

网络情况
网络带宽的单位bps,b表示的bit,一个Byte=8bit。一般常说的10M带宽,10Mbps=10/8=1.25MBps(Byte)
Mps是每秒传输的兆比特位数,是速度单位。MBps,指每秒传输多少兆字节,Mbps=Mbit/s即兆比特每秒。
千兆网卡以太网理论上的限制是 128MB。这个数字从何而来?看看这些计算:
1Gb = 1024Mb;1024Mb/8 = 128MB;"b" = "bits,"、"B" = "bytes"
千兆带宽,都是全双工的,即上行(上传)与下行(下载)都是千兆,理论都为128MB/s,但是网络都有损耗,按20%损耗实际带宽会是100MB/s。
一、环境检查
linux下网卡相关检查
1、先用ifconfig看看有多少块网卡和bonding。bonding是个很棒的东西,可以把多块网卡绑起来,突破单块网卡的带宽限制。
2、检查每块网卡的速度,比如"ethtool eth0"。再检查bonding,比如"cat /proc/net/bonding/bond0", 留意其Bonding Mode是负载均衡的,再留意其捆绑的网卡的速度。
3、查看网卡是否支持多队列,是否打开了多队列,最后确认每个队列是否绑定到不同的CPU。
4、最后检查测试客户机与服务机之间的带宽,先简单ping或traceroute 一下得到RTT时间,iperf之类的可稍后。
网卡模式
当主机有1个以上的网卡时,Linux会将多个网卡绑定为一个虚拟的bonded网络接口,对TCP/IP而言只存在一个bonded网卡。多网卡绑定一方面能够提高网络吞吐量,另一方面也可以增强网络高可用。
可以通过cat/proc/net/bonding/bond0查看本机的Bonding模式
一般很少需要开发去设置网卡Bonding模式。Linux支持7种Bonding模式(详细的看内核):
-
Mode 0(balance-rr) Round-robin策略,这个模式具备负载均衡和容错能力
-
Mode 1(active-backup) 主备策略,在绑定中只有一个网卡被激活,其他处于备份状态
-
Mode 2(balance-xor) XOR策略,通过源MAC地址与目的MAC地址做异或操作选择slave网卡
-
Mode 3 (broadcast) 广播,在所有的网卡上传送所有的报文
-
Mode 4 (802.3ad) IEEE 802.3ad动态链路聚合。创建共享相同的速率和双工模式的聚合组
-
Mode 5 (balance-tlb) Adaptive transmit loadbalancing
-
Mode 6 (balance-alb) Adaptive loadbalancing
查看机器网卡速度
windows
打开"网络和共享中心"->选择网络,查看网络连接状态。如下图所示:
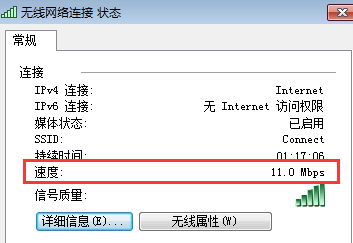
11Mbps
linux
使用查询及设置网卡参数的命令ethtool(http://man.linuxde.net/ethtool)查看,如使用ethtool eth1
# ethtool eth1 Settings for eth1: Supported ports: [ TP ] Supported link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full Supports auto-negotiation: Yes Advertised link modes: 10baseT/Half 10baseT/Full 100baseT/Half 100baseT/Full 1000baseT/Full Advertised auto-negotiation: Yes Speed: 1000Mb/s Duplex: Full Port: Twisted Pair PHYAD: 0 Transceiver: internal Auto-negotiation: on Supports Wake-on: umbg Wake-on: d Link detected: yes
操作完毕后,输出信息中Speed:这一项就指示了网卡的速度。
网卡多队列及中断绑定
随着网络的带宽的不断提升,单核CPU已经不能满足网卡的需求,这时通过多队列网卡驱动的支持,可以将每个队列通过中断绑定到不同的CPU核上,充分利用多核提升数据包的处理能力。
1)查看网卡是否支持多队列
使用lspci -vvv命令,找到Ethernetcontroller项:
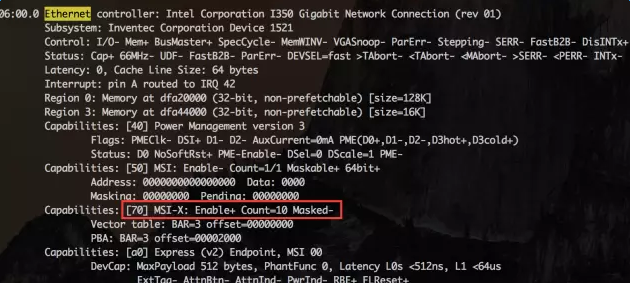
如果有MSI-X, Enable+ 并且Count > 1,则该网卡是多队列网卡。网卡的中断机制是MSI-X,即网卡的每个队列都可以分配中断(MSI-X支持2048个中断)。
备注:linux 2.6.32 上有lspci命令,但无-vvv参数。
2)查看是否打开了网卡多队列。
使用命令cat/proc/interrupts,如果看到eth0-TxRx-0表明多队列支持已经打开:
