
java 十 (一) 实战
案例实战:一次线上大促营销活动导致的内存泄漏和Full GC优化
线上故障场景
先简单说一下业务背景:一次我们线上推了一个大促销活动,大致就是类似于在某个特定节日里,突然给所有用户发短信、邮件、APP Push消息,说现在有个特别优惠的活动,如果参与的话肯定可以得到很大的实惠!
这类大促活动一般都会吸引比平时多几倍的用户短时间内突然登录 APP 来参与,所以系统一般在这个时候压力会比平时大好几倍。
但是因为从系统的整体设计角度而言,其实给的一些数据库、缓存和机器的资源都是足够的,所以通常而言不该有什么问题。
但是那次大促活动开始之后,直接导致线上一个系统的 CPU 使用率飙升,而且因为 CPU 使用率太高,导致系统几乎陷入卡死的状态,无法处理任何请求!
在重启系统之后,会好一段时间,但是很快又立马发现机器的CPU使用率飙升,继续导致系统卡死!
这就是那次大促活动开始之后,那个系统在线上的一个真实的情况。
有人可能会问,那么 CPU 使用率是怎么观察到飙升的?怎么收到报警的?
其实这个之前已经说过很多次了,中大型公司都会有 Zabbix、Open-Falcon、Prometheus 之类的监控和告警系统,一旦机器的CPU使用率过高,会直接发送报警给你的短信、邮箱和IM工具(比如钉钉)
所以上面说的大促活动开始之后,某个线上系统的 CPU 使用率飙升,其实就是得到了报警才知道的,然后在监控系统上还可以去观察 CPU 的负载曲线,是一个折线图,可以看到 CPU 负载很高。
初步排查CPU负载过高的原因
这里给大家说一下线上系统的机器 CPU 负载过高的两个常见的场景。
第一个场景,是你自己在系统里创建了大量的线程,这些线程同时并发运行,而且工作负载都很重,过多的线程同时并发运行就会导致你的机器 CPU 负载过高。
第二个场景,就是你的机器上运行的 JVM 在执行频繁的 Full GC,Full GC 是非常耗费 CPU 资源的,他是一个非常重负载的过程
所以一旦你的 JVM 有频繁的 Full GC,带来的一个明显的感觉,一个是系统可能时不时会卡死,因此 Full GC 会带来一定的 “Stop the World” 问题,一个是机器的 CPU 负载很高。
所以一旦知道 CPU 负载过高的两个原因,就很容易进行排查了。
大家完全可以使用排除法来做,首先看一下 JVM Full GC 的频率,通过 jstat 也好,或者是监控平台也好,很容易看到现在 Full GC 的频率。如果 Full GC 频率过高,那么就是 Full GC 引起的 CPU 负载过高。
那么如果 JVM GC 频率很正常呢?那就肯定是你的系统创建了过多线程在并发执行负载很重的任务了!
所以当时我们直接通过监控平台就可以看到,JVM 的 Full GC 频率突然变得极为频繁,几乎是每分钟都有一次 Full GC。
大家都知道,每分钟一次 Full GC,一次至少耗时几百毫秒,这个系统性能绝对很糟糕,而且对机器的 CPU 负载也是很高的!
既然发现了频繁 Full GC 了,那肯定就不用去怀疑是系统自己创建过多线程了!
初步排查频繁Full GC的问题
大家通过之前大量的案例和文章已经初步可以得到结论,如果有频繁Full GC的问题,一般可能性有三个:
- 内存分配不合理,导致对象频繁进入老年代,进而引发频繁的Full GC;
- 存在内存泄漏等问题,就是内存里驻留了大量的对象塞满了老年代,导致稍微有一些对象进入老年代就会引发Full GC;
- 永久代里的类太多,触发了Full GC
当然还有之前案例说过,如果上述三个原因都不存在,但是还是有频繁Full GC,也许就是工程师错误的执行“System.gc()”导致的
但是这个一般很少见,而且之前讲过,JVM参数中可以禁止这种显式触发的GC。
所以一般排查频繁Full GC,核心的利器当然是jstat了,之前我们有大量文章带大家做过jstat分析JVM的实战,这里就不赘述了。
当时我们用jstat分析了一下线上系统的情况,发现并不存在内存分配不合理,对象频繁进入老年代的问题,而且永久代的内存使用也很正常,所以上述三个原因中的两个就被排除掉了。
那么我们来考虑最后一个原因:老年代里是不是驻留了大量的对象给塞满了?
