

Python基础
第一章:初识Python
1.三双引号“““”””可以包含换行符\n,和制表符\t,以及其他特殊字符。
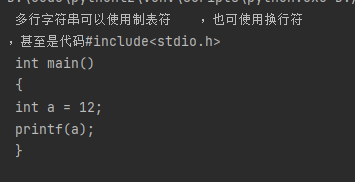
para_str=""" 多行字符串可以使用制表符\t,也可使用换行符\n,甚至是代码#include<stdio.h>
int main()
{
int a = 12;
printf(a);
}"""
print(para_str)
输出如下:
2. 字符串:有n个字符的字符串,从左到右编号为0,1,2,...,n-1;从右到左编号为-1,-2,...,-n。
字符串字符不可修改
用in,not in判断子串
a = "Hello"
b = "Python"
print('el' in a)
print('th' not in b)
输出如下:

3.字符串和数的转换
int(x):把字符串转换成整数
float(x):转换成小数
str(x):把x转换成字符串
eval(x):把字符串x看作一个表达式,求其值

s = input()输入的均为字符串
4.初识列表
输入两个整数求和,默认空格、制表符、换行符
s = input()
numbers = s.split(',')
print(int(numbers[0])+int(numbers[1]))
第二章:基本运算
1.算术运算中 / 结果是小数
// 求商,结果是整数
**求幂
2.逻辑运算符
and or not
print(2.0 and True)
3.条件分支语句
if int(input()) == 5:
print("a",end="")
print("b")
4.字符串切片
若S是一个字符串,则S[x:y]是S的下标x到下标y的左边那个字符构成的子串
print("12345"[0:-1])
输出:1234
5.输出格式控制
%s字符串、%d整数、%f小数、%.nf保留n位小数,注意四舍六入
格式控制符只能出现在字符串中
h = 1.768
print("My name is %s,I am %.2fm tall" % ("tom",h))
第三章 循环语句
1.for
for <variable> in <sequence>:
<statements 1>
<statements 2>
sequence可以是range(),也可以是是字符串、列表、元组、字典、集合
for i in range(0,10,3):
print(i)
输出:
0
3
6
9
for i in range(26):
print(chr(ord('a')+i),end='')
连续输出26个字符
2.while
第四章 函数
这是判素函数
def IsPrime(n):
if n<= 1 or n % 2==0 and n != 2:
return False
elif n == 2:
return True
else:
for i in range(3,n,2):
if n % i == 0:
return False
if i * i > n:
break
return True
for i in range(100):
if(IsPrime(i)):
print(i,end = " ")
递归=概念的定义使用到了这个概念本身
台阶问题:
def ways(n):
if n == 1:
return 1
elif n == 2:
return 2
else:
return ways(n-1)+ways(n-2)
print(ways(4))
汉诺塔:
def Hanoi(n,src,mid,dest):
#将src座上的n个盘子,以mid为中转,移动到dest座
if n == 1:#只需移动一个盘子
# 直接将盘子从src移动到dest即可
print(src + "->" + dest)
return
Hanoi(n-1,src,dest,mid) #先将n-1个盘子从src移到mid
print(src + "->" + dest)#再将一个盘子从src移到dest
Hanoi(n-1,mid,src,dest) #最后将n-1个盘子从mid移到dest
n = int(input())
Hanoi(n,'A','B','C')
第五章 字符串和元组
组合数据类型:字符串 str、元组 tuple、列表 list、字典 dict、集合 set
isinstance(x,y)函数查询数据x是否是类型y
print(len({'tom':2,'jack':3}))
Python中的变量都是指针
a is b 为True 说明a和b指向同一个地方
a == b 说明指向地方放的值相同
a = b 将a和b指向同一个地方
转义字符:
print("Hello\nworld\tok\"1\\2")
输出:
Hello
world ok"1\2
规定'\'不转义的字符串
print(r'ab\ncd') 输出: ab\ncd
# 字符串切片
# a[x:y]表示字符串a里从下标x到下标y那一部分的子串
a = 'ABCD'
print(a[1:2])
print(a[0:-1])
print(a[2:])
print(a[:3])
# a[x:y:z]表示,从a[x]到a[y],每z个字符取一个,最后拼起来
print('abcde'[::-1])
#适用与元组和列表
'''
字符串的split函数详解
s.split(x)
用字符x做分隔符分割字符串s,得到分割后的列表
两个分隔符之间会被分割出一个空串
'''
a = '12..34.5346...a'
print(a.split('.'))
'''
用多个分割串进行分割
'''
import re
a = 'Beautiful, is; better**than\nugly'
print(re.split(';| |,|\*\*|\n',a))
字符串的函数
# 求子串出现次数
s = 'AAA'
print(s.count('AA'))
upper、lower转大小写
s = '1234abc567abc12'
print(s.find('ab')) #'ab'第一次出现的下标
print(s.rfind('ab')) #rfind从尾巴开始找
try:
s.index('afb') #找不到'afb',因此产生异常
except Exception as e:
print(e)
s = '1234abc567abc12'
print(s.index('ab',5)) #find函数还可以指定查找位置
replace替换
s = "1234abd567abc12"
b = s.replace('abc','ABC')
print(b)

