
java 六 Young GC 和 Full GC
糟糕!运行着的线上系统突然卡死无法访问,万恶的JVM GC!
基于JVM运行的系统最怕什么?
在JVM运行的时候,最核心的内存区域,其实就是堆内存,在这里会放各种我们系统中创建出来的对象。
而且堆内存里通常都会划分为新生代和老年代两个内存区域,对象一般来说都是优先放在新生代的。在年轻代(也可以叫做新生代)快要塞满的时候,就会触发年轻代gc,也就是对年轻代进行垃圾回收,需要把年轻代里的垃圾对象都给回收掉。JVM 通过复制算法进行回收,通常来说新生代会有一块Eden区域用来创建对象,默认占据80%的内存,还有两块Survivor区域用来放垃圾回收后存活下来的对象,分别占据10%的内存。
而且大家要注意一点,一旦要对新生代进行垃圾回收了,此时一定会停止系统程序的运行,不让系统程序执行任何代码逻辑了,这个叫做“Stop the World” 此时只能允许后台的垃圾回收器的多个垃圾回收线程去工作,执行垃圾回收。
要给大家说第一个重点了,不知道大家发现了没有,这里有一个很大的问题,就是每次一旦年轻代塞满之后,在进行垃圾回收的时候,这个期间都必须停止系统程序的运行!这个就是基于JVM运行的系统最害怕的问题:系统卡顿问题!
年轻代gc到底多久一次对系统影响不大?
其实通常来说是不大的,不知道大家发现没有,其实年轻代gc几乎没什么好调优的,因为他的运行逻辑非常简单,就是Eden一旦满了无法放新对象就触发一次gc。
一般来说,真要说对年轻代的gc进行调优,只要你给系统分配足够的内存即可,核心点还是在于堆内存的分配、新生代内存的分配
内存足够的话,通常来说系统可能在低峰时期在几个小时才有一次新生代gc,高峰期最多也就几分钟一次新生代gc。
而且新生代采用的复制算法效率极高,因为新生代里存活的对象很少,只要迅速标记出这少量存活对象,移动到Survivor区,然后回收掉其他全部垃圾对象即可,速度很快。
很多时候,一次新生代gc可能也就耗费几毫秒,几十毫秒。大家设想一下,假如说你的系统运行着,然后每隔几分钟或者几十分钟执行一次新生代gc,系统卡顿几十毫秒,就这期间的请求会卡顿几十毫秒,几乎用户都是无感知的,所以新生代gc一般基本对系统性能影响不大。
什么时候新生代gc对系统影响很大?
当你的系统部署在大内存机器上的时候,比如说你的机器是32核64G的机器,此时你分配给系统的内存有几十个G,新生代的Eden区可能30G~40G的内存。
比如类似Kafka、Elasticsearch之类的大数据相关的系统,都是部署在大内存的机器上的,此时如果你的系统负载非常的高,对于大数据系统是很有可能的,比如每秒几万的访问请求到Kafka、Elasticsearch上去。
那么可能导致你Eden区的几十G内存频繁塞满要触发垃圾回收,假设1分钟会塞满一次。
然后每次垃圾回收要停顿掉Kafka、Elasticsearch的运行,然后执行垃圾回收大概需要几秒钟,此时你发现,可能每过一分钟,你的系统就要卡顿几秒钟,有的请求一旦卡死几秒钟就会超时报错,此时可能会导致你的系统频繁出错。
如何解决大内存机器的新生代GC过慢的问题?
那么如何解决这种几十G的大内存机器的新生代GC过慢的问题呢?
