
P3项目练习题代码分析
for (event, element) in iterparse(xml, events = ['start'])
for (_, element) in iterparse(xml, events = ['start'])
for _, element in iterparse(xml, events = ['start'])
for _,element in iterparse(xml, events = ('start',)
#四种等效的代码 在for循环中同时使用两个变量 iterparse() 遍历 start选项表示 首先访问外层
end选项表示首先访问内层
正则表达式的使用规则:
'\d' 可以匹配数字
‘\w’可以匹配数字或字母
'\s' 可以匹配空格
. 可以匹配任意字符
* 可以表示任意个字符
+ 表示至少一个字符
? 表示0 或 1 个字符
{n} 表示n个字符
{n-m} 表示 n - m个字符
[ ] 可以表示范围 比如[ 0-9a-zA-Z]可以匹配一个数字、字母或下划线(唯一一个)
^ 表示行的开头
$ 表示行的结尾
r 前缀可以代替使用转义字符
a|b 表示a或b
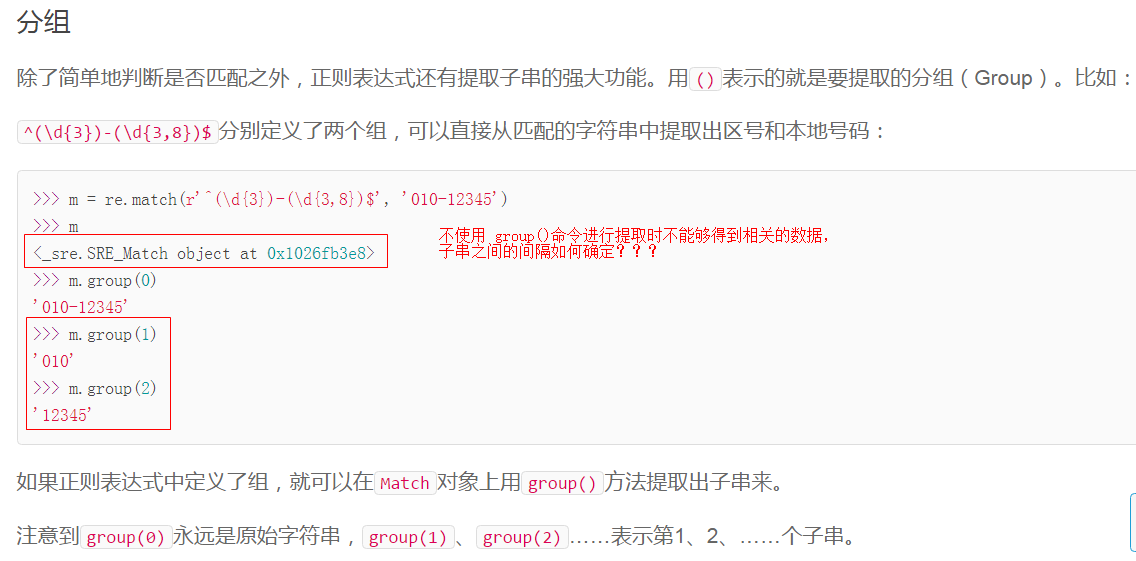

search 与 match 方法的区别
iterparse() 遍历一个XML文件 ,
iter()
findall() finds only elements with a tag which are direct children of the current element
find() first child with a particular tag
Element.text access the element's text content
Element.get() access the element's attributes
贪婪匹配:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号