
NoSQL数据库与关系数据库的比较
SQL,即结构化查询语言,是传统的关系型数据库的查询语言。SQL数据库能够通过简化CRUD操作,处理数据库中的结构化数据。此处的CRUD代表了创建(create)、检索(或读取,retrieve、read)、更新(update)和删除(delete),四种控制数据的主要操作。
SQL数据库通常被称为关系型数据库管理系统(RDBMS)。由于此类系统主要利用基于行的数据库结构,连接各个数据表之间的相关数据对象,因此传统的RDBMS使用的是SQL语法。我们熟悉的Microsoft Access、MySQL、Microsoft SQL Server、SQLite、Oracle Database、IBM DB2、以及Backendless等都是RDBMS类型的SQL数据库。
而NoSQL数据库并没有任何固定用于保存数据的结构化数据表。从技术上讲,所有非关系型数据库都可以被称为NoSQL数据库。不同于关系型数据库,NoSQL数据库不但可以被快速地设置,并且只需最少量的预先规划(pre-planning)。常见的NoSQL数据库示例包括:MongoDB、DynamoDB、SimpleDB、CouchDB、CouchBase、OrientDB、InfiniteGraph、Neo4j、FlockDB、Cassandra、以及HBase等。
NoSQL是一种不同于关系数据库的数据库管理系统设计方式,是对非关系型数据库的统称,它所采用的数据模型并非传统关系数据库的关系模型,而是类似键/值、列族、文档等非关系模型。NoSQL数据库没有固定的表结构,通常也不存在连接操作,也没有严格遵守ACID约束。因此,与关系数据库相比,NoSQL具有灵活的水平可扩展性,可以支持海量数据存储。
什么是ACID?
事务的原子性(Atomicity):是指一个事务要么全部执行,要么不执行,也就是说一个事务不可能只执行了一半就停止了。比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱。不可能划了卡,而钱却没出来。这两步必须同时完成,要么就不完成。
事务的一致性(Consistency):是指事务的运行并不改变数据库中数据的一致性。例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变。
独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态。因为这样可能会导致数据不一致。
持久性(Durability):事务的持久性是指事务执行成功以后,该事务对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚
NoSQL数据库的特点
(1)灵活的可扩展性
传统的关系型数据库由于自身设计机理的原因,通常很难实现“横向扩展”,在面对数据库负载大规模增加时,往往需要通过升级硬件来实现“纵向扩展”。NoSQL数据库在设计之初就是为了满足“横向扩展”的需求,因此天生具备良好的水平扩展能力。