对,当时系统就是这个问题!
我们明显发现老年代驻留了大量的对象,几乎快塞满了,所以年轻代稍微有一些对象进入老年代,很容易就会触发Full GC!而且Full GC之后还不会回收掉老年代里大量的对象,只是回收一小部分而已!
所以很明显老年代里驻留了大量的本不应该存在的对象,才导致频繁触发Full GC的。接下来就是要想办法找到这些对象了
之前我们介绍过jmap+jhat的组合来分析内存里的大对象,今天我们介绍另外一个常用的强有力的工具,MAT。
因为jhat适合快速的去分析一下内存快照,但是功能上不是太强大,所以一般其实常用的比较强大的内存分析工具,就是MAT。
对线上系统导出一份内存快照
既然都发现线上系统的老年代中驻留了过多的对象的问题,那么肯定要知道这些对象是谁!
所以先用 jmap 命令导出一份线上系统的内存快照即可:
jmap -dump:format=b,file=文件名 [服务进程ID]
拿到了内存快照之后,其实就是一份文件,接着就可以用 jhat、MAT 之类的工具来分析内存了。
MAT是如何使用的?
不少人是通过 Eclipse 集成的MAT插件来使用的,但是很多人其实开发是用IntelliJ IDEA的,所以这个时候可以直接下载一个MAT来使用即可
给大家官网的下载地址:
https://www.eclipse.org/mat/downloads.php
在这个地址中,就可以下载MAT的最新版本了。
大家选择自己的笔记本电脑的操作系统对应的版本就可以了,他是支持Windows、Mac、Linux三种操作系统的。
下载好MAT后,在他的安装目录里,可以看到一个文件名字叫做:MemoryAnalyzer.ini
这个文件里的内容类似如下所示:
-startup
../Eclipse/plugins/org.eclipse.equinox.launcher_1.5.0.v20180512-1130.jar
--launcher.library
../Eclipse/plugins/org.eclipse.equinox.launcher.cocoa.macosx.x86_64_1.1.700.v20180518-1200
-vmargs
-Xmx1024m
-Dorg.eclipse.swt.internal.carbon.smallFonts
-XstartOnFirstThread
大家务必要记得,如果dump出来的内存快照很大,比如有几个G,你务必在启动MAT之前,先在这个配置文件里给MAT本身设置一下堆内存大小,比如设置为4个G,或者8个G,他这里默认-Xmx1024m是1G。
接着大家直接启动MAT即可,启动之后看到的界面中有一个选型是:Open a Heap Dump,就是打开一个内存快照的意思,选择他,然后选择本地的一个内存快照文件即可。
基于MAT来进行内存泄漏分析
使用 MAT 打开一个内存快照之后,在 MAT 上有一个工具栏,里面有一个按钮,他的英文是:Leak Suspects,就是内存泄漏的分析。
接着 MAT 会分析你的内存快照,尝试找出来导致内存泄漏的一批对象。
这时明显可以看到他会显示给你一个大的饼图,这里就会提示你说,哪些对象占用内存过大。
这个时候直接会看到某种自己系统创建的对象占用量过大,这种对象的实例多达数十万个,占用了老年代一大半的内存空间。
接着当然是找开发工程师去排查这个系统的代码问题了,为什么会创建那么多的对象,而且始终回收不掉?
这就是典型的内存泄漏!即系统创建了大量的对象占用了内存,其实很多对象是不需要使用的,而且还无法回收掉。
后来找到了一个原因,是在系统里做了一个 JVM 本地的缓存,把很多数据都加载到内存里去缓存起来,然后提供查询服务的时候直接从本地内存走。
但是因为没有限制本地缓存的大小,并且没有使用LRU之类的算法定期淘汰一些缓存里的数据,导致缓存在内存里的对象越来越多,进而造成了内存泄漏。
解决问题很简单,只要使用类似 EHCache 之类的缓存框架就可以了,他会固定最多缓存多少个对象,定期淘汰删除掉一些不怎么访问的缓存,以便于新的数据可以进入缓存中。
案例实战:百万级数据误处理导致的频繁Full GC问题优化
事故场景
有一次一个线上系统进行了一次版本升级,结果升级过后才半小时,突然之间收到运营和客服雪花般的反馈,说这个系统对应的前端页面无法访问了,所有用户全部看到的是一片空白和错误信息。
这个时候通过监控报警平台也收到雪花般的报警,发现线上系统所在机器的CPU负载非常高,持续走高,甚至直接导致机器都宕机了。所以系统对应的前端页面当然是什么都看不到了。
CPU负载高原因分析
上篇文章已经给大家总结过CPU负载高的原因了,这里我们直接说结论,看了一下监控和jstat,发现Full GC非常频繁,基本上两分钟就会执行一次Full GC,而且每次Full GC耗时非常长,在10秒左右!
