
K8S 搭建 Prometheus (三) 安装和配置 Alertmanager-发送报警到 qq 邮箱
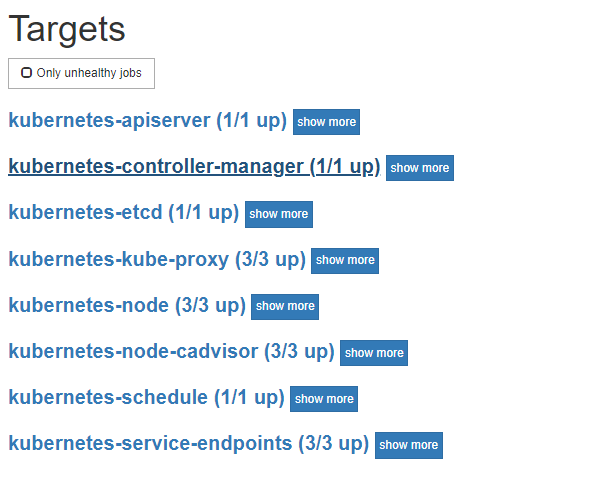
kubernetes-controller-manager, kubernetes-schedule, kubernetes-kube-proxy 监听端口
vi /etc/kubernetes/manifests/kube-scheduler.yaml
# 修改如下内容:
把 --bind-address=127.0.0.1 变成 --bind-address=192.168.1.111
把两个 httpGet: 字段下的 hosts 由 127.0.0.1 变成 192.168.1.111
把 —port=0 删除
# 注意:192.168.40.130是k8s的master1节点ip
vi /etc/kubernetes/manifests/kube-controller-manager.yaml
把 --bind-address=127.0.0.1 变成 --bind-address=192.168.1.111
把两个 httpGet: 字段下的 hosts 由 127.0.0.1 变成 192.168.1.111
把 —port=0 删除
# 修改之后在k8s各个节点执行
systemctl restart kubelet
# 因为 kube-proxy 默认端口 10249 是监听在 127.0.0.1 上的,需要改成监听到物理节点上,按如下方法修改,线上建议在安装k8s的时候就做修改,这样风险小一些:
kubectl edit configmap kube-proxy -n kube-system
# 把 metricsBindAddress 这段修改成 metricsBindAddress: 0.0.0.0:10249, 然后重新启动 kube-proxy 这个 pod
安装和配置 Alertmanager-发送报警到 qq 邮箱
# 在 master 上操作
mkdir -p /data/yaml/monitor-sa/alertmanager
# 生成一个 etcd-certs,这个在部署 prometheus 需要
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
cat alertmanager-cm.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: alertmanager
namespace: monitor-sa
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.126.com:25'
smtp_from: 'klvchen@126.com'
smtp_auth_username: 'klvchen'
smtp_auth_password: 'IFZAIDNDGJSDLAEO'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: '1158xxxxx@qq.com'
send_resolved: true
kubectl apply -f alertmanager-cm.yaml
cat alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor-sa
labels:
app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: k8s-node1
serviceAccountName: monitor
containers:
- name: alertmanager
image: harbor.junengcloud.com/monitor/alertmanager:v0.14.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
protocol: TCP
name: alertmanager
volumeMounts:
- name: alertmanager-config
mountPath: /etc/alertmanager
- name: alertmanager-storage
mountPath: /alertmanager
- name: localtime
mountPath: /etc/localtime
volumes:
- name: alertmanager-config
configMap:
name: alertmanager
- name: alertmanager-storage
hostPath:
path: /data/alertmanager-data
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
kubectl apply -f alertmanager-deploy.yaml
cat alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
labels:
name: alertmanager
kubernetes.io/cluster-service: 'true'
name: alertmanager
namespace: monitor-sa
spec:
ports:
- name: alertmanager
nodePort: 30066
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: alertmanager
sessionAffinity: None
type: NodePort
kubectl apply -f alertmanager-svc.yaml
# 重新配置 prometheus-server
cd /data/yaml/monitor-sa/prometheus
# 根据实际情况更改 ip
cat prometheus-alertmanager-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
rule_files:
- /etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager.monitor-sa:9093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- job_name: 'kubernetes-schedule'
scrape_interval: 5s
static_configs:
- targets: ['172.16.16.100:10251']
- job_name: 'kubernetes-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['172.16.16.100:10252']
- job_name: 'kubernetes-kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['172.16.16.100:10249','172.16.16.101:10249','172.16.16.102:10249']
- job_name: 'kubernetes-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key
scrape_interval: 5s
static_configs:
- targets: ['172.16.16.100:2379']
rules.yml: |
groups:
- name: example
rules:
- alert: kube-proxy的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: kube-proxy的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: scheduler的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: scheduler的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: controller-manager的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: controller-manager的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: apiserver的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: apiserver的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: etcd的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"
- alert: etcd的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"
- alert: kube-state-metrics的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: kube-state-metrics的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: coredns的cpu使用率大于80%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"
value: "{{ $value }}%"
threshold: "80%"
- alert: coredns的cpu使用率大于90%
expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"
value: "{{ $value }}%"
threshold: "90%"
- alert: kube-proxy打开句柄数>600
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kube-proxy打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>600
expr: process_open_fds{job=~"kubernetes-schedule"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-schedule打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-schedule"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>600
