编译原理-针对任意文法的递归下降分析
要求
递归下降分析
- 对文法进行LL(1)判别,若不是LL(1)文法,则进行等价变换。构造预测分析表。
- 编程实现递归下降分析。
完成情况
在完成已有实验要求的基础上,增加实现以下功能:
- 使之可以针对任意文法实现递归下降分析。(对应的文法规则和预测分析表从文件中读入)
- 使用括号表示法输出语法分析树。
代码实现
#include<stdio.h>
//以下均为最大长度,可根据需求更改
#define vt_n 100
#define vn_n 100
#define gra_n 20
#define gra_len 20
#define ERROR -1
//sym为当前可匹配字符
//a[]暂存输入串,且最大长度为50
char sym,a[50];
int ip=0;
//当前读入文法规则及其数目
int vt_num;
int vn_num;
int gra_num;
char vt[vt_n];
char vn[vn_n];
char grammar[gra_n][gra_len];
int pre[vn_n][vt_n];
struct Tnode{
char c;
int num; //子节点的个数
struct node * next[10];
};
void init();
void cin();
//pvn位当前所处的状态(即非终结符),p为传入的指向当前节点指针的指针
int RD( char pvn, struct Tnode **p);
//T为指向树根节点的头指针
void printfT( struct Tnode *T );
void DTree( struct Tnode *T );
void getNextSym();
struct Tnode * JTree( char c );
//================================================
void main() /*递归分析*/
{
int ret;
struct Tnode *T; //指向根节点的指针
init();
cin();
while(1){
T=NULL;
printf("\ninput length < 50,ending with'#'; '^#' to return!\n");
ip=0;
do{
scanf("%c",&sym);
a[ip++]=sym;
}while(sym!='#');
if(a[0]=='^' && a[1]=='#')
return;
printf("......begin......\n");
ip=-1;
getNextSym();
ret=RD( 'S', &T);
if (ret!= ERROR && sym=='#')
printf("......accept!\n");
else
printf("sym=%c......error!\n",sym);
//可以选择正确时再输出分析树,此处为了显示错误结果
printfT(T);
DTree(T);
getchar();
}
}
//================================================
void init(){ /*初始化*/
memset( vt, '/0', sizeof(vt));
memset( vn, '/0', sizeof(vn));
memset( grammar, '\0', sizeof(grammar));
memset( pre, -1, sizeof(pre));
return ;
}
//================================================
void cin(){ /*文法读入函数*/
FILE * fp;
int i,j;
//此处修改要读取的文法文件
fp=fopen("./test2.txt", "r");
fscanf( fp, "%s", vt);
fscanf( fp, "%s", vn);
for( i=0; i<vt_n; i++)
if( vt[i]=='\0' ){
vt_num=i;
break;
}
for( i=0; i<vn_n; i++)
if( vn[i]=='\0' ){
vn_num=i;
break;
}
fscanf( fp, "%d", &gra_num);
for( i=0; i<gra_num; i++)
fscanf( fp, "%s", grammar[i]);
for( i=0; i<vn_num; i++)
for( j=0; j<vt_num; j++)