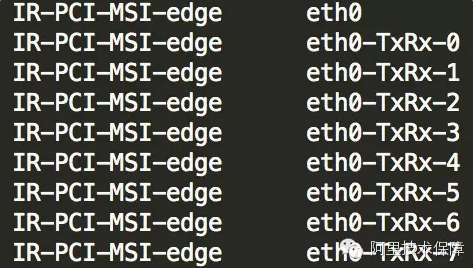
- /proc/interrupts:该文件存放了每个I/O设备的对应中断号、每个CPU的中断数、中断类型。
- /proc/irq/:该目录下存放的是以IRQ号命名的目录,如/proc/irq/40/,表示中断号为40的相关信息
- /proc/irq/[irq_num]/smp_affinity:该文件存放的是CPU位掩码(十六进制)。修改该文件中的值可以改变CPU和某中断的亲和性
- /proc/irq/[irq_num]/smp_affinity_list:该文件存放的是CPU列表(十进制)。注意,CPU核心个数用表示编号从0开始,如cpu0,cpu1等
-
smp_affinity_list和smp_affinity任意更改一个文件都会生效,两个文件相互影响,只不过是表示方法不一致,但一般都是修改smp_affinity 文件
3)最后确认每个队列是否绑定到不同的CPU。
cat/proc/interrupts查询到每个队列的中断号,对应的文件/proc/irq/${IRQ_NUM}/smp_affinity为中断号IRQ_NUM绑定的CPU核的情况。以十六进制表示,每一位代表一个CPU核:(00000001)代表CPU0(00000010)代表CPU1(00000011)代表CPU0和CPU1。
中断的亲缘性设置可以在 cat /proc/irq/${中断号}/smp_affinity 或 cat /proc/irq/${中断号}/smp_affinity_list 中确认,前者是16进制掩码形式,后者是以CPU Core序号形式。例如下图中,将16进制的400转换成2进制后,为 10000000000,“1”在第10位上,表示亲缘性是第10个CPU Core。

那为什么中断号只设置一个CPU Core呢?而不是为每一个中断号设置多个CPU Core平行处理。经过测试,发现当给中断设置了多个CPU Core后,它也仅能由设置的第一个CPU Core来处理,其他的CPU Core并不会参与中断处理,原因猜想是当CPU可以平行收包时,不同的核收取了同一个queue的数据包,但处理速度不一致,导致提交到IP层后的顺序也不一致,这就会产生乱序的问题,由同一个核来处理可以避免了乱序问题。
如果绑定的不均衡,可以手工设置,例如:
echo "1" > /proc/irq/99/smp_affinity echo "2" > /proc/irq/100/smp_affinity echo "4" > /proc/irq/101/smp_affinity echo "8" > /proc/irq/102/smp_affinity echo "10" > /proc/irq/103/smp_affinity echo "20" > /proc/irq/104/smp_affinity echo "40" > /proc/irq/105/smp_affinity echo "80" > /proc/irq/106/smp_affinity
上述命令使用时需要注意一个是权限,一个是不同系统之间命令的差异。
理论参考:多队列网卡CPU中断均衡
检查实际带宽
可以先做ping、traceroute看下 参考资料:网络丢包分析
- 监控总体带宽使用――nload、bmon、slurm、bwm-ng、cbm、speedometer和netload
- 监控总体带宽使用(批量式输出)――vnstat、ifstat、dstat和collectl
- 每个套接字连接的带宽使用――iftop、iptraf、tcptrack、pktstat、netwatch和trafshow
- 每个进程的带宽使用――nethogs
可以在系统不繁忙或者临时下线前检测客户端和server或者proxy 的带宽:
1)使用 iperf -s 命令将 Iperf 启动为 server 模式:
iperf –s
————————————————————
Server listening on TCP port 5001
TCP window size: 8.00 KByte (default)
————————————————————2)启动客户端,向IP为10.230.48.65的主机发出TCP测试,并每2秒返回一次测试结果,以Mbytes/sec为单位显示测试结果:
iperf -c 10.230.48.65 -f M -i 2
在服务端上,运行:
# iperf -s -f M
这台机器将用作服务器并以'M' = MBytes/sec为单位输出执行速度。
在客户端节点上,运行:
# iperf -c ginger -P 4 -f M -w 256k -t 60
两个屏幕上的结果都指示了速度是多少。在使用千兆网卡的普通服务器上,可能会看到速度约为 112MB。这是 TCP 堆栈和物理电缆中的常用带宽。通过以端到端的方式连接两台服务器,每台服务器使用两个联结的以太网卡,获得了约 220MB的带宽。
