NVLink和NVSwitch
NVLink
NVLink主要加速CPU和NVIDIA GPU之间的互联速度,需要CPU的支持,例如IBM的Power的某些CPU支持,intel的CPU不支持;
也用于加速NVIDIA GPU和NVIDIA GPU之间的互联速度;
也用于加速NVIDIA GPU和NVIDIA GPU之间的互联速度;
是一种点对点结构的串行通信协议;
| 版本 | 速度 | Lans Per Link | 单向速度 Per Link | Link数 | In BW | Out BW | Total BW |
| 2014年 NVLink 1.0 | 20GT/s | 8+8 In + Out | 8bit*20GT/s=20GB/s | P100 With 4 Links | 80GB/s | 80GB/s | 160GB/s |
| 2018年 NVLink 2.0 | 25GT/s | 8+8 In + Out | 8bit*25GT/s=25GB/s | V100 With 6 Links | 150GB/s | 150GB/s | 300GB/s |
| 2020年 NVLink 3.0 | 50GT/s | 4+4 In + Out | 4bit*50GT/s =25GB/s | A100 With 12 Links | 300GB/s | 300GB/s | 600GB/s |
X16 PCIe Gen3 的带宽是16bit*8GT/s=16GB/s
X16 PCIe Gen4 的带宽是16bit*16GT/s=32GB/s
eg1: GPU与GPU通过NVLink1.0互联
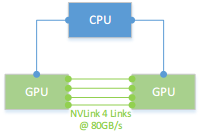
eg2: GPU与GPU通过NVLink1.0互联
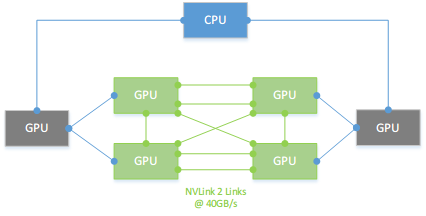
eg3: 8*P100 Cube Mesh Topo
