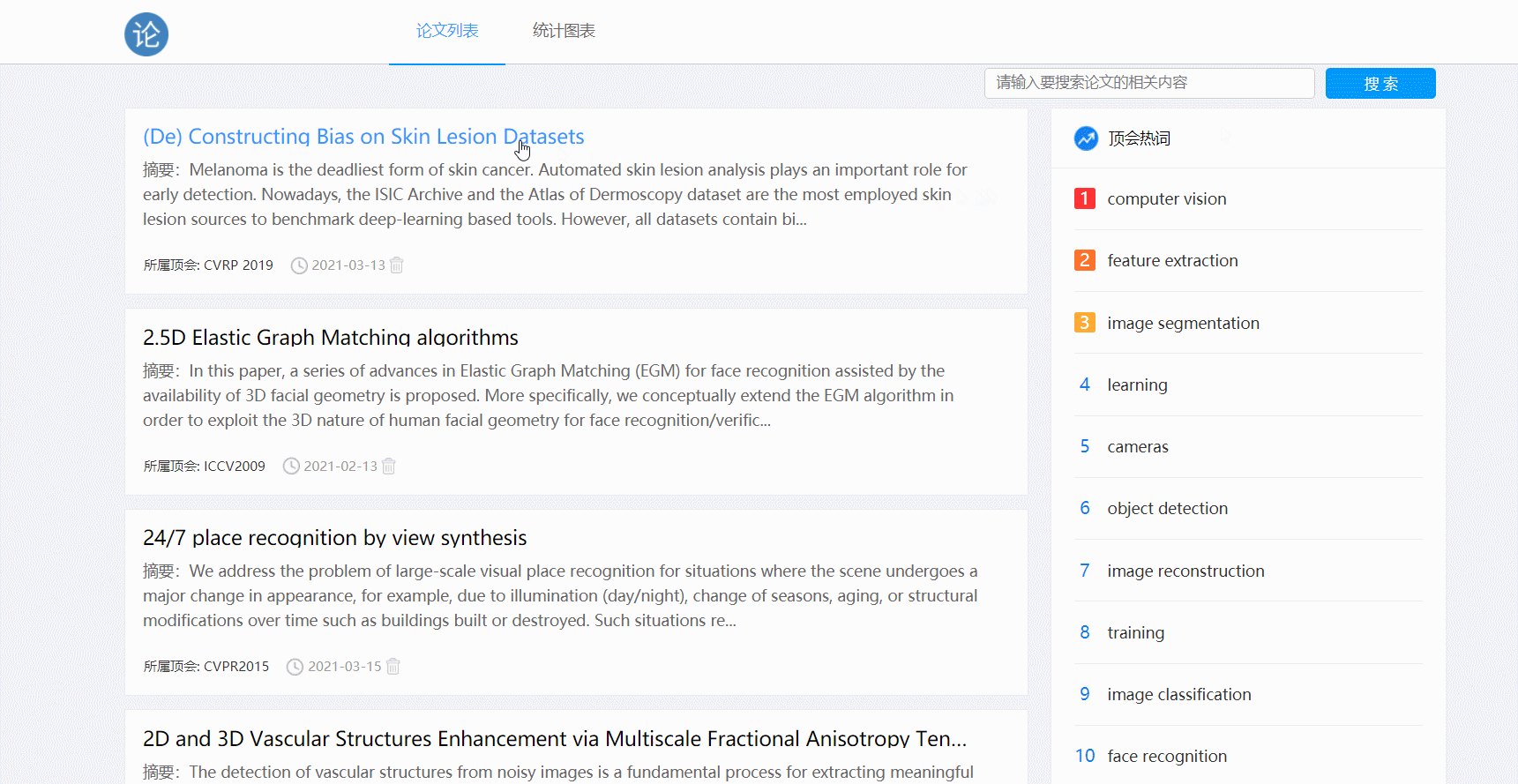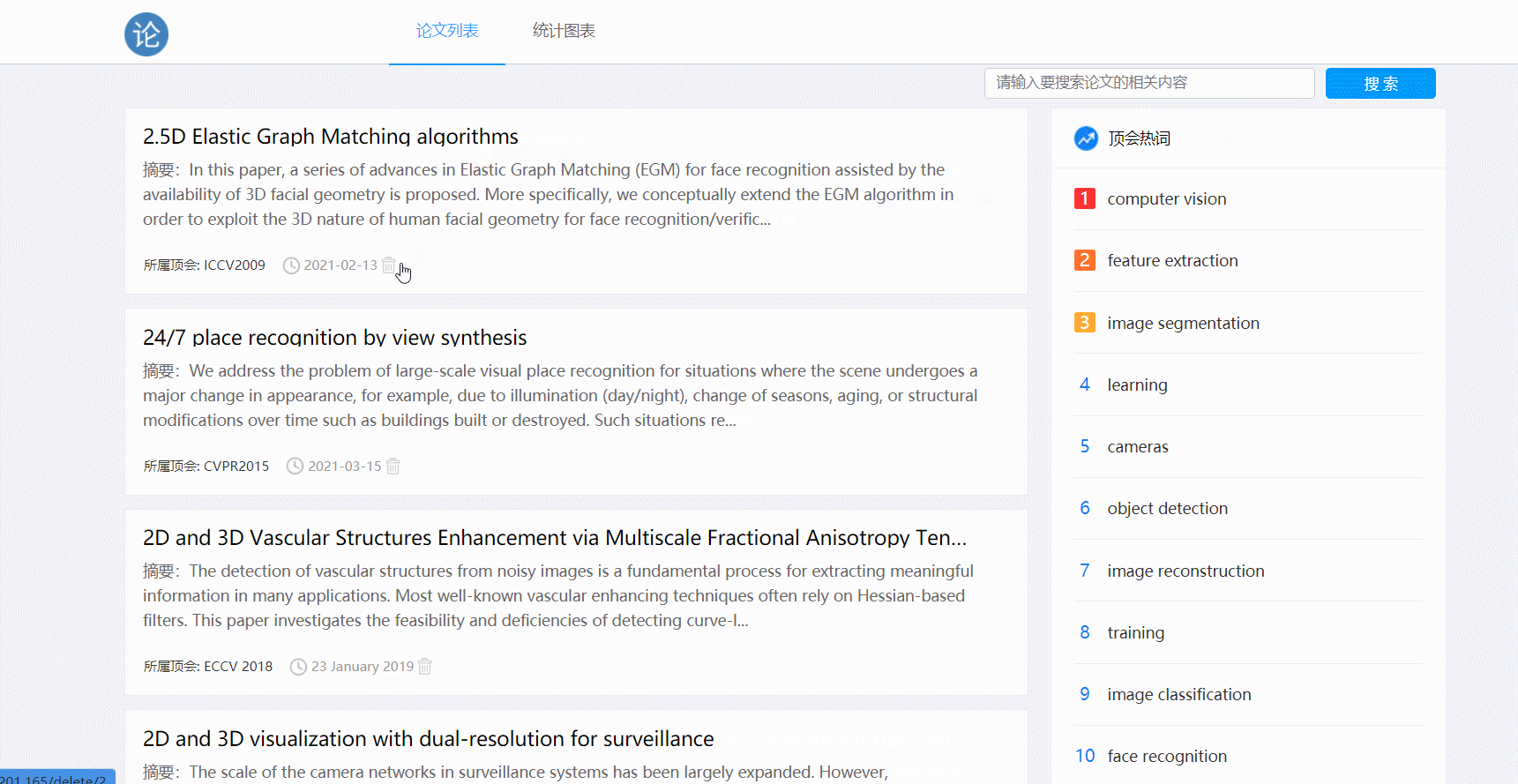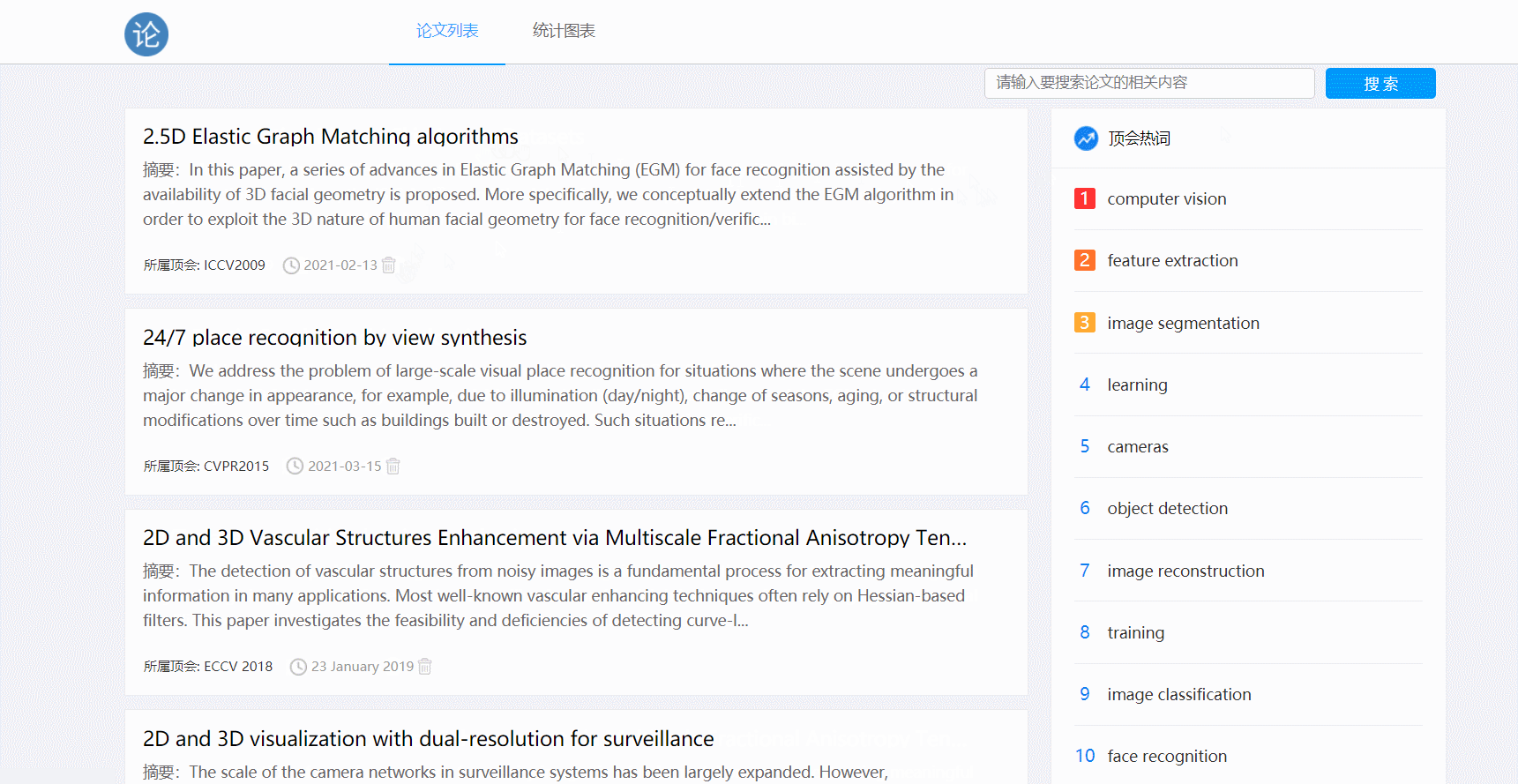
- 点击原文链接跳转功能
六、结对过程描述
首先我们都熟悉了一遍作业要求,大概了解了所需要的功能,进行了需求分析。后面我们就考虑实现和协作编程方面的问题,经过讨论,我们确定了前端使用纯html+css+js、后端使用flask框架进行开发的战略方针;协作编程方面当然是利用老朋友GitHub,我们下载了可视化软件GitHub Desktop和SourceTree来提高协作效率,可视化对仓库的操作,这样在协作过程中不容易出差错。我们先首先进行模板页面的设计,去网上查找了一些参考的页面,我们编写html文件设计出了大致的页面风格,后面的页面风格就统一了。然后我们划分出几个功能模块并进行分工,共同写后端代码,最后将实现完成的功能推送到远程仓库进行整合。GitHub协作中遇到多次冲突的问题,刚开始只能先把冲突文件移走,再拉取远程仓库的文件,很麻烦。后面使用SourceTree对冲突文件进行暂存,再拉取,再取回暂存文件来手动解决冲突,解决。
- 结对编程图片


七、设计实现过程
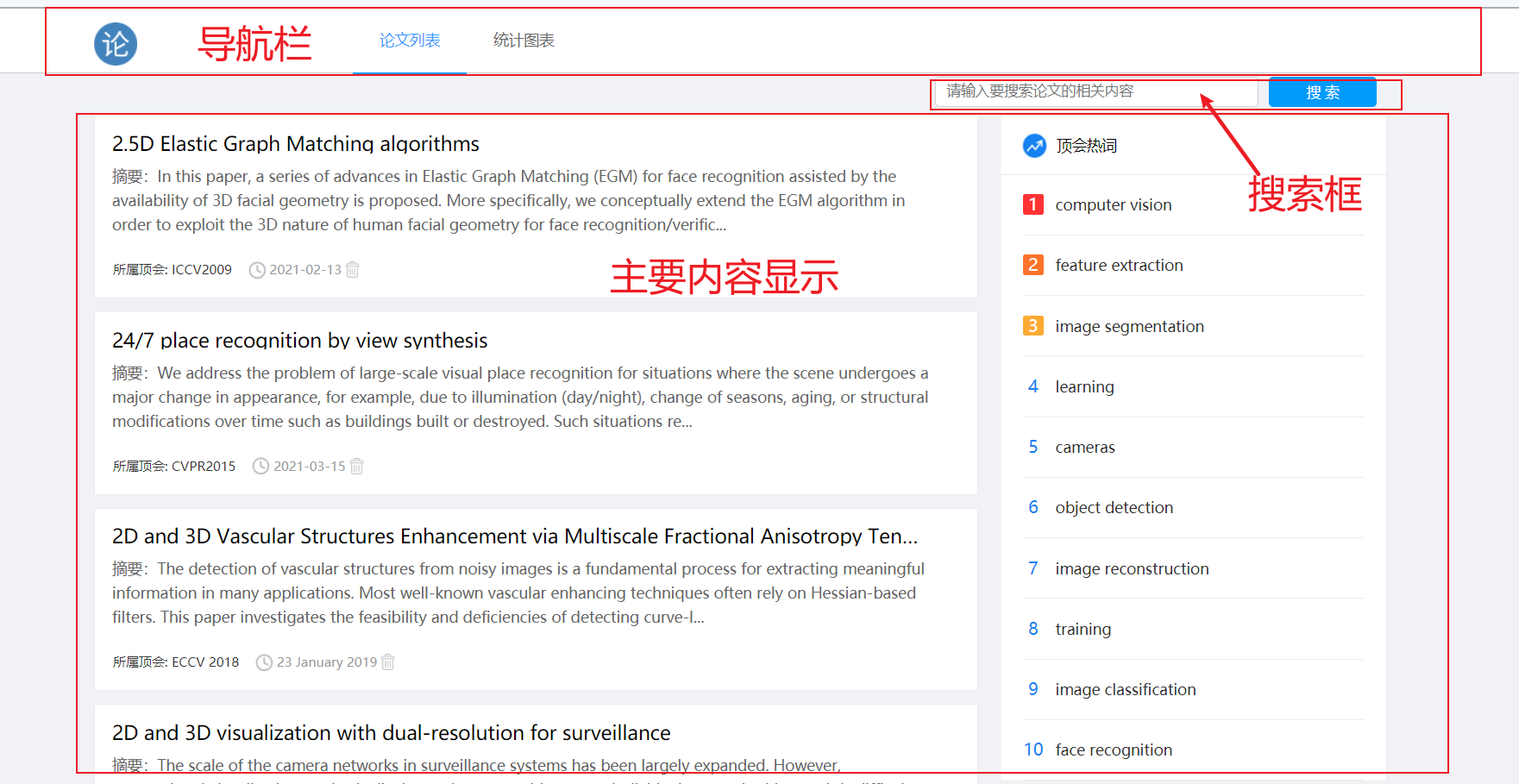
主要的功能是展示论文列表、搜索论文、显示图表,我们根据这个来设计网页的区块。
前端
导航栏:首页 - 论文列表 - 统计图表

搜索框
主要内容:论文列表 - 热词排行
列表分页:计划使用js配合后端传值实现,同时借助css来美化分页的区域
后端
后端给前端页面传递数据,每个页面都需要有对应的函数来填充数据渲染页面。
渲染论文列表页时要传递论文的概要,包括标题、时间、摘要等,实现分页功能方便浏览;或者显示搜索查询到的论文列表
渲染论文详情页页时要传递论文完整的相关信息
渲染图表页时传递图表需要的数据
数据库设计
paper表用于保存所有的论文数据

部署
本项目部署在系统为Ubuntu 16.04 64位系统的云服务器上。便于今后能够在服务器上调试各种版本的Web框架, python解释器,在服务器上部署Python的虚拟环境创建,并且让该项目在一个虚拟环境中运行。最终为了负载均衡,使用后台运行Nginx转发Gunicorn服务加提升实际运行的性能效率。
功能结构图
八、代码说明
- 模型类的定义,这些模型类用于和数据库表映射起来。这是SQLAlchemy框架的用法,这是一个使用了ORM框架的技术,以后操作数据库可以对模型类进行操作而不用写sql语句了。
- Paper模型类中的to_short_dict()方法用于切分摘要,因为摘要很长,在论文列表中没必要全部显示出来。
class Paper(db.Model):