用G1垃圾回收器
大家都知道,我们针对G1垃圾回收器,可以设置一个期望的每次GC的停顿时间,比如我们可以设置一个20ms。
那么G1基于他的Region内存划分原理,就可以在运行一段时间之后,比如就针对2G内存的Region进行垃圾回收,此时就仅仅停顿20ms,然后回收掉2G的内存空间,腾出来了部分内存,接着还可以继续让系统运行。
G1天生就适合这种大内存机器的JVM运行,可以完美解决大内存垃圾回收时间过长的问题。
要命的频繁老年代gc问题
其实新生代gc一般问题不会太大,但是真正问题最大的地方,在于频繁触发老年代的GC。
之前给大家讲过对象进入老年代的几个条件:年龄太大了、动态年龄判断规则、新生代gc后存活对象太多无法放入Survivor中。
给大家重新分析一下这几个条件。
- 第一个,对象年龄太大了,这种对象一般很少,都是系统中确实需要长期存在的核心组件,他们一般不需要被回收掉,所以在新生代熬过默认15次垃圾回收之后就会进入老年代。
- 第二个,动态年龄判定规则,如果一次新生代gc过后,发现Survivor区域中的几个年龄的对象加起来超过了Survivor区域的50%,比如说年龄1+年龄2+年龄3的对象大小总和,超过了Survivor区域的50%,此时就会把年龄3以上的对象都放入老年代。
- 第三个,新生代垃圾回收过后,存活对象太多了,无法放入 Surviovr中,此时直接进入老年代。
其实上述条件中,第二个和第三个都是很关键的,通常如果你的新生代中的Survivor区域内存过小,就会导致上述第二个和第三个条件频繁发生,然后导致大量对象快速进入老年代,进而频繁触发老年代的gc,如下图。
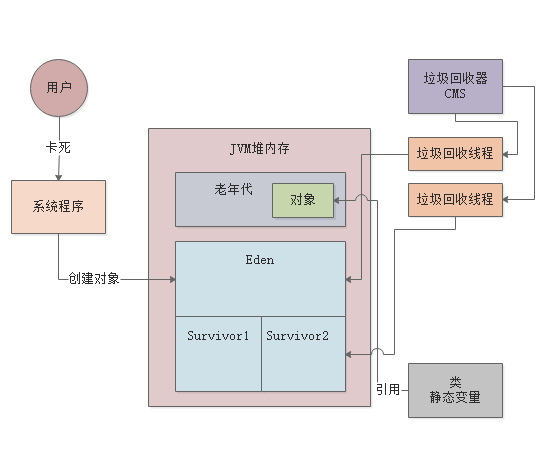
老年代gc通常来说都很耗费时间,无论是CMS垃圾回收器还是G1垃圾回收器,因为比如说CMS就要经历初始标记、并发标记、重新标记、并发清理、碎片整理几个环节,过程非常的复杂,G1同样也是如此。
通常来说,老年代gc至少比新生代gc慢10倍以上,比如新生代gc每次耗费200ms,其实对用户影响不大,但是老年代每次gc耗费2s,那可能就会导致老年代gc的时候用户发现页面上卡顿2s,影响就很大了。
所以一旦你因为jvm内存分配不合理,导致频繁进行老年代gc,比如说几分钟就有一次老年代gc,每次gc系统都停顿几秒钟,那简直对你的系统就是致命的打击。此时用户会发现页面上或者APP上经常性的出现点击按钮之后卡顿几秒钟。
大厂面试题:Young GC和Full GC分别在什么情况下会发生?
Young GC的触发时机
Young GC 其实一般就是在新生代的Eden区域满了之后就会触发,采用复制算法来回收新生代的垃圾
Old GC和Full GC的触发时机
其实之前的文章里也对Old GC的触发时机说的很清晰了,简而言之就是下面几种情况:
1.发生Young GC之前进行检查,如果“老年代可用的连续内存空间” < “新生代历次Young GC后升入老年代的对象总和的平均大小”,说明本次Young GC后可能升入老年代的对象大小,可能超过了老年代当前可用内存空间。
此时必须先触发一次Old GC给老年代腾出更多的空间,然后再执行Young GC
2.执行Young GC之后有一批对象需要放入老年代,此时老年代就是没有足够的内存空间存放这些对象了,此时必须立即触发一次Old GC
3.老年代内存使用率超过了92%,也要直接触发Old GC,当然这个比例是可以通过参数调整的
其实说白了,上述三个条件你概括成一句话,就是老年代空间也不够了,没法放入更多对象了,这个时候务必执行Old GC对老年代进行垃圾回收。
顺便说一句,大家在很多地方看到一个说法,意思是说Old GC执行的时候一般都会带上一次Young GC
可能很多人不理解,其实如果你把咱们这里的几个条件分析清楚了就知道了,一般Old GC很可能就是在Young GC之前触发或者在Young GC之后触发的,所以自然Old GC一般都会跟一次Young GC连带关联在一起了。
另外一个,在很多JVM的实现机制里,其实在上述几种条件达到的时候,他触发的实际上就是Full GC,这个Full GC会包含Young GC、Old GC和永久代的GC
也就是说触发Full GC的时候,可能就会去回收年轻代、老年代和永久代三个区域的垃圾对象。
永久代满了之后怎么办?
