HDFS的学习
一、HDFS的shell操作
用hadoop fs 和hdfs dfs两个都可以。
1.1上传
1)-moveFromLocal:从本地剪切粘贴到 HDFS
2)-copyFromLocal:从本地文件系统中拷贝文件到 HDFS 路径去
3)-put:等同于 copyFromLocal,生产环境更习惯用 put
4)-appendToFile:追加一个文件到已经存在的文件末尾
1.2下载
1)-copyToLocal:从 HDFS 拷贝到本地
2)-get:等同于 copyToLocal,生产环境更习惯用 get
1.3直接操作
1)-ls: 显示目录信息
2)-cat:显示文件内容
3)-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
4)-mkdir:创建路径
5)-cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
6)-mv:在 HDFS 目录中移动文件
7)-tail:显示一个文件的末尾 1kb 的数据
8)-rm:删除文件或文件夹
9)-rm -r:递归删除目录及目录里面内容
10)-du 统计文件夹的大小信息
11)-setrep:设置 HDFS 中文件的副本数量
二、hdfs的windows客户端API操作
2.1环境准备
1)配置 HADOOP_HOME 系统环境变量

2)在path路径下添加环境变量

3)配置完成后在window端hadoop路径下双击winutils.exe文件,没有报错就是正常的。
4)然后在IDEA中创建一个项目,加入maven依赖,如下
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
5)在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
6)在项目的resource目录下创建一个hdfs-site.xml文件,代码如下,可以设置hdfs中文件的副本数量,参数优先级排序:客户端代码中设置的值 > ClassPath 下的用户自定义配置文件 > 然后是服务器的自定义配置(xxx-site.xml) > 服务器的默认配置(xxx-default.xml)
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
2.2运行代码
创建一个java类,全部如下所示:(按需运行)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
public class HDFSClient {
public FileSystem fileSystem;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
URI uri = new URI("hdfs://hadoop102:8020");
Configuration configuration = new Configuration();
configuration.set("dfs.replication","1");//设置副本的数量,代码中为最高优先级