__tablename__ = 'paper'
id = db.Column(db.Integer, autoincrement=True, primary_key=True)
title = db.Column(db.String(255))
abstract = db.Column(db.Text)
typeandyear = db.Column(db.String(255))
keywords = db.Column(db.Text)
releasetime = db.Column(db.String(255))
link = db.Column(db.String(255))
def to_short_dict(self):
if self.abstract:
if len(self.abstract) > 300:
abstract = self.abstract[0:300]+"..."
else:
abstract = self.abstract
else:
abstract = 'null'
paper = {
"id": self.id,
"title": self.title,
"abstract": abstract,
"typeandyear": self.typeandyear,
"keywords": self.keywords,
"releasetime": self.releasetime,
"link": self.link
}
return paper
def __repr__(self):
return '<title:%s %s>' % (self.title, self.abstract)
class TopWord(db.Model):
__tablename__ = "topword"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(255))
frequency = db.Column(db.Integer)
class Analysis(db.Model):
__tablename__ = "analysis"
id = db.Column(db.Integer, autoincrement=True, primary_key=True)
keywordid = db.Column(db.String(255))
keyword = db.Column(db.String(255))
frequency = db.Column(db.String(255))
type = db.Column(db.String(255))
year = db.Column(db.String(255))
- 首页功能的实现