所以直接入手尝试进行Full GC的原因定位。
Full GC频繁的原因分析
上篇文章也给大家总结过Full GC频繁的几种常见原因了,其实分析Full GC频繁的原因,最好的工具不是监控平台,就是最实用的jstat工具,直接看线上系统运行时候的动态内存变化模型,什么问题都立马出来了。
基于jstat一分析发现了很大的问题,当时这个系统因为主要是用来进行大量数据处理然后提供数据给用户查看的,所以当时可是给JVM的堆分配了20G的内存,其中10G给了年轻代,10G给了老年代,如下图所示:
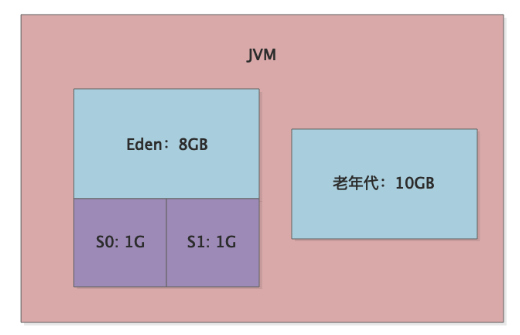
这么大的年轻代,结果大家能猜到jstat看到什么现象吗?Eden区大概1分钟左右就会塞满,然后就会触发一次Young GC,而且Young GC过后有几个GB的对象都是存活的会进入老年代!
如下图所示:
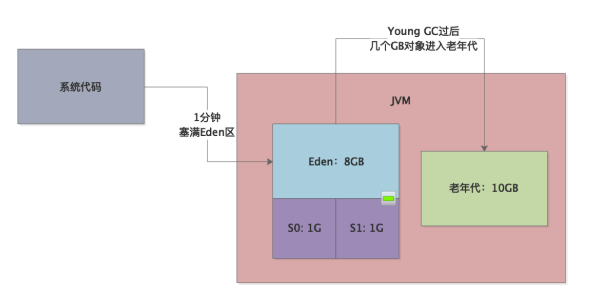
这说明什么?这说明系统代码运行的时候在产生大量的对象,而且处理的极其的慢,经常在1分钟过后Young GC以后还有很多对象在存活,才会导致大量对象进入老年代中!这真是让人非常的无奈。
所以就是因为这个内存运行模型,才导致了平均两分钟就会触发一次Full GC,因为老年代两分钟就塞满了,而且老年代因为内存量很大,所以导致一次Full GC就要10秒的时间!
大家想象一下,系统每隔2分钟就要暂停10秒,对用户是什么感觉!
更有甚者,普通的4核机器根本撑不住这么频繁,而且这么耗时的Full GC,所以这种长时间Full GC直接导致机器的CPU频繁打满,负载过高,也导致了用户经常无法访问系统,页面都是空白的!
以前那套GC优化策略还能奏效吗
那么大家想一下,以前我们给大家说过的那套GC优化策略此时还能奏效吗?
即把年轻代调大一些,给Survivor更多的内存空间,避免对象进入老年代。
明显不行,这个运行内存模型告诉我们,即使你给年轻代更大空间,甚至让每块Survivor区域达到2GB或者3GB,但是一次Young GC过后,还是会因为系统处理过慢,导致几个GB的对象存活下来,你Survivor区域死活都是放不下的!
所以这个时候就不是简单优化一下JVM参数就可以搞定的。
这个系统明显是因为代码层面有一定的改动和升级,直接导致了系统加载过多数据到内存中,而且对过多数据处理的还特别慢,在内存里几个GB的数据甚至要处理一分多钟,才能处理完毕。
这是明显的代码层面的问题了,其实要优化这个事故,就必须得优化代码,而不是简单的JVM参数!
我们需要避免代码层面加载过多的数据到内存里去处理,这是最核心的一个点。
复杂的业务逻辑,自己都看不懂了怎么办
说优化代码,说起来很简单,但是实际做起来呢?