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-controller-manager打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>600
expr: process_open_fds{job=~"kubernetes-apiserver"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-apiserver打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>600
expr: process_open_fds{job=~"kubernetes-etcd"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"
value: "{{ $value }}"
- alert: kubernetes-etcd打开句柄数>1000
expr: process_open_fds{job=~"kubernetes-etcd"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 600
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"
value: "{{ $value }}"
- alert: coredns
expr: process_open_fds{k8s_app=~"kube-dns"} > 1000
for: 2s
labels:
severity: critical
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"
value: "{{ $value }}"
- alert: kube-proxy
expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: scheduler
expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-controller-manager
expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-apiserver
expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kubernetes-etcd
expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: kube-dns
expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000
for: 2s
labels:
severity: warnning
annotations:
description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"
value: "{{ $value }}"
- alert: HttpRequestsAvg
expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"
value: "{{ $value }}"
threshold: "1000"
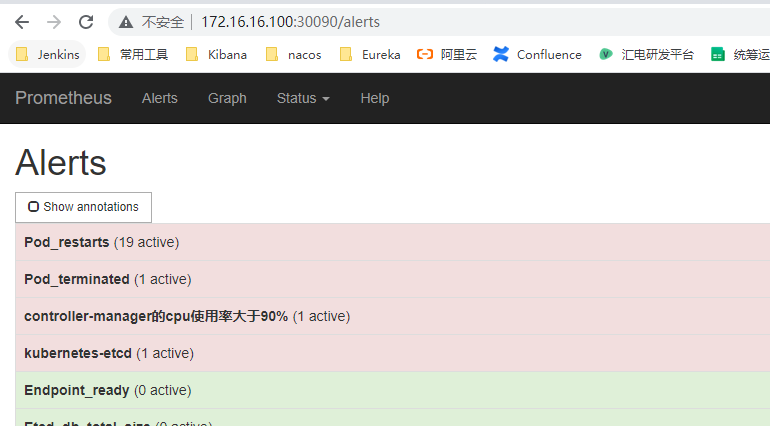
- alert: Pod_restarts
expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0
for: 2s
labels:
severity: warnning
annotations:
description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"
value: "{{ $value }}"
threshold: "0"
- alert: Pod_waiting
expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"
value: "{{ $value }}"
threshold: "1"
- alert: Pod_terminated
expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"
value: "{{ $value }}"
threshold: "1"
- alert: Etcd_leader
expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_leader_changes
expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_failed
expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"
value: "{{ $value }}"
threshold: "0"
- alert: Etcd_db_total_size
expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000
for: 2s
labels:
team: admin
annotations:
description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"
value: "{{ $value }}"
threshold: "10G"
- alert: Endpoint_ready
expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1
for: 2s
labels:
team: admin
annotations:
description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"
value: "{{ $value }}"
threshold: "1"
- name: 物理节点状态-监控告警
rules:
- alert: 物理节点cpu使用率
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90
for: 2s
labels:
severity: ccritical
annotations:
summary: "{{ $labels.instance }}cpu使用率过高"
description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: 物理节点内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}内存使用率过高"
description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"
- alert: InstanceDown
expr: up == 0
for: 2s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}: 服务器宕机"
description: "{{ $labels.instance }}: 服务器延时超过2分钟"
- alert: 物理节点磁盘的IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"
- alert: 入网流量带宽
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流入网络带宽过高!"
description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: 出网流量带宽
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 流出网络带宽过高!"
description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: 磁盘容量
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 2s
labels:
severity: critical
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"
description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
kubectl delete -f prometheus-cfg.yaml
kubectl apply -f prometheus-alertmanager-cfg.yaml
cat prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
component: server
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
nodeName: k8s-node1
serviceAccountName: monitor
containers:
- name: prometheus
image: harbor.junengcloud.com/monitor/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- mountPath: /prometheus/
name: prometheus-storage-volume
- name: k8s-certs
mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/
- name: localtime
mountPath: /etc/localtime
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-storage-volume
hostPath:
path: /data/prometheus-data
type: Directory
- name: k8s-certs
secret:
secretName: etcd-certs
- name: localtime
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
# 通过 kubectl apply 更新 yaml 文件
kubectl apply -f prometheus-alertmanager-deploy.yaml


 浙公网安备 33010602011771号
浙公网安备 33010602011771号