- 显示论文列表,热词排行:使用装饰器实现路由功能,把主页页面和函数映射起来,访问主页时就会调用函数,函数调用query.filter方法将数据库内符合条件的论文基本信息(如果没使用搜索功能则所有论文符合条件),热词返回给页面,最后通过Flask内置的Jinja2模板引擎将每篇论文数据正确显示在页面上
- 分页显示:增加当前页码,总页码作为参数传给前台js。通过request.args方法得到将要加载的页码,利用传入的Page等相关属性方法动态生成分页的相关内容
- 搜索功能:利用request.args.get获取用户搜索栏输入的信息,利用该条件调用主页的query.filter方法获取数据库内符合条件的论文基本信息,将数据返回给主页渲染模板
- 相关代码
# Python 显示首页/搜索
@app.route('/')
def hello_world():
# 分页展示论文列表
page = request.args.get("p", "1")
# 搜索的关键词
keywords = request.args.get("keywords", "")
keywords = keywords.replace('+', ' ')
filters = []
isSearch = False
perPage = 10
if keywords:
isSearch = True
filters.append(Paper.title.contains(keywords))
perPage = Paper.query.filter(*filters).count()
page = int(page)
paginate = Paper.query.filter(*filters).order_by("title").paginate(page, perPage, False)
totalPage = paginate.pages
currentPage = page
items = paginate.items
paper_list = []
for paper in items:
paper_list.append(paper.to_short_dict())
# 顶会热词获取
topWord = TopWord.query.all()
top_list = []
for i in topWord:
top_list.append(i.name)
data = {
"isSearch": isSearch,
"totalPage": totalPage,
"currentPage": currentPage,
"top": top_list,
"paper": paper_list,
"searchCount": perPage,
"searchWord": keywords
}
return render_template("index.html", data=data)
<!--首页功能的关键html/js代码-->
<ul class="list_con fl">