有很多系统的代码都特别的复杂,别说别人看不懂了,自己可能写的代码过了几个月自己都看不懂了!所以直接通过走读代码来分析问题所在是很慢的!
我们必须有一个办法可以立马就定位到系统里到底是什么样的对象太多了占用了过多的内存,这个时候就得使用一个工具了:MAT
这个工具我们上篇文章介绍过,今天给大家深入讲讲他的使用,给出一些界面的截图出来。
准备一段示范用的代码
现在我们来准备一段示范用的代码,在代码里创建一大堆的对象出来,然后我们尝试获取他的dump内存快照,再用MAT来进行分析。
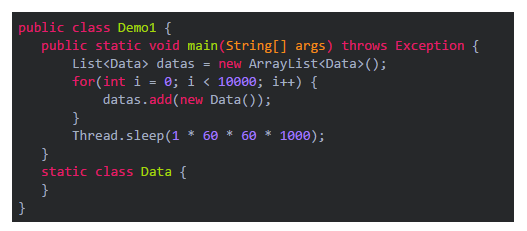
这段代码大家可以看到,非常的简单,就是在代码里创建10000个自定义的对象,然后就陷入一个阻塞状态就可以了,大家可以把这段代码运行起来。
获取jvm进程的dump快照文件
先在本地命令行运行一下jps命令,查看一下启动的jvm进程的PID,如下所示:

明显能看到,我们的Demo1这个类的进程ID为1177
接着执行下面的jmap命令可以导出dump内存快照:
jmap -dump:live,format=b,file=dump.hprof 1177
使用MAT分析内存快照
大家在下一个步骤,务必要注意到,如果是线上导出来的dump内存快照,很多时候可能都是几个GB的
比如我们这里就是8个多GB的内存快照,所以就务必按照上节课所说的,在MAT的MemoryAnalyzer.ini文件里,修改他的启动堆大小为8GB。
接着就是打开MAT软件,如下图所示:
然后选择其中的“Open a Heap Dump”打开自己的那个dump快照即可
接着会看到下图的样子,大家如果跟我一样用的是最新版本的MAT,那么打开dump快照的时候就会提示你,要不要进行内存泄漏的分析,就是Leak Suspects Report,你一般勾选是即可。
接着大家会看到如下的图:
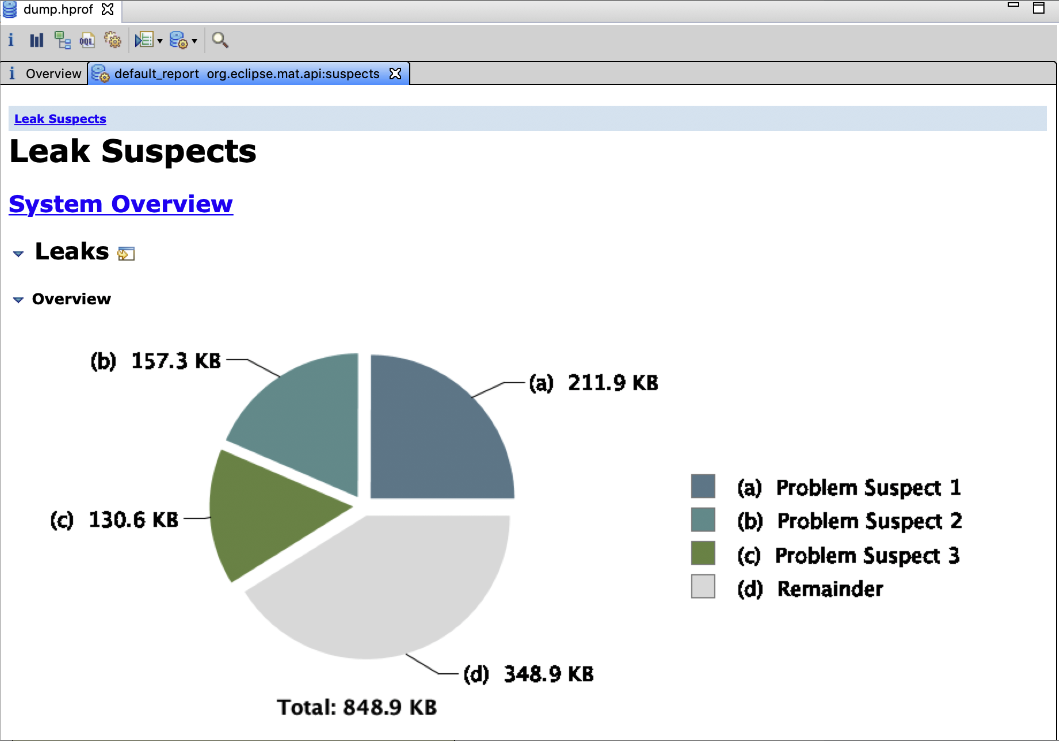

从上面图里可以很清晰的看到了,别人都告诉你了,可能存在的内存泄漏的问题,尤其是第一个问题,“Problem Suspect 1”,他的英文里很清晰的告诉你了,java.lang.Thread main,就是说 main 线程,通过局部变量引用了占据 24.97% 内存的对象。
而且他告诉你那是一个 java.lang.Object[] 数组,这个数组占据了大量的内存。
那么大家肯定想要知道,到底这个数组里是什么东西呢?