(2)灵活的数据模型
关系数据库具有规范的定义,遵守各种严格的约束条件。这种做法虽然保证了业务系统对数据一致性的需求,但是过于死板的数据模型,也意味着无法满足各种新兴的业务需求。相反,NoSQL数据库采用键/值、列族等非关系模型,允许在一个数据元素里存储不同类型的数据。
(3)与云计算紧密融合
云计算具有很好的水平扩展能力,可以根据资源使用情况进行自由伸缩,各种资源可以动态加人或退出,NoSQL数据库可以凭借自身良好的横向扩展能力,充分自由利用云计算基础设施,很好地融人到云计算环境中,构建基于NoSQL的云数据库服务。
NoSQL兴起的原因
1、关系数据库已经无法满足Web2.0的需求。主要表现在以下几个方面:
(1)无法满足海量数据的管理需求
对于上述网站而言,很快就可以产生超过10亿条的记录,对于关系数据库来说,在一张10亿条记录的表里进行SQL查询,效率极其低下。
(2)无法满足数据高并发的需求
(3)无法满足高可扩展性和高可用性的需求
2.关系数据库的关键特性在Web 2.0时代成为“鸡肋”
关系数据库的关键特性包括完善的事务机制和高效的查询机制。但是,关系数据库引以为傲的两个关键特性,到了Web2.0时代却成了鸡肋,主要表现在以下几个方面:
(1) Web 2.0网站系统通常不要求严格的数据库事务
对于许多Web 2.0网站而言,数据库事务已经不是那么重要。数据库事务通常有一套复杂的实现机制来保证数据库一致性,需要大量系统开销,对于包含大量频繁实时读写请求的Web 2.0网站而言,实现事务的代价是难以承受的。