{% if data.isSearch %}
<p>根据{{ data.searchWord }}搜索到相关结果如下,共计{{ data.searchCount }}条结果:</p>
{% endif %}
{% for paper in data.paper %}
<li>
<a href="/detail/{{ paper.id }}" class="paper_title fl">{{ paper.title }}</a>
<span class="paper_detail fl">摘要:{{ paper.abstract }}</span>
<div class="type_info fl">
<div class="type fl">
<span> 所属顶会: {{ paper.typeandyear }}</span>
</div>
<div class="time fl">{{ paper.releasetime }}</div>
<div><a href="/delete/{{ paper.id }}" title="从列表中删除"><img src="../static/info/images/delete.png" alt="delete" width="20" height="20"></a></div>
</div>
</li>
{% endfor %}
<div id="pagination" class="page"></div>
<script>
$(function() {
$("#pagination").pagination({
currentPage: {{ data.currentPage }},
totalPage: {{ data.totalPage }},
callback: function(current) {
window.location.href = "/?p="+current;
}
});
});
</script>
</ul>
- 实现删除列表中的论文
- 创建要删除的paper对象,添加delete会话并执行
# 从列表中删除
@app.route('/delete/<id>')
def delete(id):
paper = Paper.query.filter(Paper.id == id).first()
db.session.delete(paper)
db.session.commit()
return redirect('/')
- 实现点击论文跳转对应详情页
- 这里使用装饰器实现路由功能,把详情页面的url和视图函数goto_detail()映射起来,当要访问详情页面的url时就会调用视图函数,获得页面所需要的数据,在跳转页面的同时传入数据,对详情页面进行渲染
- a标签的href属性,通过变量语句块来实现详情页的动态url,这样不用的论文才能显示不同的详情页