元组
一个元组由数个逗号分隔的值组成,前后可加括号
元组不能修改、不可增删、不可对元素赋值、不可修改元素顺序
t = 1234,54321,'hello' print(t[0]) print(t) u = t,1 print(u) print(u[0][1]) t[0][0]=8888
第六章 列表
列表可以增删元素、元素可以修改、元素可以是任何类型
对列表来说,a+=b和a=a+b不同
列表的每个元素都是指针
列表的切片返回新的列表
列表的排序:
# a.sort()可以对列表a从小到大排序 # sorted(a)返回a经过从小到大排序后的新列表,a不变 a = [5,7,6,3,4,1,2] a.sort() print(a) a = [5,7,6,3,4,1,2] b = sorted(a) print(a,'\n',b) a.sort(reverse=True) print(a)
#列表相关函数
'''
append() 添加元素x到尾部
exten() 添加列表x中的元素到尾部
insert(i,x) 将元素x插入到下标i处
remove(x) 删除元素x
reverse() 颠倒整个列表
index() 查找元素x,找到则返回第一次出现的下标,找不到则引发异常
map(function,sequence),可用于将一个序列(列表、元组、集合...)映射到另一个序列
返回一个延时求值对象,可以转换成list、tuple、set...
filter(function,sequence),抽取序列中令function(x)为True的元素x
返回一个延时求值对象,可以转换成list、tuple、set...
'''
'''
def f(x):
print(x,end="")
return x*x
a = map(f,[1,2,3])
print(tuple(a))
'''
def f(x):
return x % 2 == 0
lst = tuple(filter(f,[1,2,3,4,5]))
print(lst)
列表的拷贝和转换:
a = [1,2,3,4] b = a[:] print(b) #不能深拷贝 #进行深拷贝 import copy a = [1,[2]] b = copy.deepcopy(a) b.append(4) print(b) a[1].append(3) print(a) print(b)
元组、列表和字符串互转:
print(list("hello"))
print("".join(['a','44','c']))
print(tuple("hello"))
print("".join(('a','44','c')))
第七章 字典和集合

scope = {}
scope['a'] = 3
scope['b'] = 4
print(scope)
print('b' in scope)
scope['k'] = scope.get('k',0) + 1
print(scope['k'])
scope['k'] = scope.get('k',0) + 1
print(scope['k'])
字典的构造:
items = [('name','Gumby'),('age',42)]
d = dict(items)
print(d)
d = dict(name='Gumby',age=42,height=1.76)
print(d)
字典相关函数:
'''
clear() 清空字典
keys() 取字典的键的序列
items() 取字典的元素的序列,可用于遍历
values() 取字典的值的序列
pop() 删除键为x的元素,如果不存在,产生异常
copy() 浅拷贝
上述序列,不是list、tuple或set
'''
d = {'name':'Gumby','age':42,'GPA':3.5}
if 'age' in d.keys():
print(d['age'])
for x in d.items():
print(x,end=',')
集合:

print(set([]))
a = {1,2,2,"ok",(1,3)} #集合的元素顺序不定
print(a)
'''
add(x) 添加元素x,如果已经存在,则不添加
clear() 清空集合
copy() 返回自身的浅拷贝
remove(x) 删除x,若无,则异常
update(x) 将序列x中的元素加入集合
| & - 并、交、差
a^b 对称差 (a|b)-(a&b)
a <= b a是否是b的子集
a < b a是否是b的真子集
'''
第八章 文件读写、文件夹操作和数据库
'''
open函数打开文件,将返回值放入一个变量,例如f
用f.write()函数写入文件
用f.readlines()函数读取全部文件内容
用f.readline()函数读取文件一行
用f.close()函数关闭文件
用f.read()读取文件全部内容,返回一个字符串
'''
# 创建文件并写入内容
a = open("D:\\code\\pythonl2\\t.txt",'w')
# 用'w'写文件,若文件本来就存在就会被覆盖
a.write('good\n')
a.write('好啊\n')
a.close()
readlines读:
f = open('D:\\code\\pythonl2\\t.txt','r')
lines = f.readlines() #每一行都带结尾的换行符 "\n"
f.close()
for x in lines:
print(x,end="")
readline读:
try:
infile = open('D:\\code\\pythonl2\\t.txt', 'r')
while True:
data1 = infile.readline() # data1带结尾的换行符"\n",空行也有换行符
if data1 == "": # 此条件满足代表文件结束
break
data1 = data1.strip() # 去掉两头空格,包括结尾的"\n"
print(data1)
infile.close()
except Exception as e:
print(e)
文件路径:
#获取当前文件夹
import os
print(os.getcwd())
#改变当前文件夹
os.chdir("D:/program")
print(os.getcwd())
文件夹操作函数:
''' os.chdir(x) 将当前的文件夹设置成x os.getcwd() 求程序的当前文件夹 os.listdir(x) 返回一个列表,里面是文件夹x中的所有文件和子文件夹的名字 os.mkdir(x) 创建文件夹 os.path.getsize(x) 获取文件夹x的大小(字节) os.path.isfile(x) 判断x是不是文件 os.remove(x) 删除文件x os.rmdir(x) 删除空文件夹x os.rename(x,y) 将文件或文件夹x改名为y,还可以移动文件或文件夹 shutil.copyfile(x,y) 拷贝文件x到y,若y本来就存在,会被覆盖 '''
命令行参数:
统计单个文件单词频率:
import sys
import re
def countFile(filename,words):
#对filename文件进行词频分析,分析结果记在词典wrods里
try:
f = open(filename,"r",encoding="gbk")
except Exception as e:
print(e)
return 0
txt = f.read()
f.close()
splitChars = set([])
for c in txt:
if not (c >= 'a' and c <='z' or c >= 'A' and c<= 'Z'):
splitChars.add(c)
splitsStr = ""
for c in splitChars:
if c in ['.','?','!','"',"'",'(',')','|','*','$','\\','[',']','^','{','}']:
splitsStr += "\\"+c+"|"
else:
splitsStr += c +"|"
splitsStr += " "
lst = re.split(splitsStr,txt)
for x in lst:
if x == "":
continue
lx = x.lower()
if lx in words:
words[lx] += 1
else:
words[lx] = 1
return 1
result = {}
if countFile(sys.argv[1],result) == 0:
exit()
lst = list(result.items())
lst.sort()
f = open(sys.argv[2],"w")
for x in lst:
f.write("%s\t%d\n"%(x[0],x[1]))
f.close()
统计多个文件累计单词频率:
import sys
import re
import os
def countFile(filename,words):
#对filename文件进行词频分析,分析结果记在词典wrods里
try:
f = open(filename,"r",encoding="gbk")
except Exception as e:
print(e)
return 0
txt = f.read()
f.close()
splitChars = set([])
for c in txt:
if not (c >= 'a' and c <='z' or c >= 'A' and c<= 'Z'):
splitChars.add(c)
splitsStr = ""
for c in splitChars:
if c in ['.','?','!','"',"'",'(',')','|','*','$','\\','[',']','^','{','}']:
splitsStr += "\\"+c+"|"
else:
splitsStr += c +"|"
splitsStr += " "
lst = re.split(splitsStr,txt)
for x in lst:
if x == "":
continue
lx = x.lower()
if lx in words:
words[lx] += 1
else:
words[lx] = 1
return 1
result = {}
lst = os.listdir()
for x in lst:
if os.path.isfile(x):
if x.lower().endswith(".txt"):
countFile(x,result)
lst = list(result.items())
lst.sort(key= lambda x:(-x[1],x[0]))
f = open(sys.argv[1],"w")
for x in lst:
f.write("%s\t%d\n" % (x[0],x[1]))
f.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号