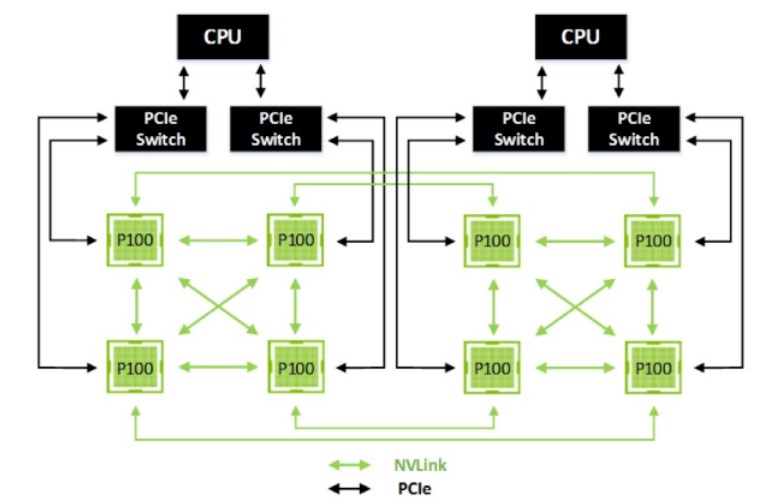
eg4: 8*V100 Cube Mesh Topo
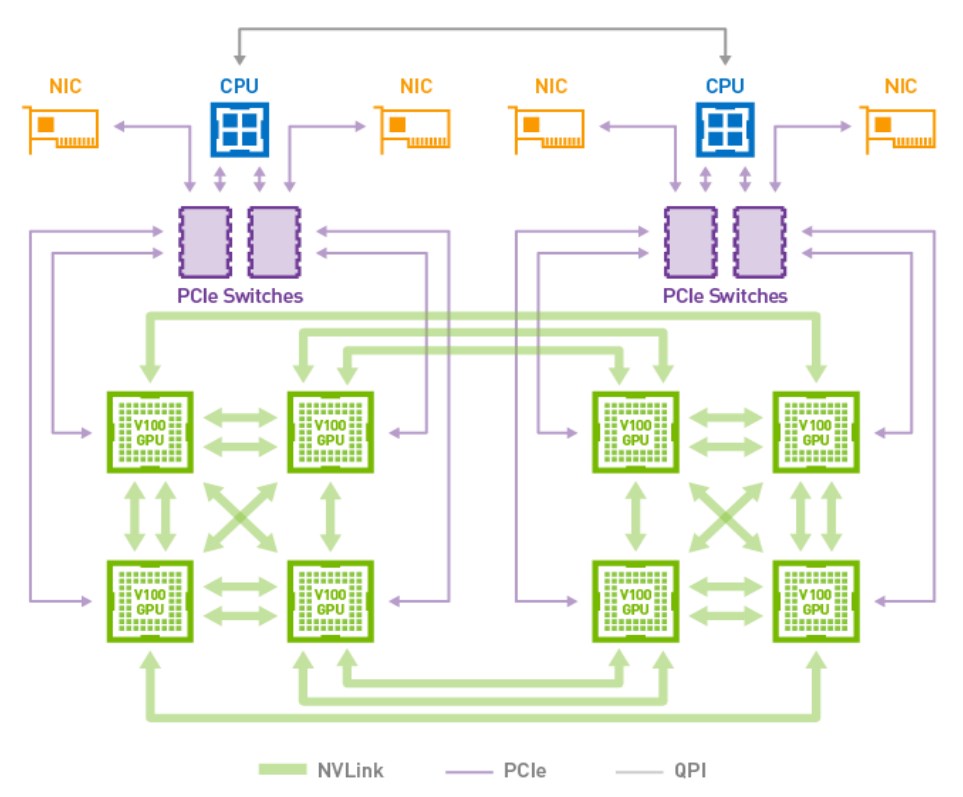
NVSwitch
NVSwitch是交换芯片
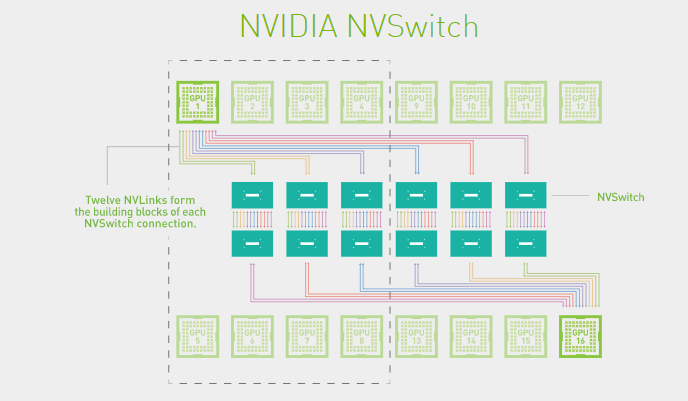
6对(12个Switch)使用在1个DGX-2的Server中支持16个P100 GPU
从GPU的角度看:8对GPU之间的带宽都是300GB/s,那么合计的带宽就是300GB/s*8=2.4TB/s
从Switch的角度看:一个Switch是8个Link,6个Switch就是48Link,单向进入的速度也可以这样计算48Link*25GB/s=1.2TB/s
Switch存在的作用是避免GPU和GPU之间的通信会存在多跳;
关于NVSwitch能找到的资料只有hp30上的胶片,可以看到switch上其实有18个NVLink2.0的Port,理论的吞吐是18*50GB/s=900GB/s

可以猜测NVSwitch2.0可能实现了36个NVLink3.0的Port,理论的吞吐是1800GB/s,但是实际上使用了32个,吞吐是1600GB/s;
EX01: 12个NVSwitch 1.0连接16个V100实现0跳互联:
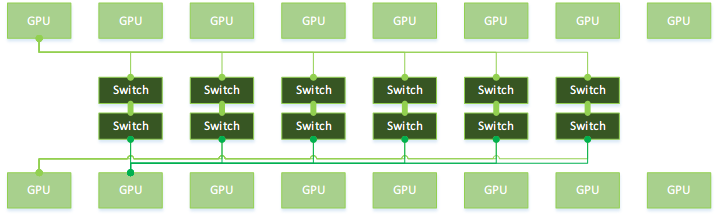
参考Wikichip的透视可能更加清晰:
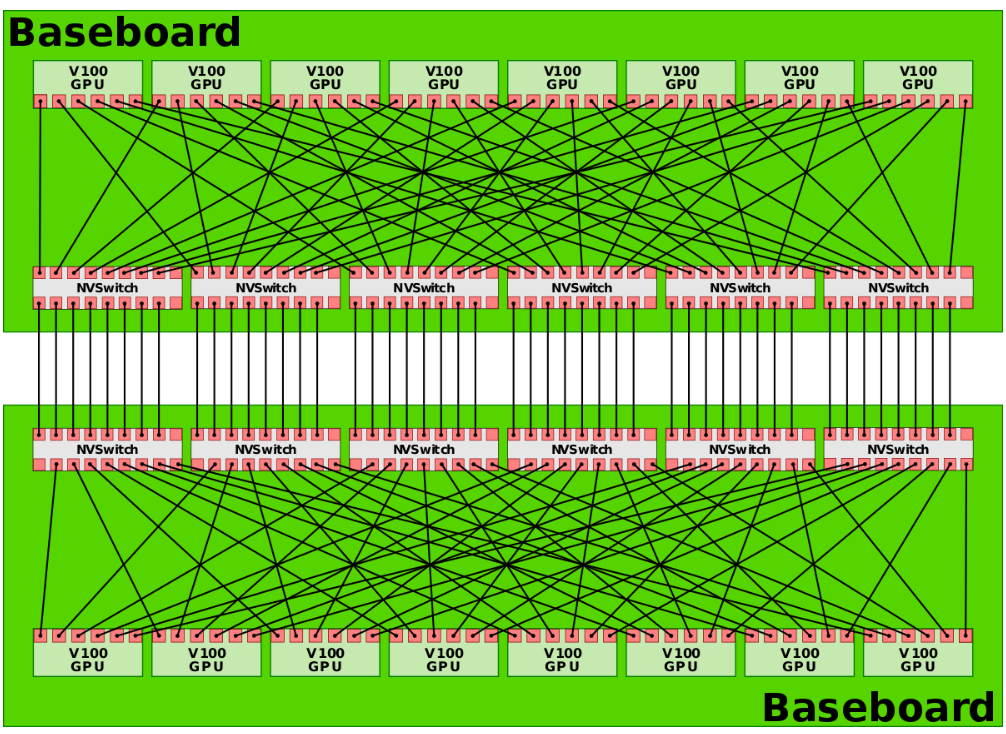
EX02: 12个NVSwitch 2.0连接16个A100实现0跳互联:
Change List
V0.1 2019年11月9日 NVLink1.0/2.0 NVSwitch1.0
V0.2 2020年5月23日 添加NVLink3.0 NVSwitch2.0
参考文献:
万事走心 精益求美

 浙公网安备 33010602011771号
浙公网安备 33010602011771号