@app.route('/detail/<path:id>')
def goto_detail(id):
topWord = TopWord.query.all()
top_list = []
for i in topWord:
top_list.append(i.name)
detail = Paper.query.filter_by(id=id).first()
if detail.keywords is None:
detail.keywords = "暂无"
data = {
'title': detail.title,
'abstract': detail.abstract,
'typeandyear': detail.typeandyear,
'keywords': detail.keywords,
'releasetime': detail.releasetime,
'link': detail.link,
'top': top_list
}
return render_template('detail.html', data=data)
<a href="/detail/{{ paper.id }}" class="paper_title fl">{{ paper.title }}</a>
- 实现跳转图表页面功能
- 将数据传入图表页面,对图表页面进行渲染
- 图表使用的是e-chart,开源的阿可视化图标库。在页面文件中使用后端传过来的数据对图表进行数据填充
@app.route('/chart')
def goto_chart():
topWord = TopWord.query.all()
top_list = []
for i in topWord:
top_list.append(i.name)
# 对分析的数据进行分类
list_word = ['learning', 'feature extraction', 'training', 'image recon',
'neural nets', 'task analysis', 'computer vision', 'cameras',
'object detection', 'convolutional neural nets']
paper_type = ['CVPR', 'ECCV', 'ICCV']
cvpr_year = [2020, 2019, 2018]
eccv_year = [2020, 2018, 2016]
iccv_year = [2019, 2017, 2015]
year_list = [cvpr_year, eccv_year, iccv_year]
analysis_list = []
for i in range(3):
for j in range(3):
