


1.chattr 用于改变文件扩展属性。
这项指令可改变存放在ext2文件系统上的文件或目录属性,这些属性共有以下8种模式:
- a:让文件或目录仅供附加用途。
- b:不更新文件或目录的最后存取时间。
- c:将文件或目录压缩后存放。
- d:将文件或目录排除在倾倒操作之外。
- i:不得任意更动文件或目录。
- s:保密性删除文件或目录。
- S:即时更新文件或目录。
- u:预防意外删除。
语法
chattr [-RV][-v<版本编号>][+/-/=<属性>][文件或目录...]
参数
-R 递归处理,将指定目录下的所有文件及子目录一并处理。
-v<版本编号> 设置文件或目录版本。
-V 显示指令执行过程。
+<属性> 开启文件或目录的该项属性。
-<属性> 关闭文件或目录的该项属性。
=<属性> 指定文件或目录的该项属性。
实例
用户chattr命令i模式防止系统中某个关键文件被修改(如配置文件)
[root@localhost ~]# chattr +i /etc/my.cnf
slattr可现实文件的chattr属性,添加i模式后,文件变成只读模式无法修改
[root@localhost ~]# lsattr /etc/my.cnf
----i----------- /etc/my.cnf
a模式让某个文件只能往里面追加数据,但不能删除,适用于各种日志文件:
[root@localhost ~]# chattr +a /var/log/messages
[root@localhost ~]# lsattr /var/log/messages
-----a---------- /var/log/messages
2.lsattr查看文件扩展属性
3.file用于辨识文件类型
语法
file [-bcLvz][-f <名称文件>][-m <魔法数字文件>...][文件或目录...]
参数:
- -b 列出辨识结果时,不显示文件名称。
- -c 详细显示指令执行过程,便于排错或分析程序执行的情形。
- -f<名称文件> 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称。
- -L 直接显示符号连接所指向的文件的类别。
- -m<魔法数字文件> 指定魔法数字文件。
- -v 显示版本信息。
- -z 尝试去解读压缩文件的内容。
- [文件或目录...] 要确定类型的文件列表,多个文件之间使用空格分开,可以使用shell通配符匹配多个文件。
[root@localhost ~]# file output.txt
output.txt: ASCII text
[root@localhost ~]# file -b output.txt ==>不显示文件名
ASCII text
[root@localhost ~]# file -b test
directory
[root@localhost ~]# file -i output.txt ==>显示MIME类别
output.txt: text/plain; charset=us-ascii
[root@localhost ~]# file output.txt
output.txt: ASCII text
[root@localhost ~]# file -b output.txt
ASCII text
[root@localhost ~]# file -b test
directory
[root@localhost ~]# file -i output.txt
output.txt: text/plain; charset=us-ascii
显示符号链接文件类型
[root@localhost ~]# ls -l /etc/init.d
lrwxrwxrwx. 1 root root 11 Jul 12 2019 /etc/init.d -> rc.d/init.d
[root@localhost ~]# file /etc/init.d
/etc/init.d: symbolic link to `rc.d/init.d'
[root@localhost ~]# file -L /etc/init.d
/etc/init.d: directory
[root@localhost ~]# file /etc/rc.d/init.d/
/etc/rc.d/init.d/: directory
4.md5sum用于生成和校验文件的md5值
它会逐位对文件的内容进行校验。是文件的内容,与文件名无关,也就是文件内容相同,其md5值相同。md5值是一个128位的二进制数据,转换成16进制则是32(128/4)位的进制值。
md5校验,有很小的概率不同的文件生成的md5可能相同。比md5更安全的校验算法还有SHA*系列的。
在网络传输时,我们校验源文件获得其md5sum,传输完毕后,校验其目标文件,并对比如果源文件和目标文件md5 一致的话,则表示文件传输无异常。否则说明文件在传输过程中未正确传输。
选项:
-b 以二进制模式读入文件内容
-t 以文本模式读入文件内容
-c 根据已生成的md5值,对现存文件进行校验
--status 校验完成后,不生成错误或正确的提示信息,可以通过命令的返回值来判断。
[root@localhost ~]# file person1.txt
person1.txt: ASCII text
[root@localhost ~]# md5sum person1.txt
8c8cc2f28ba7067f71052fb2ce28ac52 person1.txt
[root@localhost ~]# md5sum -b person1.txt
8c8cc2f28ba7067f71052fb2ce28ac52 *person1.txt
[root@localhost ~]# md5sum -t person1.txt
8c8cc2f28ba7067f71052fb2ce28ac52 person1.txt