ping命令
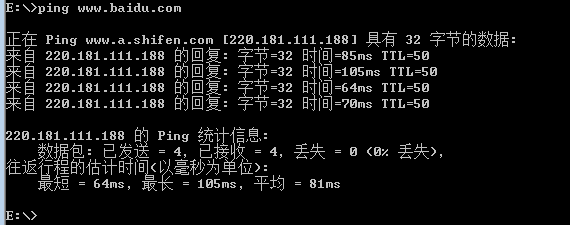
上边Ping www.a.shifen.com [220.181.111.188],这里的地址是指域名对应的服务器地址。
如hosts文件里,配置 220.181.111.188 www.a.shifen.com
tracert

查看环形缓冲区个数
它位于NIC和IP层之间,是一个典型的FIFO(先进先出)环形队列。RingBuffer没有包含数据本身,而是包含了指向sk_buff(socketkernel buffers)的描述符。
可以使用ethtool-g eth0查看当前RingBuffer的设置:
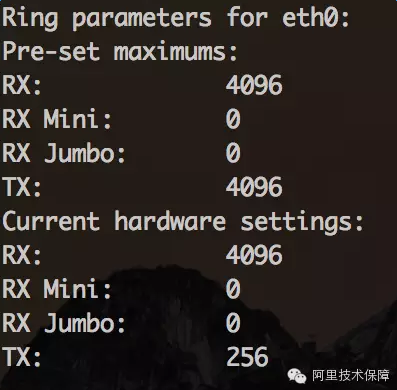
上面的例子接收队列为4096,传输队列为256。
ifconfig
ifconfig的输出中有两项,分别是:
RX==receive,接收,从开启到现在接收封包的情况,是下行流量。
TX==Transmit,发送,从开启到现在发送封包的情况,是上行流量。
ifconfig观察接收和传输队列的运行状况:
[root@test etc]# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:26:B9:58:19:88
inet addr:192.168.0.46 Bcast:192.168.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6049782538 errors:0 dropped:2373 overruns:0 frame:0
TX packets:7415059121 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2611876455455 (2.3 TiB) TX bytes:6028598337794 (5.4 TiB)
Interrupt:114 Memory:d8000000-d8012800
RX errors: 表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
RX dropped: 表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
RX overruns: 表示了 fifo 的 overruns,这是由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,而 CPU 无法及时的处理中断是造成 Ring Buffer 满的原因之一,例如中断分配的不均匀(都压在 core0),没有做 affinity 而造成的丢包。
RX frame: 表示 misaligned 的 frames。
当dropped数量持续增加,建议增大RingBuffer,使用ethtool-G进行设置。
对于 TX 的来说,counter 增大的原因主要包括 aborted transmission, errors due to carrirer, fifo error, heartbeat erros 以及 windown error,而 collisions 则表示由于 CSMA/CD 造成的传输中断。
txqueuelen 1000
QDisc(queueing discipline )位于IP层和网卡的ringbuffer之间。QDisc实现了流量管理的高级功能,包括流量分类,优先级和流量整形(rate-shaping)。可以使用tc命令配置QDisc。QDisc的队列长度由txqueuelen设置,和接收数据包的队列长度由内核参数net.core.netdev_max_backlog控制所不同,txqueuelen是和网卡关联。
RX和TX输出的值使有的单位参数是bytes,而利用该命令,我们也可以配置脚本进行流量检测。
大名鼎鼎的nagios就有一个插件check_traffic,通过ifconfig的输出的RX、TX值通过之间的差,再除去中间间隔的时间算出流量大小的。该插件的下载页为:https://github.com/cloved/check_traffic/downloads 。
现摘录其中部分关于度量值转换的部分如下:
#to K
uIn=`echo "$ctbpsIn / 1024" | bc`
uOut=`echo "$ctbpsOut / 1024" | bc`
#to M
if [ "$isM" = "True" ]; then
uIn=`echo "scale=$Scale; $uIn / 1024" | bc`
uOut=`echo "scale=$Scale; $uOut / 1024" | bc`
fi
#to B
if [ "$isB" = "True" ]; then
uIn=`echo "scale=$Scale; $uIn / 8" | bc`