fileSystem = FileSystem.get(uri, configuration,"root");//不用root的话好像是没有权限
}
@After
public void close() throws IOException {
fileSystem.close();
}
@Test
public void tetsmkdir() throws URISyntaxException, IOException, InterruptedException {
fileSystem.mkdirs(new Path("/CMY"));//创建文件夹
}
@Test
public void testcreate() throws IOException {//创建一个文件
fileSystem.create(new Path("/CMY/hdfstest2.txt"));
}
@Test
public void testPut() throws IOException {//上传文件
//参数解读:参数一:表示是否删除要发送的原数据,参数二是否允许覆盖,参数三是文件原地址,参数四是文件目标地址
fileSystem.copyFromLocalFile(false,false,new Path("C:\\Users\\CM\\Desktop\\111.txt"),new Path("/CMY/"));
}
@Test
public void testGet() throws IOException {//从hadoop上下载文件
//参数解读:参数一:表示是否删除要发送的原数据,参数二是文件原地址,参数三是文件目标地址,参数四是否开启本地校验,true不开启,false开启
fileSystem.copyToLocalFile(false,new Path("/CMY/111.txt"),new Path("C:\\Users\\CM\\Desktop\\"),true);
}
@Test
public void tsetRm() throws IOException {//删除文件
//参数解读:参数一要删除的路径,参数二是否递归删除
fileSystem.delete(new Path("/CMY/111.txt"),true);
}
@Test
public void testMv() throws IOException {//文件的更名和移动
//参数解读:参数一原文件路径,参数二目标文件路径,rename可以用于改名,也可以移动文件,也可以同时移动文件和改名
fileSystem.rename(new Path("/CMY/111.txt"),new Path("/CMY/888.txt"));
}
@Test
public void fileDetail() throws IOException {//获取文件的详细信息(首先路径上有文件,不是文件夹)
//参数解读:参数一文件路径,参数二是否递归
RemoteIterator<LocatedFileStatus> listfiles = fileSystem.listFiles(new Path("/"),true);
//遍历文件
while(listfiles.hasNext()){
LocatedFileStatus fileStatus = listfiles.next();
