
如何缓解DDoS 攻击,网络延迟,NAT
DDoS 简介
DDoS 的前身是 DoS(Denail of Service),即拒绝服务攻击,指利用大量的合理请求,来占用过多的目标资源,从而使目标服务无法响应正常请求。
DDoS(Distributed Denial of Service) 则是在 DoS 的基础上,采用了分布式架构,利用多台主机同时攻击目标主机。这样,即使目标服务部署了网络防御设备,面对大量网络请求时,还是无力应对。
从攻击的原理上来看,DDoS 可以分为下面几种类型。
- 第一种,耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。
- 第二种,耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正常的网络连接。
- 第三种,消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响应。
比如,构造大量不同的域名来攻击 DNS 服务器,就会导致 DNS 服务器不停执行迭代查询,并更新缓存。这会极大地消耗 DNS 服务器的资源,使 DNS 的响应变慢。
运行 hping3 命令,来模拟 DoS 攻击:
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u10表示每隔10微秒发送一个网络帧
# --rand-source 选项,来随机化源 IP。
$ hping3 -S -p 80 -i u10 192.168.0.30
查看 SYN_REVEIVED 状态
# -n表示不解析名字,-p表示显示连接所属进程
$ netstat -n -p | grep SYN_REC | wc -l
用以下两种方法,来限制 syn 包的速率:
# 限制syn并发数为每秒1次
$ iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
# 限制单个IP在60秒新建立的连接数为10
$ iptables -I INPUT -p tcp --dport 80 --syn -m recent --name SYN_FLOOD --update --seconds 60 --hitcount 10 -j REJECT
SYN Flood 会导致 SYN_RECV 状态的连接急剧增大。半开状态的连接数是有限制的,执行下面的命令,你就可以看到,默认的半连接容量只有 256:
$ sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 256
换句话说, SYN 包数再稍微增大一些,就不能 SSH 登录机器了。 所以,你还应该增大半连接的容量,比如,你可以用下面的命令,将其增大为 1024:
$ sysctl -w net.ipv4.tcp_max_syn_backlog=1024
net.ipv4.tcp_max_syn_backlog = 1024
另外,连接每个 SYN_RECV 时,如果失败的话,内核还会自动重试,并且默认的重试次数是 5 次。你可以执行下面的命令,将其减小为 1 次:
$ sysctl -w net.ipv4.tcp_synack_retries=1
net.ipv4.tcp_synack_retries = 1
除此之外,TCP SYN Cookies 也是一种专门防御 SYN Flood 攻击的方法。SYN Cookies 基于连接信息(包括源地址、源端口、目的地址、目的端口等)以及一个加密种子(如系统启动时间),计算出一个哈希值(SHA1),这个哈希值称为 cookie。
然后,这个 cookie 就被用作序列号,来应答 SYN+ACK 包,并释放连接状态。当客户端发送完三次握手的最后一次 ACK 后,服务器就会再次计算这个哈希值,确认是上次返回的 SYN+ACK 的返回包,才会进入 TCP 的连接状态。
因而,开启 SYN Cookies 后,就不需要维护半开连接状态了,进而也就没有了半连接数的限制。