temp_list = Analysis.query.filter_by(type=paper_type[i], year=year_list[i][j])\
.order_by(Analysis.keyword).all()
analysis_list.append(temp_list)
paper_count_list = []
for i in range(3):
temp = Paper.query.filter(Paper.typeandyear.contains(paper_type[i])).count()
paper_count_list.append(temp)
data = {
'top': top_list,
'list_word': list_word,
'analysis_list': analysis_list,
'paper_count': paper_count_list
}
return render_template('chart.html', data=data)
<script src="https://cdn.jsdelivr.net/npm/echarts@5.0.2/dist/echarts.min.js"></script>
……
<div id="container_pie" style="height: 400px;"></div>
<script>
var dom = document.getElementById("container_pie");
var myChart = echarts.init(dom);
var option;
data: [
{% for i in range(10) %}
'{{ data.analysis_list[6][i].frequency }}',
{% endfor %}
]
其他填充数据部分,省略
myChart.setOption(option);
</script>
九、心路历程和收获、互相评价
心路历程和收获
429:
心路历程:看完作业要求,一块分析完需求之后,我的想法是:网页要完成的基础功能并不算太多(对已爬取论文列表展示、搜索、图标等功能)。考虑到对方可能web的开发经历不多,我们选择使用轻量级易上手使用Python编写的Flask框架着手开发。自身有很长时间没有使用Flask编写项目过,因此我又重新回顾了Flask以及相关扩展的文档才开始项目的工作。开始工作之后,我发现工作量其实比我想象中的要少,432同学学习上手的速度很快,及时帮我分担了相当的工作量,图表的设计也是432及时提供了有用的建议,使得图表部分的功能得到了很快的推进。反倒我自己由于很久没有接触Python加上习惯了Java这类强类型的语言,在编码的过程吃了不少由于类型不当产生错误的苦头,在之后渐渐重新适应了Python的语言风格,避免低级的bug的出现,后面还算顺利的完成了项目工作。