[root@localhost ~]# md5sum -t person1.txt > tt1.md5
[root@localhost ~]# md5sum -c tt1.md5
person1.txt: OK
[root@localhost ~]# md5sum -c test.md5 |grep -v "OK" ==>与grep联合使用过滤被修改的文件
5.cat查看文件内容正向输出,与之相反的是tac 反向输出
[root@localhost ~]# cat test.txt
11
222
333
[root@localhost ~]# tac test.txt
333
222
11
6.more 命令
功能类似于 cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。
命令参数:
+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下 n 行,需要定义。默认为 1 行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
实例:显示文件20行起的内容
more +20 /etc/my.cnf
列出文件目录详细信息,借助管道符使每次显示2行
ls -l /etc | more -2
按空格显示下2行
7.less 命令
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
常用命令参数:
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
实例:
(1)ps 查看进程信息并通过 less 分页显示
ps -ef | less -N
(2)查看多个文件
less test1.log test2.log
可以使用 n 查看下一个,使用 p 查看前一个
8.head 命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
常用参数:
-n<行数> 显示的行数(行数为复数表示从最后向前数)
实例:
(1)显示 1.log 文件中前 20 行
head 1.log -n 20
(2)显示 1.log 文件前 20 字节
head -c 20 log2014.log
(3)显示 t.log最后 10 行
head -n -10 t.log
9.tail 命令
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
常用参数:
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
(1)循环读取逐渐增加的文件内容
ping 127.0.0.1 > ping.log &
后台运行:可使用 jobs -l 查看,也可使用 fg 将其移到前台运行。
tail -f ping.log
10.cut 命令 将文件的每一行按指定分隔符分割并输出。
语法
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
使用说明:
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。
如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
参数:
- -b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
- -c :以字符为单位进行分割。
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
- -n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
实例:
[root@localhost ~]# cat test.txt
root /tty1/ Feb /18 07:20
root /pts/2 Feb /19 14:51 (192.168.204.1)
root /pts/3 Feb /19 14:45 (192.168.204.1)
[root@localhost ~]# cat test.txt |cut -d / -f2
tty1
pts
pts
11.split命令用于将一个文件分割成数个。 该指令将大文件分割成较小的文件,在默认情况下将按照每1000行切割成一个小文件。
语法
split [--help][--version][-<行数>][-b <字节>][-C <字节>][-l <行数>][要切割的文件][输出文件名]
参数说明:
- -<行数> : 指定每多少行切成一个小文件
- -b<字节> : 指定每多少字节切成一个小文件
- --help : 在线帮助
- --version : 显示版本信息
- -C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性
- [输出文件名] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
实例:
使用指令"split"将文件"test.log"每3行切割成一个文件以test文件名为开头输出,输入如下命令
[root@localhost ~]# split -3 test.log test
以上命令执行后,指令"split"会将原来的大文件"test.log"切割成多个以"test"开头的小文件(默认不指定文件名以“x”开头)。而在这些小文件中,每个文件都只有3行内容。
使用指令"ls"查看当前目录结构,如下所示:
[root@localhost ~]# ls
test.log testaa testab testac u_ex190819.log
12.paste命令用于合并文件的列。paste 指令会把每个文件以列对列的方式,一列列地加以合并
语法
paste [-s][-d <间隔字符>][--help][--version][文件...]