大家现在既然都知道了,Full GC有上述几个触发条件,同时触发Full GC的时候其实会带上针对新生代的Young GC,也会有针对老年代的Full GC,还会有针对永久代的GC。所以假如存放类信息、常量池的永久代满了之后,就会触发一次Full GC。
这样Full GC执行的时候,就会顺带把永久代中的垃圾给回收了,但是永久代中的垃圾一般是很少的,因为里面存放的都是一些类,还有常量池之类的东西,这些东西通常来说是不需要回收的。如果永久代真的放满了,回收之后发现没腾出来更多的地方,此时只能抛出内存不够的异常了。
案例实战:每秒10万并发的BI系统是如何频繁发生Young GC的?
刚开始的时候,这个BI系统使用的商家是不多的。因为大家要知道,即使在一个庞大的互联网大厂里,虽然说大厂本身积累了大量的商家,但是你要是针对他们上线一个付费的产品,刚开始未必所有人都买账,所以一开始系统上线大概就少数商家在使用,比如就几千个商家。
所以刚开始系统部署的非常简单,就是用几台机器来部署了上述的BI系统,机器都是普通的4核8G的配置,然后在这个配置之下,一般来说给堆内存中的新生代分配的内存都在1.5G左右,Eden区大概也就1G左右的空间。其实刚开始,在少数商家的量级之下,这个系统是没多大问题的,运行的非常良好,但是问题恰恰就出在突然使用系统的商家数量开始暴涨的时候。
没什么大影响的频繁Young GC
根据我们之前的测算,每个请求大概需要加载出来100kb的数据进行计算,因此每秒500个请求,就需要加载出来50MB的数据到内存中进行计算,只要区区200s,也就是3分钟左右的时间,就会迅速填满Eden区,然后触发一次Young GC对新生代进行垃圾回收。
当然1G左右的Eden进行Young GC其实速度相对是比较快的,可能也就几十ms的时间就可以搞定了,其实对系统性能影响并不大。而且上述BI系统场景下,基本上每次Young GC后存活对象可能就几十MB,甚至是几MB。所以如果仅仅只是这样的话,那么大家可能会看到如下场景,BI系统运行几分钟过后,就会突然卡顿个10ms,但是对终端用户和系统性能几乎是没有影响的
提升机器配置:运用大内存机器
针对这样的一套系统,后来随着越来越多的商家来使用,并发压力越来越大,甚至高峰期会有每秒10万的并发压力
大家想想,如果还是用4核8G的机器来支撑,那么可能需要部署上百台机器来抗住每秒10万的高并发压力。
所以一般针对这种情况,我们会提升机器的配置,本身BI系统就是非常吃内存的系统,所以我们将部署的机器全面提升到了16核32G的高配置机器上去。每台机器可以抗个每秒几千请求,此时只要部署比如二三十台机器就可以了。
但是此时问题就来了,大家可以想一下,如果要是用大内存机器的话,那么新生代至少会分配到20G的大内存,Eden区也会占据16G以上的内存空间,此时如下图所示。
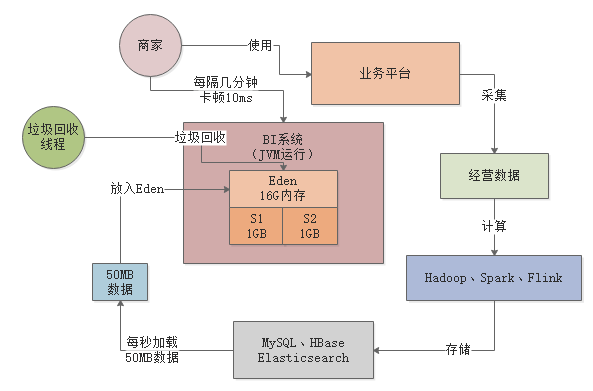
此时每秒几千请求的话,每秒大概会加载到内存中几百MB的数据,那么大概可能几十秒,甚至1分钟左右就会填满Eden区,会就需要执行Young GC。
此时Young GC要回收那么大的内存,速度会慢很多,也许此时就会导致系统卡顿个几百毫秒,或者1秒钟。那么你要是系统卡顿时间过长,必然会导致瞬间很多请求积压排队,严重的时候会导致线上系统时不时出现前端请求超时的问题,就是前端请求之后发现一两秒后还没返回就超时报错了。
用G1来优化大内存机器的Young GC性能
所以当时对这个系统的一个优化,就是采用G1垃圾回收器来应对大内存的Young GC过慢的问题
对G1设置一个预期的GC停顿时间,比如100ms,让G1保证每次Young GC的时候最多停顿100ms,避免影响终端用户的使用。
此时效果是非常显著的,G1会自动控制好在每次Young GC的时候就回收一部分Region,确保GC停顿时间控制在100ms以内
这样的话,也许Young GC的频率会更高一些,但是每次停顿时间很小,这样对系统影响就不大了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号