注意,开启 TCP syncookies 后,内核选项 net.ipv4.tcp_max_syn_backlog 也就无效了。你可以通过下面的命令,开启 TCP SYN Cookies:
$ sysctl -w net.ipv4.tcp_syncookies=1
net.ipv4.tcp_syncookies = 1
注意,上述 sysctl 命令修改的配置都是临时的,重启后这些配置就会丢失。所以,为了保证配置持久化,你还应该把这些配置,写入 /etc/sysctl.conf 文件中。比如:
$ cat /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_max_syn_backlog = 1024
需要执行 sysctl -p 命令后,才会动态生效
DDoS 到底该怎么防御
实际上,当 DDoS 报文到达服务器后,Linux 提供的机制只能缓解,而无法彻底解决。即使像是 SYN Flood 这样的小包攻击,其巨大的 PPS ,也会导致 Linux 内核消耗大量资源,进而导致其他网络报文的处理缓慢。
虽然你可以调整内核参数,缓解 DDoS 带来的性能问题,却也会像案例这样,无法彻底解决它。
在之前的 C10K、C100K 文章中,我也提到过,Linux 内核中冗长的协议栈,在 PPS 很大时,就是一个巨大的负担。对 DDoS 攻击来说,也是一样的道理。
所以,当时提到的 C10M 的方法,用到这里同样适合。比如,你可以基于 XDP 或者 DPDK,构建 DDoS 方案,在内核网络协议栈前,或者跳过内核协议栈,来识别并丢弃 DDoS 报文,避免 DDoS 对系统其他资源的消耗。
不过,对于流量型的 DDoS 来说,当服务器的带宽被耗尽后,在服务器内部处理就无能为力了。这时,只能在服务器外部的网络设备中,设法识别并阻断流量(当然前提是网络设备要能扛住流量攻击)。比如,购置专业的入侵检测和防御设备,配置流量清洗设备阻断恶意流量等。
DDoS 并不一定是因为大流量或者大 PPS,有时候,慢速的请求也会带来巨大的性能下降(这种情况称为慢速 DDoS)。比如,很多针对应用程序的攻击,都会伪装成正常用户来请求资源。这种情况下,请求流量可能本身并不大,但响应流量却可能很大,并且应用程序内部也很可能要耗费大量资源处理。
这时,就需要应用程序考虑识别,并尽早拒绝掉这些恶意流量,比如合理利用缓存、增加 WAF(Web Application Firewall)、使用 CDN 等等。
网络延迟
通常,我们更常用的是双向的往返通信延迟,比如 ping 测试的结果,就是往返延时 RTT(Round-Trip Time)。
除了网络延迟外,另一个常用的指标是应用程序延迟,它是指,从应用程序接收到请求,再到发回响应,全程所用的时间。通常,应用程序延迟也指的是往返延迟,是网络数据传输时间加上数据处理时间的和。
Nagle 算法,是 TCP 协议中用于减少小包发送数量的一种优化算法,目的是为了提高实际带宽的利用率。
举个例子,当有效负载只有 1 字节时,再加上 TCP 头部和 IP 头部分别占用的 20 字节,整个网络包就是 41 字节,这样实际带宽的利用率只有 2.4%(1/41)。往大了说,如果整个网络带宽都被这种小包占满,那整个网络的有效利用率就太低了。
Nagle 算法正是为了解决这个问题。它通过合并 TCP 小包,提高网络带宽的利用率。Nagle 算法规定,一个 TCP 连接上,最多只能有一个未被确认的未完成分组;在收到这个分组的 ACK 前,不发送其他分组。这些小分组会被组合起来,并在收到 ACK 后,用同一个分组发送出去。
显然,Nagle 算法本身的想法还是挺好的,但是知道 Linux 默认的延迟确认机制后,你应该就不这么想了。因为它们一起使用时,网络延迟会明显。如下图所示:
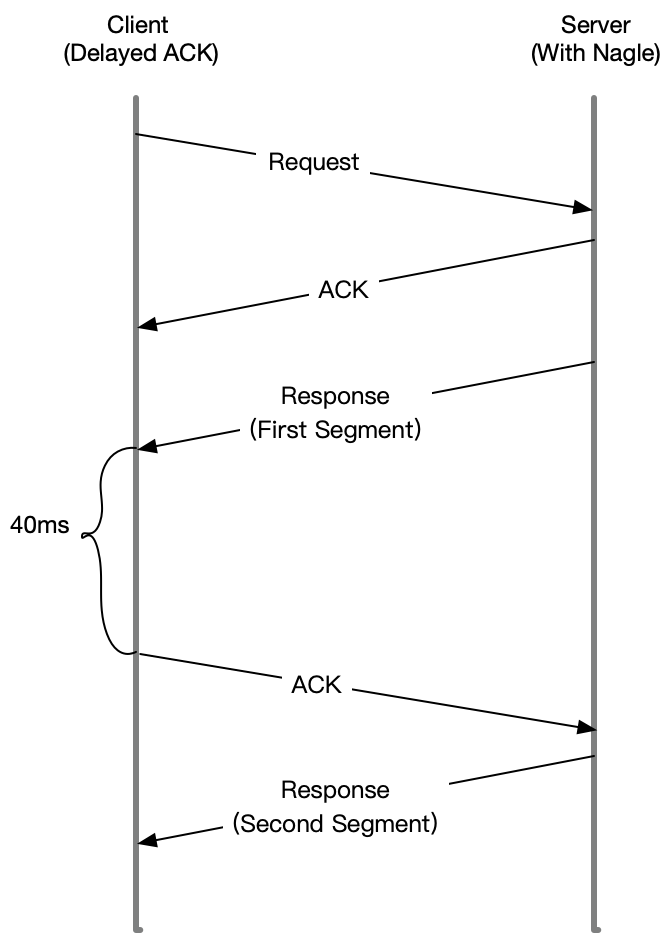
- 当 Sever 发送了第一个分组后,由于 Client 开启了延迟确认,就需要等待 40ms 后才会回复 ACK。