第一次使用云服务部署的时候,我的心里没底,不知道在过程中会遇到什么样的错误。就这样一边学习Linux指令一边进行部署,虚拟环境安装、相关库的导入、Web代理服务器的部署……这样一步步走下去,好在遇到七七八八的问题都能够在网上找到解决方案,部署的过程总体来说比我想象中的要顺利一些。最后能通过外网丝滑流畅地访问到我们共同完成的网页时,内心的成就感是通过本地访问Web项目时不能比拟的。
收获:这次的结对项目我在重温Python的Web框架同时,也学习到了如何使用Ubuntu系统的云服务器部署Python的Web项目,同时还深刻认识到到在两人同时进行一个项目时有效的沟通,比具体的埋头编码更有效率,团队分工有时候可以做到1+1>2的效果。由于是进行同一个项目,以前遇到一个小问题可能就要折腾大半天,效率十分低而且也没学到什么新东西,现在两人进行同一个项目,可以直接向对方提问往往能更及时得到有效的反馈。这次结对编程的过程,对我也是共同学习小项目如何互相交流分工、两个收到二人小团队的驱使,互相学习新知识的过程。
432:
心路历程:Web开发的经历很少,所以我刚开始并不知道从何学起。Web有分前后端,奈何我哪个都不懂,我便想得快点确定我们要使用的技术栈才能着手进行学习。与我结对的429有开发经验,他建议后端使用flask框架,不得不说,确实是个明智的选择,因为我们至少做出了点东西。开始学习后就没有了那种无所适从的感觉,就想着赶紧学然后推进项目的开发,分担结对成员的工作量。收获:学习新的东西都需要基础知识,至少需要点,不能完全没有。如果没有提前了解到python是一个弱类型语言和python的语法,我直接学flask框架的效率肯定不高,遇到一个看不懂的地方就需要去查百度,然后稍微有了经验才发现这根本就是基础,基础不牢固再去查找资料实在很浪费时间。幸好python的语法不算特别难,有些语法与曾经学过的语言大同小异。

互相评价
429:432同学是一个靠谱的好队友,学习框架技术时积极提问,学习了一段时间后就很快就有开始项目编码的能力了,他的代码符合约定的代码规范,看起来条理也十分清晰,在结对编程审阅代码的时候我就有一种赏心悦目的感觉,一看就能明白代码的功能。在交流的时候也十分善于沟通,对待项目任务也很负责任,经常在我还没发现的时候,自己就提出不足之处并改进,往往获得比预期更好的效果。432同学相当靠谱。
432:429同学永远滴神👍,选择了flask框架是关键的一步棋,带领没有Web开发经验的我走向胜利。编程过程中出现的异常等情况,我都请教他,他也乐于帮助,总是能顺利解决我遇到的问题,真不错。在他的帮助下,我也逐渐熟悉python和flask框架,获取知识的快乐不亚于抽卡一发入魂,总而言之,与429同学的结对是一次很不错的体验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号