参数:
- -d<间隔字符>或--delimiters=<间隔字符> 用指定的间隔字符取代跳格字符。
- -s或--serial 串列进行而非平行处理。
- --help 在线帮助。
- --version 显示帮助信息。
- [文件…] 指定操作的文件路径
实例:
将上面拆分的三个文件进行合并
[root@localhost ~]# paste testaa testab testac
11111111111111111111 4444444444444444444 7777777777777777
22222222222222222222 555555555555555555 888888888888888888
33333333333333333 66666666666666666 99999999999999999
[root@localhost ~]# paste -s testaa testab testac
11111111111111111111 22222222222222222222 33333333333333333
4444444444444444444 555555555555555555 66666666666666666
7777777777777777 888888888888888888 99999999999999999
[root@localhost ~]# paste -s -d / testaa testab testac
11111111111111111111/22222222222222222222/33333333333333333
4444444444444444444/555555555555555555/66666666666666666
7777777777777777/888888888888888888/99999999999999999
注意:参数"-s"只是将testfile文件的内容调整显示方式,并不会改变原文件的内容格式。
13.sort用于将文本文件内容加以排序。
sort可针对文本文件的内容,以行为单位来排序。
语法
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
参数说明:
- -b 忽略每行前面开始出的空格字符。
- -c 检查文件是否已经按照顺序排序。
- -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
- -f 排序时,将小写字母视为大写字母。
- -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
- -m 将几个排序好的文件进行合并。
- -M 将前面3个字母依照月份的缩写进行排序。
- -n 依照数值的大小排序。
- -k, --key=KEYDEF 通过键排序;KEYDEF给出位置和类型
- -u 意味着是唯一的(unique),输出的结果是去完重了的。
- -o<输出文件> 将排序后的结果存入指定的文件。
- -r 以相反的顺序来排序。
- -t<分隔字符> 指定排序时所用的栏位分隔字符。
- +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- --help 显示帮助。
- --version 显示版本信息。
实例:
将文件内容以数字大小排序
[root@localhost ~]# cat test.log
fasf 1
gewg 3
hhr 5
jhrgv 2
ntnt 8
ff 6
uuu 7
rr 4
fr 9
[root@localhost ~]# sort -n -k2 test.log
fasf 1
jhrgv 2
gewg 3
rr 4
hhr 5
ff 6
uuu 7
ntnt 8
fr 9
[root@localhost ~]#sort -u test.log ==>排序去重
14.uniq去除重复行
命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。uniq 可检查文本文件中重复出现的行
语法
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件]
参数:
- -c或--count 在每列旁边显示该行重复出现的次数。
- -d或--repeated 仅显示重复出现的行列。
- -D只打印重复行
- -f<栏位>或--skip-fields=<栏位> 忽略比较指定的栏位。
- -s<字符位置>或--skip-chars=<字符位置> 忽略比较指定的字符。
- -u或--unique 仅显示出一次的行列。
- -w<字符位置>或--check-chars=<字符位置> 指定要比较的字符。
- --help 显示帮助。
- --version 显示版本信息。
- [输入文件] 指定已排序好的文本文件。如果不指定此项,则从标准读取数据;
- [输出文件] 指定输出的文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
a.不加参数只对相邻的相同行去重
uniq test.txt
b.sort命令让重复的行相邻
先用sort做排序,让重复的行相邻,然后用uniq去重
sort test.txt | uniq
用sort -u即可实现该功能,这里的-u就是uniq
c.去重计数
参数-c --count 去重计数
sort test.txt | uniq -c
实例:
[root@localhost ~]# cat test.log
11111
22222
22222
33333
11111
11111
[root@localhost ~]# cat test.log |uniq ===>不加参数只对相邻的相同行去重
11111
22222
33333
11111
[root@localhost ~]# cat test.log |sort|uniq -c
3 11111
2 22222
1 33333
[root@localhost ~]# cat test.log |sort|uniq -D
11111
11111
11111
22222
22222
15.wc用户统计文件的行数、单词输或字节数
利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法
wc [-clw][--help][--version][文件...]
参数:
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 只显示行数。
- -w或--words 只显示字数。
- --help 在线帮助。
- --version 显示版本信息。
实例:
[root@localhost ~]# cat test.log |wc -l
6
[root@localhost ~]# cat test.log |wc -c
36
16.iconv用于转换文件编码格式
用法: iconv [选项...] [文件...]