- 同时,由于 Server 端开启了 Nagle,而这时还没收到第一个分组的 ACK,Server 也会在这里一直等着。
- 直到 40ms 超时后,Client 才会回复 ACK,然后,Server 才会继续发送第二个分组。既然可能是 Nagle 的问题,那该怎么知道,案例 Nginx 有没有开启 Nagle 呢?
查询 tcp 的文档,你就会知道,只有设置了 TCP_NODELAY 后,Nagle 算法才会禁用。所以,我们只需要查看 Nginx 的 tcp_nodelay 选项就可以了。
在发现网络延迟增大后,你可以用 traceroute、hping3、tcpdump、Wireshark、strace 等多种工具,来定位网络中的潜在问题。比如,
- 使用 hping3 以及 wrk 等工具,确认单次请求和并发请求情况的网络延迟是否正常。
- 使用 traceroute,确认路由是否正确,并查看路由中每一跳网关的延迟。
- 使用 tcpdump 和 Wireshark,确认网络包的收发是否正常。
- 使用 strace 等,观察应用程序对网络套接字的调用情况是否正常。
NAT
DNAT 的基础是 conntrack,所以我们可以先看看,内核提供了哪些 conntrack 的配置选项。
我们在终端一中,继续执行下面的命令:
$ sysctl -a | grep conntrack
net.netfilter.nf_conntrack_count = 180
net.netfilter.nf_conntrack_max = 1000
net.netfilter.nf_conntrack_buckets = 65536
net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
你可以看到,这里最重要的三个指标:
- net.netfilter.nf_conntrack_count,表示当前连接跟踪数;
- net.netfilter.nf_conntrack_max,表示最大连接跟踪数;
- net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小。
所以,这个输出告诉我们,当前连接跟踪数是 180,最大连接跟踪数是 1000,连接跟踪表的大小,则是 65536。
实际上,内核在工作异常时,会把异常信息记录到日志中。若"连接跟踪表"有问题,内核已经在日志中报出了 “nf_conntrack: table full” 的错误。执行 dmesg 命令,你就可以看到。
那是不是,直接把连接跟踪表调大就可以了呢?调节前,你先得明白,连接跟踪表,实际上是内存中的一个哈希表。如果连接跟踪数过大,也会耗费大量内存。
我们可以估算一下,上述配置的连接跟踪表占用的内存大小:
# 连接跟踪对象大小为376,链表项大小为16
nf_conntrack_max*连接跟踪对象大小+nf_conntrack_buckets*链表项大小
= 1000*376+65536*16 B
= 1.4 MB
将 nf_conntrack_max 改大
sysctl -w net.netfilter.nf_conntrack_max=131072
sysctl -w net.netfilter.nf_conntrack_buckets=65536
用 conntrack 命令行工具,来查看连接跟踪表的内容。比如:
# -L表示列表,-o表示以扩展格式显示
$ conntrack -L -o extended | head
ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1
ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1
查看 TIME_WAIT 的默认的超时时间是 120s
TIME_WAIT 的连接跟踪记录,会在超时后清理,而默认的超时时间是 120s
所以,如果你的连接数非常大,确实也应该考虑,适当减小超时时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号