# 特征选择的原因:部分特征的相关度高,容易消化计算性能,部分特征对预测结果会产生噪声
# filter(过滤式):variancethreshold,即从方差大小考虑
# embedded(嵌入式):正则化、决策树,
# wrapper(包裹式):
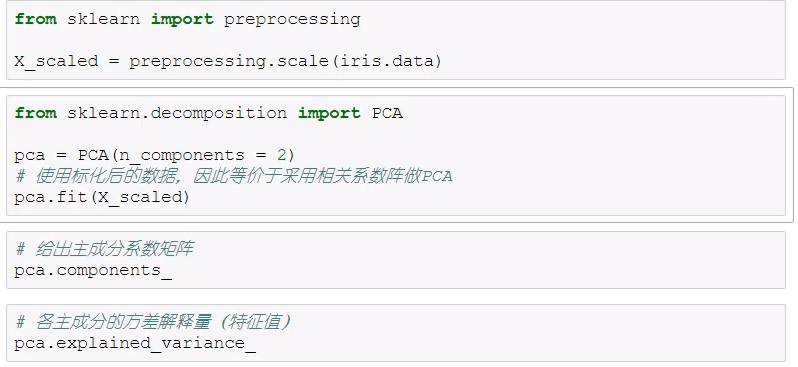
# 主成分分析:PCA本质是一种分析、简化数据集的技术,目的是将数据维度压缩,以损失少量信息为代价,尽可能降低源数据的维度,适合维度达到上百的时候
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
from sklearn.feature_selection import VarianceThreshold
def var():
'''过滤方差,进行降维'''
# threshold指定要过滤的方差,小于等于即过滤该特征
var = VarianceThreshold(threshold=0.0)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
if __name__ == "__main__":
var()
from sklearn.decomposition import PCA
def pca():
'''主成分分析进行降维'''
# n_components等于小数时,表示保留百分之几的信息(一般经验是0.9-1之间),填整数表示保留多少个特征
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2, 8, 4, 5,], [6, 3 ,0, 8], [5, 4, 9, 1]])
print(data)
if __name__ == "__main__":
pca()


















 浙公网安备 33010602011771号
浙公网安备 33010602011771号