转换给定文件的编码。
输入/输出格式规范:
-f, --from-code=名称 原始文本编码
-t, --to-code=名称 输出编码
信息:
-l, --list 列举所有已知的字符集
输出控制:
-c 从输出中忽略无效的字符
-o, --output=FILE 输出文件
-s, --silent 关闭警告
--verbose 打印进度信息
-?, --help 给出该系统求助列表
--usage 给出简要的用法信息
-V, --version 打印程序版本号
长选项的强制或可选参数对对应的短选项也是强制或可选的。
实例:
iconv的命令格式:
iconv -f encoding -t encoding inputfile
比如将一个UTF-8 编码的文件转换成GBK编码
iconv -f GBK -t UTF-8 file1 -o file217.dos2unix将DOS格式文件转换为UNIX格式
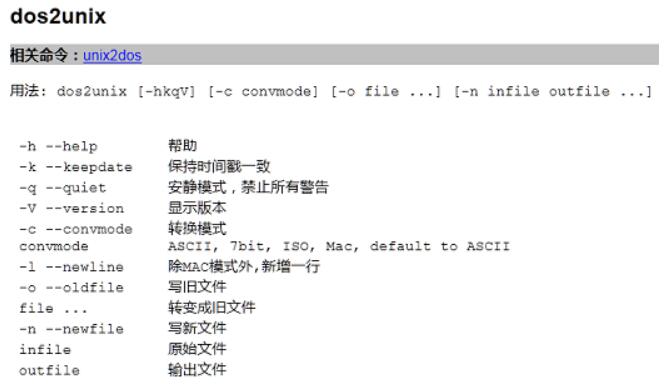
将DOS格式文本文件转换成Unix格式,最简单的用法就是dos2unix直接跟上文件名。
格式:dos2unix file
如果一次转换多个文件,把这些文件名直接跟在dos2unix之后。(注:也可以加上-o参数,也可以不加,效果一样)
格式:dos2unix file1 file2 file3
格式:dos2unix -o file1 file2 file3
如果要保持文件时间戳不变,加上-k参数。所以上面几条命令都是可以加上-k参数来保持文件时间戳的。
格式:dos2unix -k file
格式:dos2unix -k file1 file2 file3
格式:dos2unix -k -o file1 file2 file3
格式:dos2unix -k -n oldfile newfile
注:unix2dos命令的使用方式与dos2unix命令的类似。
18.diff 全拼difference,比较文件的差异,常用于文本文件。
diff以逐行的方式,比较文本文件的异同处。如果指定要比较目录,则diff会比较目录中相同文件名的文件,但不会比较其中子目录。
语法
diff [-abBcdefHilnNpPqrstTuvwy][-<行数>][-C <行数>][-D <巨集名称>][-I <字符或字符串>][-S <文件>][-W <宽度>][-x <文件或目录>][-X <文件>][--help][--left-column][--suppress-common-line][文件或目录1][文件或目录2]
参数:
- -<行数> 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
- -a或--text diff预设只会逐行比较文本文件。
- -b或--ignore-space-change 不检查空格字符的不同。
- -B或--ignore-blank-lines 不检查空白行。
- -c 显示全部内文,并标出不同之处。
- -C<行数>或--context<行数> 与执行"-c-<行数>"指令相同。
- -d或--minimal 使用不同的演算法,以较小的单位来做比较。
- -D<巨集名称>或ifdef<巨集名称> 此参数的输出格式可用于前置处理器巨集。
- -e或--ed 此参数的输出格式可用于ed的script文件。
- -f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
- -H或--speed-large-files 比较大文件时,可加快速度。
- -l<字符或字符串>或--ignore-matching-lines<字符或字符串> 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
- -i或--ignore-case 不检查大小写的不同。
- -l或--paginate 将结果交由pr程序来分页。
- -n或--rcs 将比较结果以RCS的格式来显示。
- -N或--new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:
- Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
- -p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
- -P或--unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
- -q或--brief 仅显示有无差异,不显示详细的信息。
- -r或--recursive 比较子目录中的文件。
- -s或--report-identical-files 若没有发现任何差异,仍然显示信息。
- -S<文件>或--starting-file<文件> 在比较目录时,从指定的文件开始比较。
- -t或--expand-tabs 在输出时,将tab字符展开。
- -T或--initial-tab 在每行前面加上tab字符以便对齐。
- -u,-U<列数>或--unified=<列数> 以合并的方式来显示文件内容的不同。
- -v或--version 显示版本信息。
- -w或--ignore-all-space 忽略全部的空格字符。
- -W<宽度>或--width<宽度> 在使用-y参数时,指定栏宽。
- -x<文件名或目录>或--exclude<文件名或目录> 不比较选项中所指定的文件或目录。
- -X<文件>或--exclude-from<文件> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件。
- -y或--side-by-side 以并列的方式显示文件的异同之处。
- --help 显示帮助。
- --left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容。
- --suppress-common-lines 在使用-y参数时,仅显示不同之处
实例:
以并列方式宽度20显示两个文件异同之处
[root@localhost ~]# diff test.log test1.log -y -W 20
| 11111
22222 22222
22222 22222
33333 33333
11111 11111