uOut=`echo "scale=$Scale; $uOut / 8" | bc`
二、监控
关于CPU中断的监控
-
动态监控CPU中断情况,观察中断变化
watch -d -n 1 ‘cat /proc/interrupts’
-
查看网卡中断相关信息
cat /proc/interrupts | grep -E “eth|CPU”
-
网卡亲和性设置
修改proc/irq/irq_number/smp_affinity之前,先停掉irq自动调节服务,不然修改的值就会被覆盖。
/etc/init.d/irqbalance stop
通过查看网卡中断相关信息,得到网卡中断为19
[root@master ~]# cd /proc/irq/19 [root@master 19]# cat smp_affinity 00000000,00000000,00000000,00000001 [root@master 19]# cat smp_affinity_list 0
- 查看某个进程的CPU亲和性
# taskset -p 30011 pid 30011's current affinity mask: ff
- 设置某个进程的CPU亲和性
# taskset -p 1 30011 pid 30011's current affinity mask: ff pid 30011's new affinity mask: 1
- 使用-c选项可以将一个进程对应到多个CPU上去
# taskset -p -c 1,3 30011 pid 30011's current affinity list: 0 pid 30011's new affinity list: 1,3 # taskset -p -c 1-7 30011 pid 30011's current affinity list: 1,3 pid 30011's new affinity list: 1-7
可执行test.sh查看smp_affinity_list中的值的变化
#!/bin/bash irq=`grep 'eth' /proc/interrupts | awk '{print $1}' | cut -d : -f 1` for i in $irq do num=`cat /proc/irq/$i/smp_affinity_list` echo /proc/irq/$i/smp_affinity_list" "$num done
网卡绑定的时候最好和一个物理CPU的核挨个绑定,这样避免L1,L2,L3践踏。
使用systemtap诊断测试环境软中断分布的方法


global hard, soft, wq probe irq_handler.entry { hard[irq, dev_name]++; } probe timer.s(1) { println("==irq number:dev_name") foreach( [irq, dev_name] in hard- limit 5) { printf("%d,%s->%d\n", irq, kernel_string(dev_name), hard[irq, dev_name]); } println("==softirq cpu:h:vec:action") foreach( [c,h,vec,action] in soft- limit 5) { printf("%d:%x:%x:%s->%d\n", c, h, vec, symdata(action), soft[c,h,vec,action]); } println("==workqueue wq_thread:work_func") foreach( [wq_thread,work_func] in wq- limit 5) { printf("%x:%x->%d\n", wq_thread, work_func, wq[wq_thread, work_func]); } println("\n") delete hard delete soft delete wq } probe softirq.entry { soft[cpu(), h,vec,action]++; } probe workqueue.execute { wq[wq_thread, work_func]++ } probe begin { println("~") }
执行结果:
==irq number:dev_name 87,eth0-0->1693 90,eth0-3->1263 95,eth1-3->746 92,eth1-0->703 89,eth0-2->654 ==softirq cpu:h:vec:action 0:ffffffff81a83098:ffffffff81a83080:0xffffffff81461a00->8928 0:ffffffff81a83088:ffffffff81a83080:0xffffffff81084940->626 0:ffffffff81a830c8:ffffffff81a83080:0xffffffff810ecd70->614 16:ffffffff81a83088:ffffffff81a83080:0xffffffff81084940->225 16:ffffffff81a830c8:ffffffff81a83080:0xffffffff810ecd70->224 ==workqueue wq_thread:work_func ffff88083062aae0:ffffffffa01c53d0->10 ffff88083062aae0:ffffffffa01ca8f0->10 ffff88083420a080:ffffffff81142160->2 ffff8808343fe040:ffffffff8127c9d0->2 ffff880834282ae0:ffffffff8133bd20->1
下面是action对应的符号信息:
addr2line -e /usr/lib/debug/lib/modules/2.6.32-431.20.3.el6.mt20161028.x86_64/vmlinux ffffffff81461a00
/usr/src/debug/kernel-2.6.32-431.20.3.el6/linux-2.6.32-431.20.3.el6.mt20161028.x86_64/net/core/dev.c:4013
打开这个文件,发现它是在执行 static void net_rx_action(struct softirq_action *h)这个函数,而这个函数正是NET_RX_SOFTIRQ 对应的软中断处理程序。因此可以确认网卡的软中断在机器上分布非常不均,而且主要集中在CPU 0上。通过/proc/interrupts能确认硬中断集中在CPU 0上,因此软中断也都由CPU 0处理,如何优化网卡的中断成为了我们关注的重点。
set_irq_affinity.sh
# cat set_irq_affinity.sh # setting up irq affinity according to /proc/interrupts # 2008-11-25 Robert Olsson # 2009-02-19 updated by Jesse Brandeburg # # > Dave Miller: # (To get consistent naming in /proc/interrups) # I would suggest that people use something like: # char buf[IFNAMSIZ+6]; # # sprintf(buf, "%s-%s-%d", # netdev->name, # (RX_INTERRUPT ? "rx" : "tx"), # queue->index); # # Assuming a device with two RX and TX queues. # This script will assign: # # eth0-rx-0 CPU0 # eth0-rx-1 CPU1 # eth0-tx-0 CPU0 # eth0-tx-1 CPU1 # set_affinity() { if [ $VEC -ge 32 ] then MASK_FILL="" MASK_ZERO="00000000" let "IDX = $VEC / 32" for ((i=1; i<=$IDX;i++)) do MASK_FILL="${MASK_FILL},${MASK_ZERO}" done let "VEC -= 32 * $IDX" MASK_TMP=$((1<<$VEC)) MASK=`printf "%X%s" $MASK_TMP $MASK_FILL` else MASK_TMP=$((1<<(`expr $VEC + $CORE`))) MASK=`printf "%X" $MASK_TMP` fi printf "%s mask=%s for /proc/irq/%d/smp_affinity\n" $DEV $MASK $IRQ printf "%s" $MASK > /proc/irq/$IRQ/smp_affinity } if [ $# -ne 2 ] ; then echo "Description:" echo " This script attempts to bind each queue of a multi-queue NIC" echo " to the same numbered core, ie tx0|rx0 --> cpu0, tx1|rx1 --> cpu1" echo "usage:" echo " $0 core eth0 [eth1 eth2 eth3]" exit fi CORE=$1 # check for irqbalance running IRQBALANCE_ON=`ps ax | grep -v grep | grep -q irqbalance; echo $?