(2)Web 2.0并不要求严格的读写实时性
对于关系数据库而言,一旦有一条数据记录成功插人数据库中,就可以立即被查询。
对于Web 2.0而言,没有这种实时读写需求。
(3)Web 2.0通常不包含大量复杂的SQL查询
复杂的SQL查询通常包含多表连接操作。但是,Web 2.0网站在设计时就已经尽量减少甚至避免这类操作,通常只采用单表的主键查询,因此关系数据库的查询优化机制在Web 2.0中也就难以有所作为。
NoSQL与关系数据库的比较
RDBMS:关系数据库
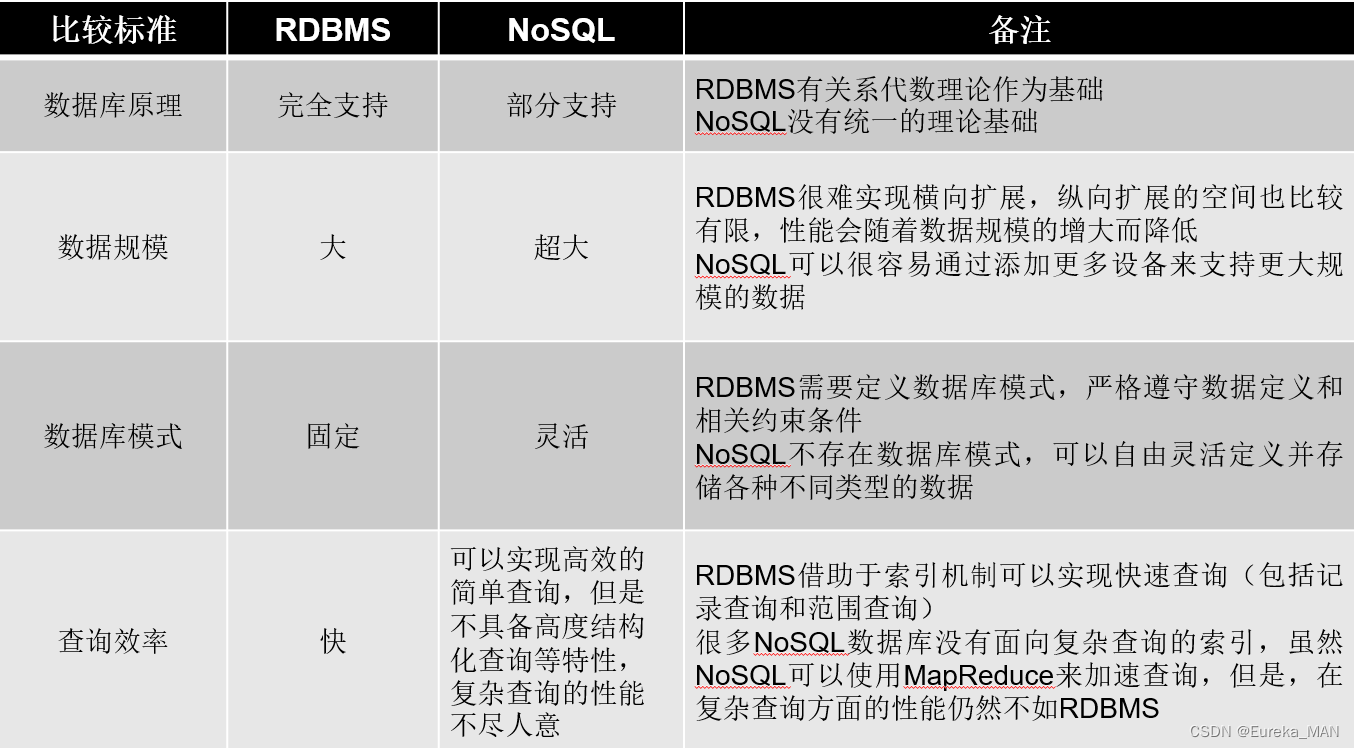
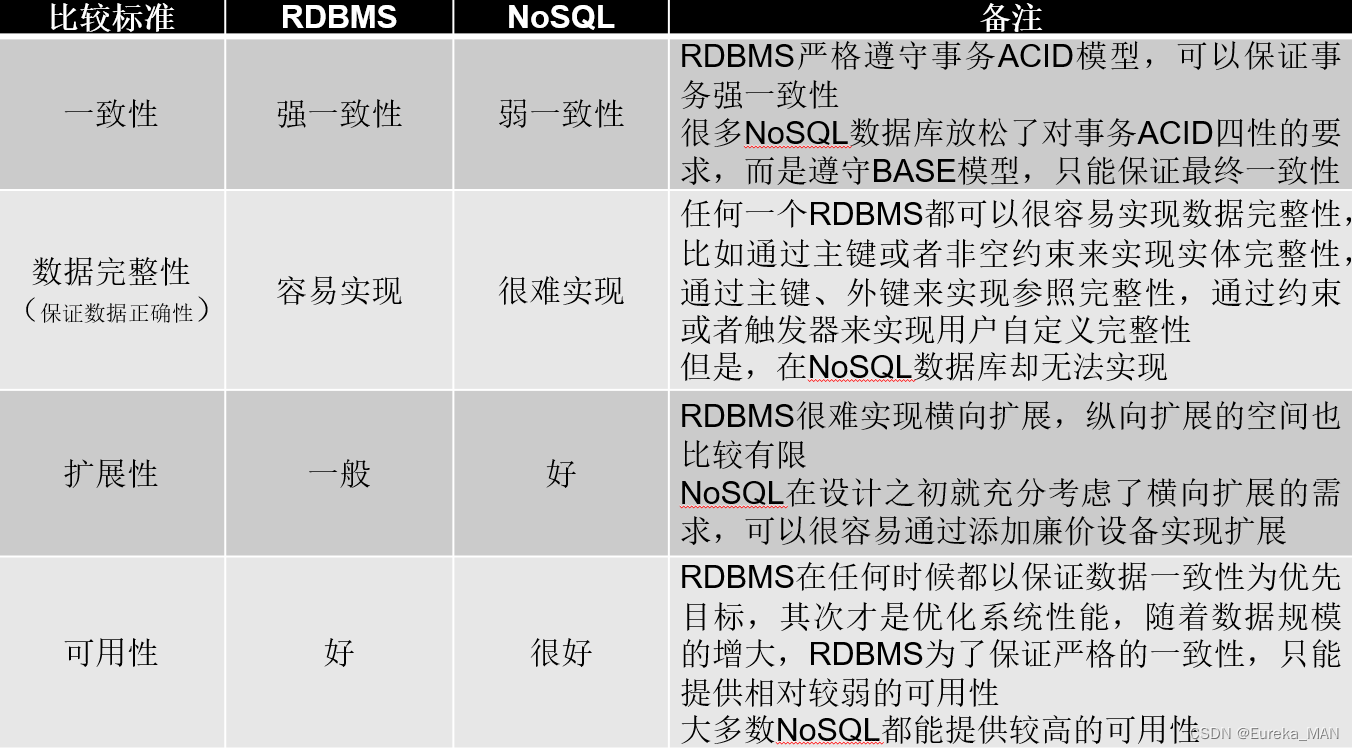

1.NoSQL与关系数据库比较 小结:
(1)关系数据库
优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等
(2)NoSQL数据库
优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
(3)关系数据库和NoSQL数据库各有优缺点,彼此无法取代
关系数据库应用场景:电信、银行等领域的关键业务系统,需要保证强事务一致性
NoSQL数据库应用场景:互联网企业、传统企业的非关键业务(比如数据分析)
采用混合架构
案例:亚马逊公司就使用不同类型的数据库来支撑它的电子商务应用