11111 | 43333
> 5555
说明:
- "|"表示前后2个文件内容有不同
- "<"表示后面文件比前面文件少了1行内容
- ">"表示后面文件比前面文件多了1行内容
19.vimdiff可视化文本文件比较工具,常用于文本文件
启动方法
首先保证系统中的diff命令是可用的。Vim的diff模式是依赖于diff命令的。Vimdiff的基本用法就是:
# vimdiff FILE_LEFT FILE_RIGHT
或者
# vim -d FILE_LEFT FILE_RIGHT
实例:
[root@localhost ~]# vimdiff test.log test1.log ==>默认是竖排显示
[root@localhost ~]# vimdiff -o test.log test1.log ==>加-o可调整为横排显示
20.rev反向输出文件内容
实例:
[root@localhost ~]# cat test.log
123456
[root@localhost ~]# rev test.log
654321
21.grep/egrep过滤字符串
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --revert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
实例:
过滤文本中包含字母的行
[root@localhost ~]# cat test.log
1a23456
aab2222
3333
444
jj5
[root@localhost ~]# cat test.log |grep -v [a-z]
3333
444
22.join用于将两个文件中,指定栏位内容相同的行连接起来。
找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
语法
join [-i][-a<1或2>][-e<字符串>][-o<格式>][-t<字符>][-v<1或2>][-1<栏位>][-2<栏位>][--help][--version][文件1][文件2]
参数:
- -a<1或2> 除了显示原来的输出内容之外,还显示指令文件中没有相同栏位的行。
- -e<字符串> 若[文件1]与[文件2]中找不到指定的栏位,则在输出中填入选项中的字符串。
- -i或--igore-case 比较栏位内容时,忽略大小写的差异。
- -o<格式> 按照指定的格式来显示结果。
- -t<字符> 使用栏位的分隔字符。
- -v<1或2> 跟-a相同,但是只显示文件中没有相同栏位的行。
- -1<栏位> 连接[文件1]指定的栏位。
- -2<栏位> 连接[文件2]指定的栏位。
- --help 显示帮助。
- --version 显示版本信息。
实例
以默认的方式比较两个文件,将两个文件中指定字段的内容相同的行连接起来
[root@localhost ~]# cat test.log
zhangsan 22
lisi 30
wang 25
[root@localhost ~]# cat test1.log
zhangsan 2002
lisi 2030
wang 2225
[root@localhost ~]# join test.log test1.log
zhangsan 22 2002
lisi 30 2030
wang 25 2225
22.tr命令用于转换或删除文件中的字符。
tr 指令从标准输入设备读取数据,经过字符串转译后,将结果输出到标准输出设备。
参数说明:
- -c, --complement:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
- -d, --delete:删除指令字符
- -s, --squeeze-repeats:缩减连续重复的字符成指定的单个字符
- -t, --truncate-set1:削减 SET1 指定范围,使之与 SET2 设定长度相等
- --help:显示程序用法信息
- --version:显示程序本身的版本信息
字符集合的范围:
- \NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
- \\ 反斜杠
- \a Ctrl-G 铃声
- \b Ctrl-H 退格符
- \f Ctrl-L 走行换页
- \n Ctrl-J 新行
- \r Ctrl-M 回车
- \t Ctrl-I tab键
- \v Ctrl-X 水平制表符
- CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
- [CHAR*] :这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止
- [CHAR*REPEAT] :这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始)
- [:alnum:] :所有字母字符与数字
- [:alpha:] :所有字母字符
- [:blank:] :所有水平空格
- [:cntrl:] :所有控制字符
- [:digit:] :所有数字
- [:graph:] :所有可打印的字符(不包含空格符)
- [:lower:] :所有小写字母
- [:print:] :所有可打印的字符(包含空格符)
- [:punct:] :所有标点字符
- [:space:] :所有水平与垂直空格符
- [:upper:] :所有大写字母
- [:xdigit:] :所有 16 进位制的数字
- [=CHAR=] :所有符合指定的字符(等号里的 CHAR,代表你可自订的字符)
实例
将文件中的小写字母转换成大写字母
[root@localhost ~]# cat test.log
a B c d e
[root@localhost ~]# cat test.log |tr a-z A-z
A B C D E
大小写转换,也可以通过[:lower:][:upper:]参数来实现
[root@localhost ~]# cat test.log
[root@localhost ~]# cat test.log |tr [:lower:] [:upper:]
A B C D E

 浙公网安备 33010602011771号
浙公网安备 33010602011771号