大家可以看到上面的 “Problem Suspect 1”框框的里面最后一行是一个超链接的 “Details”,大家点击进去就可以看到详细的说明了。
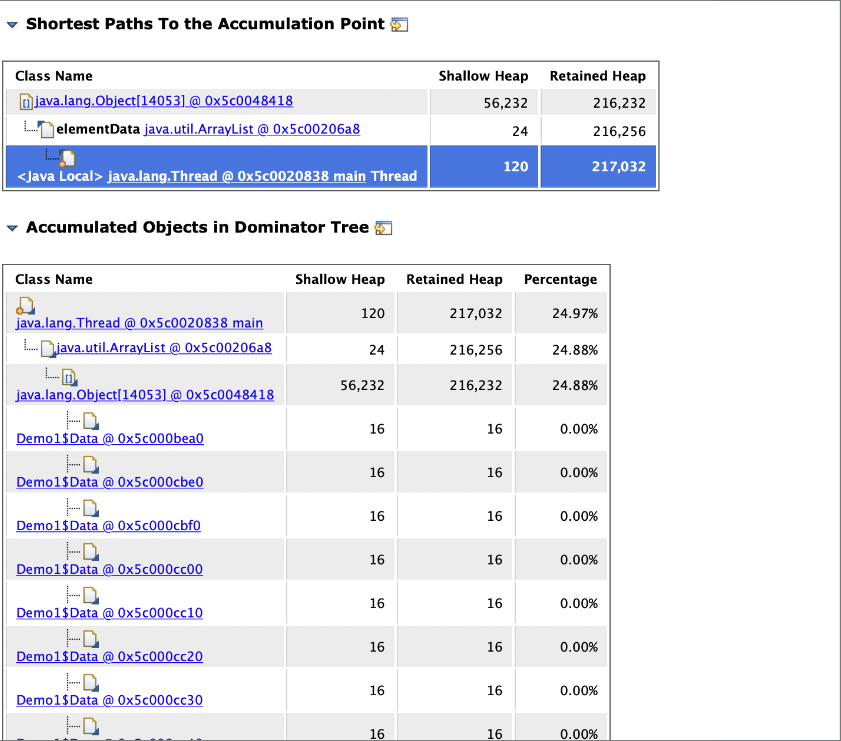
通过这个详细的说明,尤其是那个 “Accumulated Objects in Dominator Tree”,在里面我们可以看到,java.lang.Thread main 线程中引用了一个 java.util.ArrayList,这里面是一个java.lang.Object[] 数组,数组里的每个元素都是Demo1$Data对象实例。
到此为止,就很清楚了,到底是什么对象在内存里占用了过大的内存。所以大家通过这个小小的范例就可以知道,你的系统中那些超大对象到底是什么,用MAT分析内存是非常方便的。
追踪线程执行堆栈,找到问题代码
一旦发现某个线程在执行过程中创建了大量的对象之后,就可以尝试找找这个线程到底执行了哪些代码才创建了这些对象
如下图所示,先点击页面中的一个“See stacktrace”,可然后就会进入一个线程执行代码堆栈的调用链:

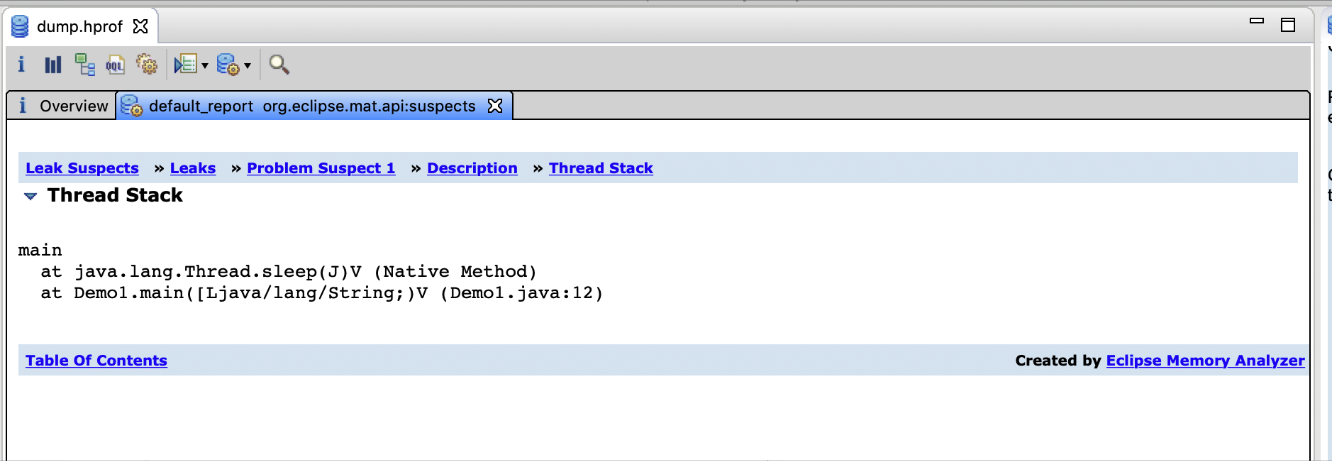
在当时而言,我们就是按照这个方法追踪到了线上系统某个线程的执行堆栈,最终发现的是这个线程执行“String.split()”方法导致产生了大量的对象
那么到底是为什么呢?接着我们来分析一下“String.split()”这个方法。
为什么“String.split()”会造成内存泄漏?
其实原因很简单,当时这个线上系统用的是JDK 1.7。
在JDK 1.6的时候,String.split()方法的实现是这样子的,比如你有一个字符串,“Hello World Ha Ha”,然后你按照空格来切割这个字符串,应该会出来四个字符串“Hello”“World”“Ha”“Ha”,大家应该理解这个吧?
那么JDK 1.6的时候,比如“Hello World Ha Ha”这个原始字符串底层是基于一个数组来存放那些字符的
