

scrapy实战--爬取最新美剧
现在写一个利用scrapy爬虫框架爬取最新美剧的项目。
准备工作:
目标地址:http://www.meijutt.com/new100.html
爬取项目:美剧名称、状态、电视台、更新时间
1、创建工程目录
mkdir scrapyProject cd scrapyProject
2、创建工程项目
scrapy startproject meiju100 cd meiju100 scrapy genspider meiju meijutt.com
3、查看目录结构
4、设置爬取项目(items.py)
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class Meiju100Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
storyName = scrapy.Field()
storyState = scrapy.Field()
tvStation = scrapy.Field()
updateTime = scrapy.Field()
5、编写爬取脚本(meiju.py)
# -*- coding: utf-8 -*-
import scrapy
from meiju100.items import Meiju100Item
class MeijuSpider(scrapy.Spider):
name = "meiju"
allowed_domains = ["meijutt.com"]
start_urls = ['http://www.meijutt.com/new100.html']
def parse(self, response):
items = []
subSelector = response.xpath('//ul[@class="top-list fn-clear"]/li')
for sub in subSelector:
item = Meiju100Item()
item['storyName'] = sub.xpath('./h5/a/text()').extract()
item['storyState'] = sub.xpath('./span[1]/font/text()').extract()
if item['storyState']:
pass
else:
item['storyState'] = sub.xpath('./span[1]/text()').extract()
item['tvStation'] = sub.xpath('./span[2]/text()').extract()
if item['tvStation']:
pass
else:
item['tvStation'] = [u'未知']
item['updateTime'] = sub.xpath('./div[2]/text()').extract()
if item['updateTime']:
pass
else:
item['updateTime'] = sub.xpath('./div[2]/font/text()').extract()
items.append(item)
return items
6、对爬取结果的处理
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import sys
reload(sys)
sys.setdefaultencoding('utf8')
class Meiju100Pipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
fileName = today + 'movie.txt'
with open(fileName,'a') as fp:
fp.write(item['storyName'][0].encode("utf8") + '\t' + item['storyState'][0].encode("utf8") + '\t' + item['tvStation'][0] + '\t' + item['updateTime'][0] + '\n')
return item
7、设置settings.py
……
ITEM_PIPELINES = {'meiju100.pipelines.Meiju100Pipeline':1}
8、启动爬虫
scrapy crawl meiju
9、结果
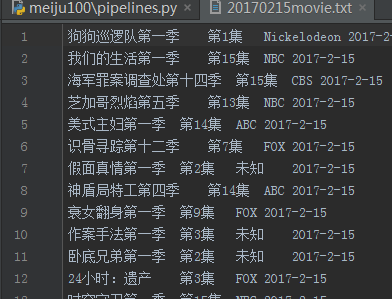
10、代码下载
https://files.cnblogs.com/files/kongzhagen/meiju100.zip


 浙公网安备 33010602011771号
浙公网安备 33010602011771号