fscanf( fp, "%d", &pre[i][j]);
fclose(fp);
return ;
}
//================================================
void getNextSym(){ /*取输入串的下一字符*/
sym=a[++ip];
printf(" sym=%c\n",sym);
}
//================================================
struct Tnode * JTree( char c ){ /*建立新结点*/
struct Tnode * pnode;
pnode=( struct Tnode *)malloc(sizeof( struct Tnode ) );
pnode->c=c;
pnode->num=0;
return pnode;
};
//================================================
void printfT( struct Tnode *T ){ /*遍历输出树*/
int i=0;
if( T->num==0 ){
printf("%c",T->c);
return ;
}
printf("%c ",T->c);
printf("(");
for( i=0; i<T->num; i++)
printfT( T->next[i] );
printf(")");
return ;
}
//================================================
void DTree( struct Tnode *T ){/*销毁树*/
int i;
if( T->num==0 ){
free( T );
return ;
}
for( i=0; i<T->num; i++)
DTree( T->next[i] );
free(T);
}
//================================================
int RD( char pvn, struct Tnode **p){ /*递归下降分析*/
int i; //循环变量
int row=-1; //预测分析表行下标
int tmp=-1; //预测分析表列下标,即对应语句下标
struct Tnode *pnode, *tmp_node;
//查找此时非终结符对应的下标
for( i=0; i<vn_num; i++)
if( pvn==vn[i] )
row=i;
//查表找到对应语句下标
for( i=0; i<vt_num; i++)
if( sym==vt[i] )
tmp=pre[row][i];
//可以分开判断是错误字符还是没匹配上
if( tmp==-1 || tmp==0 )
return ERROR;
//建当前节点
pnode=JTree(pvn);
*p=pnode;
//找到对应的语句了,进行拆分
for( i=2; grammar[tmp][i]!='#'; i++){
//printf("grammar=%c\n",grammar[tmp][i]);
if( grammar[tmp][i]<'A' || grammar[tmp][i]>'Z' ){
if( grammar[tmp][i]=='^' ){//树显示^表示替换为空串
//遇到终结符直接建立子节点并将其加入。下同
pnode->next[pnode->num++]=JTree(grammar[tmp][i]);
return 0;
}
if( sym==grammar[tmp][i] ){
pnode->next[pnode->num++]=JTree(grammar[tmp][i]);
printf("%s\n",grammar[tmp]);
getNextSym();
}
else//此处可添加对语法分析树的构造以保证语法分析树的完整
return ERROR;
}
else{//并非直接return RD(),否则判断成功后将导致后续的非终结符无法判断
if( RD( grammar[tmp][i], &pnode->next[pnode->num++])==ERROR )
return -1;
}
}
return 0;
}
测试结果
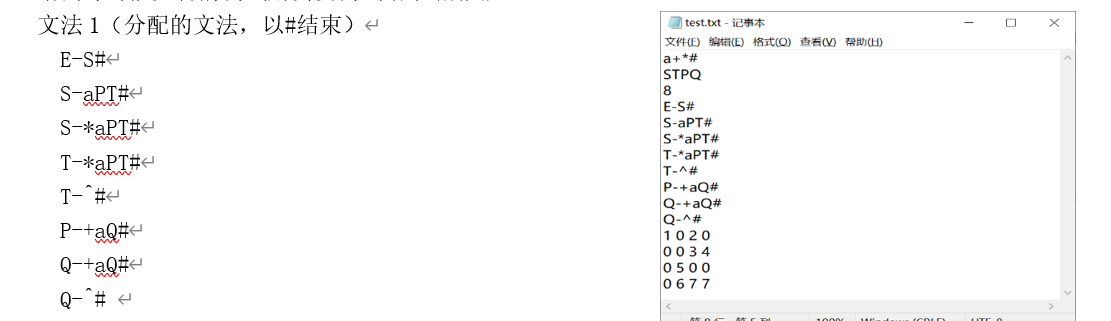
正确串
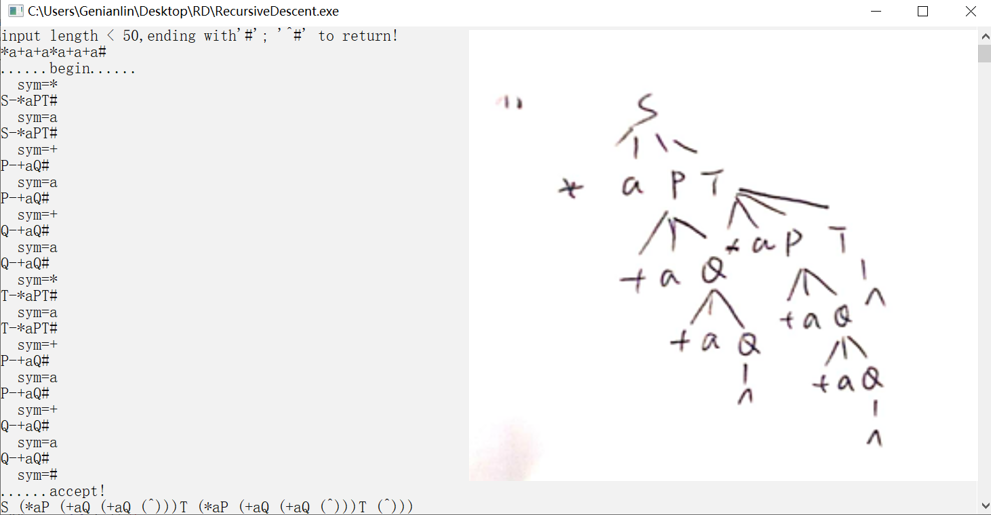

错误串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号