` if [ "$IRQBALANCE_ON" == "0" ] ; then echo " WARNING: irqbalance is running and will" echo " likely override this script's affinitization." echo " Please stop the irqbalance service and/or execute" echo " 'killall irqbalance'" fi # # Set up the desired devices. # shift 1 for DEV in $* do for DIR in rx tx TxRx do MAX=`grep $DEV-$DIR /proc/interrupts | wc -l` if [ "$MAX" == "0" ] ; then MAX=`egrep -i "$DEV:.*$DIR" /proc/interrupts | wc -l` fi if [ "$MAX" == "0" ] ; then echo no $DIR vectors found on $DEV continue fi for VEC in `seq 0 1 $MAX` do IRQ=`cat /proc/interrupts | grep -i $DEV-$DIR-$VEC"$" | cut -d: -f1 | sed "s/ //g"` if [ -n "$IRQ" ]; then set_affinity else IRQ=`cat /proc/interrupts | egrep -i $DEV:v$VEC-$DIR"$" | cut -d: -f1 | sed "s/ //g"` if [ -n "$IRQ" ]; then set_affinity fi fi done done done
脚本参数是:set_irq_affinity.sh core eth0 [eth1 eth2 eth3] 可以一次设置多个网卡,core的意思是从这个号开始递增。
#./set_irq_affinity.sh 0 em1 no rx vectors found on em1 no tx vectors found on em1 em1 mask=1 for /proc/irq/109/smp_affinity em1 mask=2 for /proc/irq/110/smp_affinity em1 mask=4 for /proc/irq/111/smp_affinity em1 mask=8 for /proc/irq/112/smp_affinity em1 mask=10 for /proc/irq/113/smp_affinity em1 mask=20 for /proc/irq/114/smp_affinity em1 mask=40 for /proc/irq/115/smp_affinity em1 mask=80 for /proc/irq/116/smp_affinity #./set_irq_affinity.sh 8 em2 no rx vectors found on em2 no tx vectors found on em2 em2 mask=100 for /proc/irq/118/smp_affinity em2 mask=200 for /proc/irq/119/smp_affinity em2 mask=400 for /proc/irq/120/smp_affinity em2 mask=800 for /proc/irq/121/smp_affinity em2 mask=1000 for /proc/irq/122/smp_affinity em2 mask=2000 for /proc/irq/123/smp_affinity em2 mask=4000 for /proc/irq/124/smp_affinity em2 mask=8000 for /proc/irq/125/smp_affinity
关于网络流量的监控
watch -n 1 "/sbin/ifconfig eth0|grep bytes"
出现丢包问题分析思路
如果网络出现丢包,发现丢包是因为队列中的数据包超过了 netdev_max_backlog 造成了丢弃,因此首先想到是临时调大netdev_max_backlog能否解决燃眉之急,事实证明,对于轻微丢包调大参数可以缓解丢包,但对于大量丢包则几乎不怎么管用,内核处理速度跟不上收包速度的问题还是客观存在,本质还是因为单核处理中断有瓶颈,即使不丢包,服务响应速度也会变慢。因此如果能同时使用多个CPU Core来处理中断,就能显著提高中断处理的效率,并且每个CPU都会实例化一个softnet_data对象,队列数也增加了。
这部分丢包可以在cat /proc/net/softnet_stat的输出结果中进行确认:
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号