System.out.println("--------"+fileStatus.getPath()+"--------");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));//存储的块的位置和角标
}
}
@Test
public void testFile() throws IOException {//判断是文件夹还是文件
FileStatus[] liststatus = fileSystem.listStatus(new Path("/"));
for(FileStatus status : liststatus){
if(status.isFile()){
System.out.println("文件:"+status.getPath().getName());
}else{
System.out.println("文件夹:"+status.getPath().getName());
}
}
}
@Test
public void testAppend() throws IOException {//从尾部添加
FSDataOutputStream fsDataOutputStream = fileSystem.append(new Path("/CMY/hdfstest2.txt"));
FSDataInputStream fsDataInputStream=fileSystem.open(new Path("/CMY/hdfstest1.txt"));
String data=fsDataInputStream.readLine();//将读取到的数据转成字符串
fsDataOutputStream.write(data.getBytes("ISO-8859-1"));//将字符串添加到文件尾部
fsDataInputStream.close();//关闭输入流
fsDataOutputStream.close();//关闭输出流
FSDataInputStream fsDataInputStream1=fileSystem.open(new Path("/CMY/hdfstest2.txt"));
IOUtils.copyBytes(fsDataInputStream1, System.out, 4096, false);// 输出文件内容直接打印在控制台上
IOUtils.closeStream(fsDataInputStream);// 关闭输入流
}
}
三、hdfs的读写(面试重点)
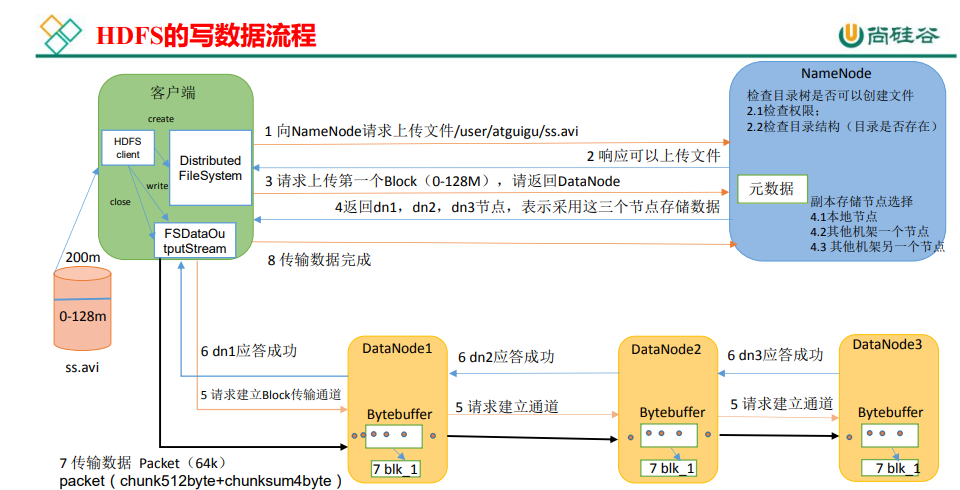
3.1 hdfs的写数据流程
引自尚硅谷教程p55
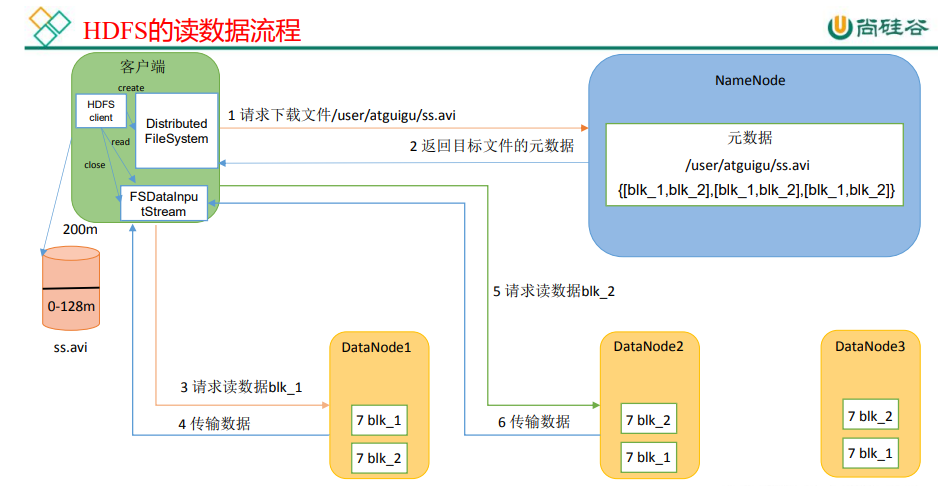
3.2 hdfs的读数据流程
引自尚硅谷教程p58
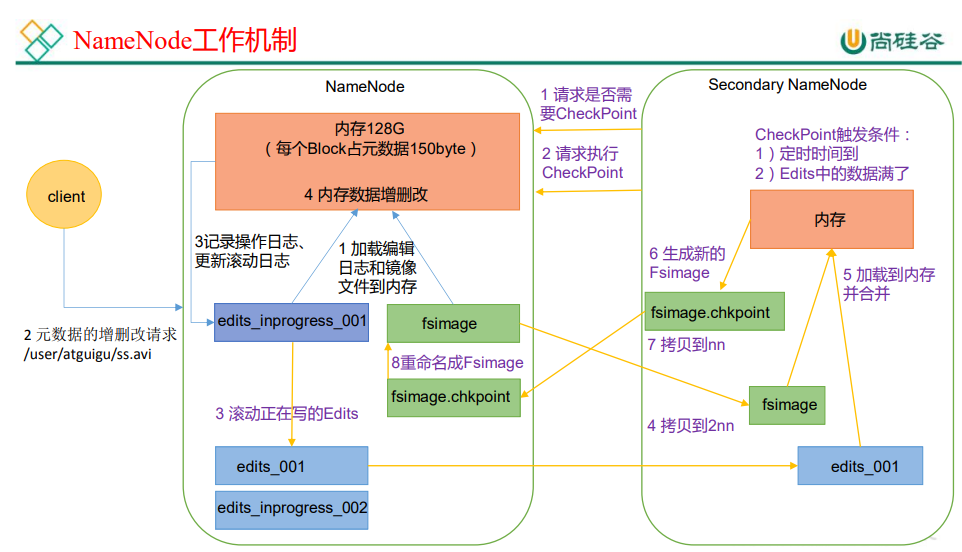
四、NameNode 和 SecondaryNameNode的工作机制
引自尚硅谷教程p59
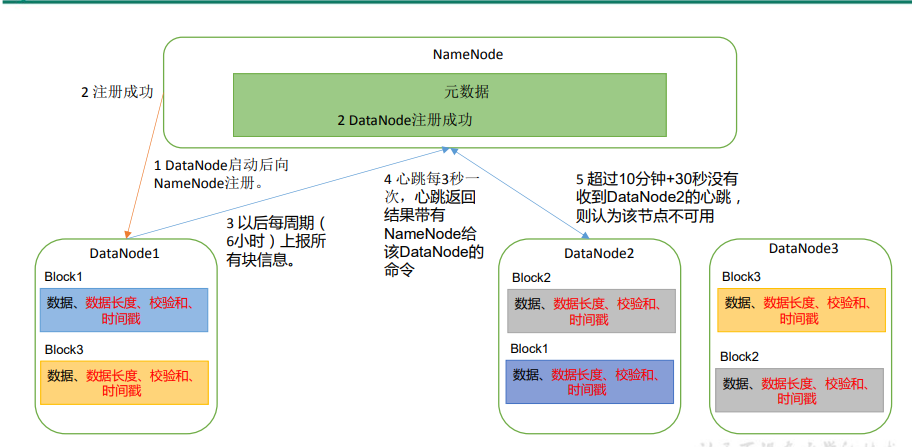
五、DataNode的工作机制
引自尚硅谷教程p63

 浙公网安备 33010602011771号
浙公网安备 33010602011771号