比如[H,e,l,l,o,,W,o,r,l,d,,H,a,,H,a]这样的数组。然后切割出来的“Hello”字符串他不会对应一个新的数组,而是直接映射到原来那个字符串的数组,采用偏移量表明自己是对应原始数组中的哪些元素。
比如说“Hello”字符串可能就是对应[H,e,l,l,o,,W,o,r,l,d,,H,a,H,a]数组中的0~4位置的元素。
但是JDK 1.7的时候,他的实现是给每个切分出来的字符串都创建一个新的数组,比如“Hello”字符串就对应一个全新的数组,[H,e,l,l,o]。
所以当时那个线上系统的处理逻辑,就是加载大量的数据出来,可能有的时候一次性加载几十万条数据,数据主要是字符串
然后对这些字符串进行切割,每个字符串都会切割为N个小字符串。
这就瞬间导致字符串数量暴增几倍甚至几十倍,这就是系统为什么会频繁产生大量对象的根本原因!!!
因为在本次系统升级之前,是没有String.split()这行代码的,所以当时系统基本运行还算正常,其实一次加载几十万条数据量也很大,当时基本上每小时都会有几次Full GC,不过基本都还算正常。
只不过系统升级之后代码加入了String.split()操作,瞬间导致内存使用量暴增N倍,引发了上面说的每分钟一次Young GC,两分钟一次Full GC,根本原因就在于这行代码的引入。
代码如何进行优化?
后来紧急对这段代码逻辑进行了优化,避免对几十万条数据每一条都执行String.split()这行代码让内存使用量暴增N倍,然后再对那暴增N倍的字符串进行处理。
就当时而言,其实String.split()这个代码逻辑是可用可不用的,所以直接去除就行了。
但是如果从根本而言,说白了,还是这种大数据量处理的系统,一次性加载过多数据到内存里来了,所以后续对代码还是做了很多的优化
比较核心的思路,就是开启多线程并发处理大量的数据,尽量提升数据处理完毕的速度,这样到触发Young GC的时候避免过多的对象存活下来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号