对于“购物篮”这种临时性数据,采用键值存储会更加高效
当前的产品和订单信息则适合存放在关系数据库中
NoSQL的四大类型
NoSQL数据库虽然数量众多,但是,归结起来,典型的NoSQL数据库通常包括键值数据库、列族数据库、文档数据库和图形数据库
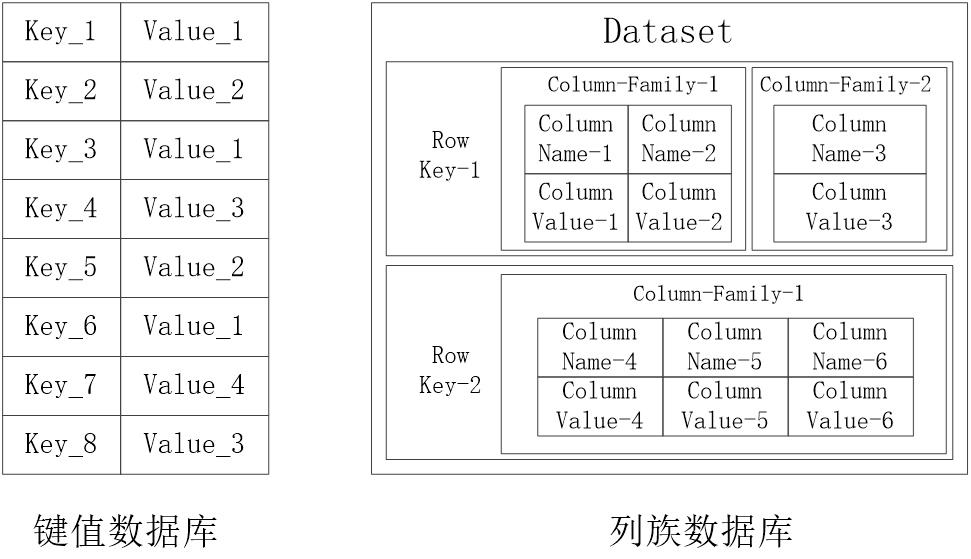
1.键值数据库
键值数据库(Key-Value Database) 的表中有一个特定的Key和一个指针指向特定的Value。Key可以用来定位Value,即存储和检索具体的Value。Value对数据库而言是透明不可见的,不能对Value进行索引和查询,只能通过Key进行查询。Value可以用来存储任意类型的数据,包括整型、字符型、数组、对象等。
应用场景:一个面向会话的应用程序(如 Web 应用程序)在用户登录时启动会话,并保持活动状态直到用户注销或会话超时。在此期间,应用程序将所有与会话相关的数据存储在主内存或数据库中。会话数据可能包括用户资料信息、消息、个性化数据和主题、建议、有针对性的促销和折扣。每个用户会话具有唯一的标识符。除了主键之外,任何其他键都无法查询会话数据,因此快速键值存储更适合于会话数据。一般来说,键值数据库所提供的每页开销可能比关系数据库要小。

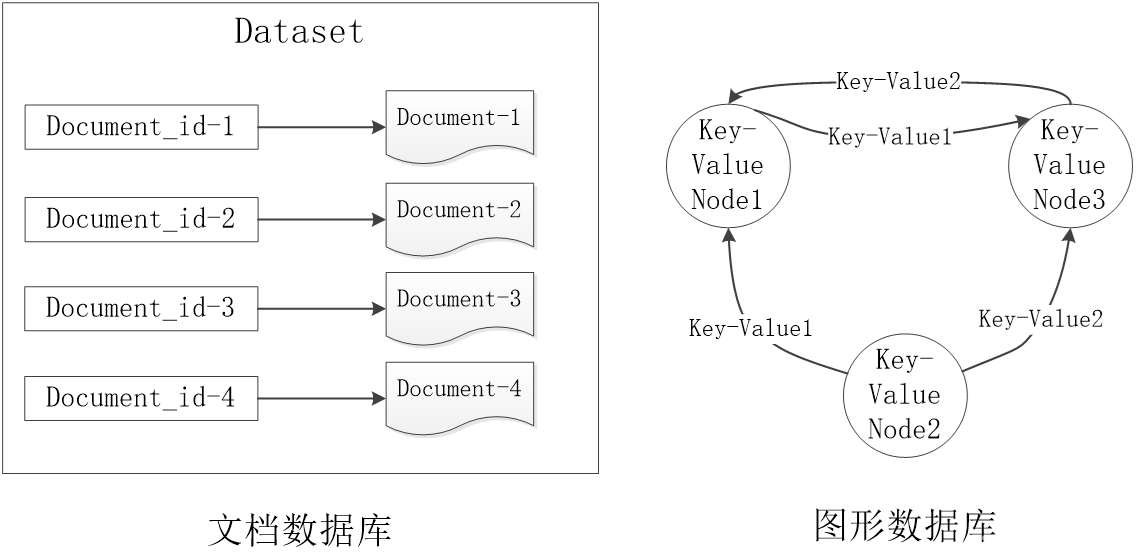
2.列族数据库

3.文档数据库
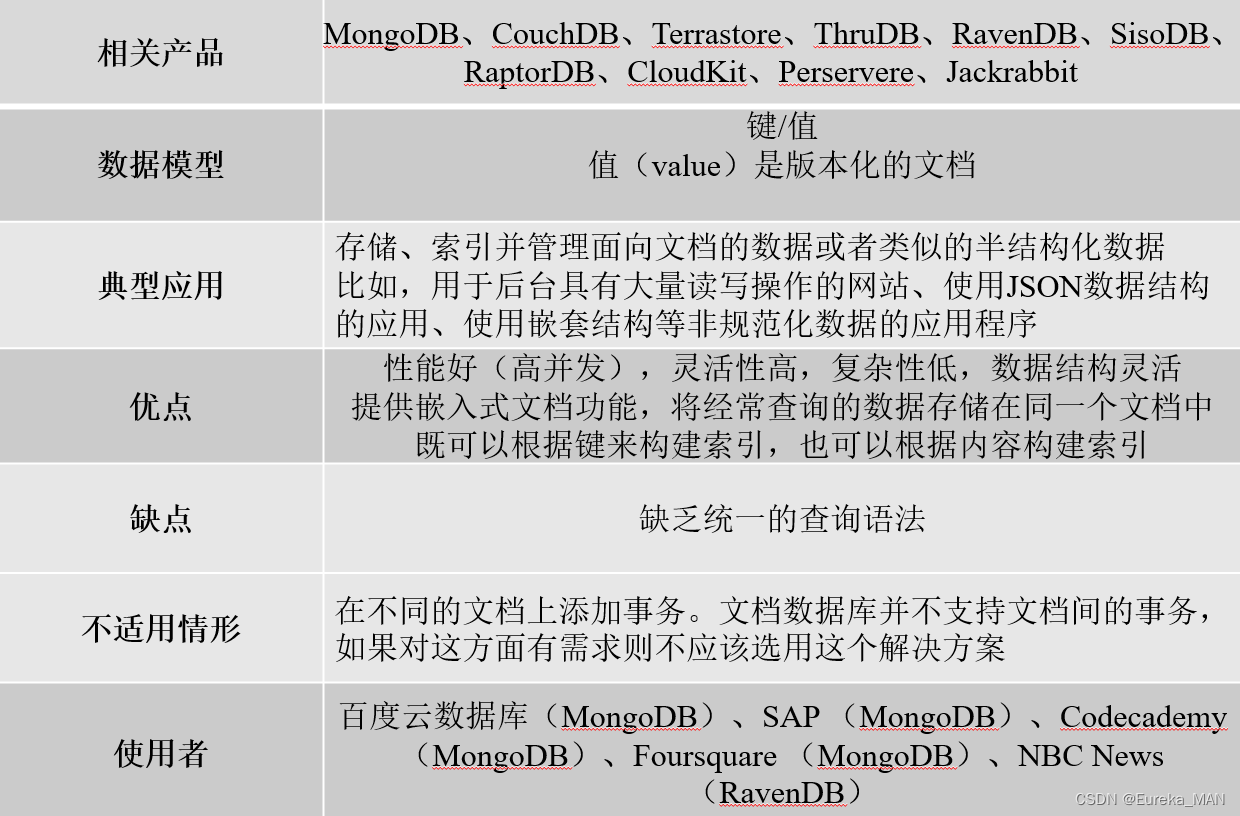
4.图形数据库
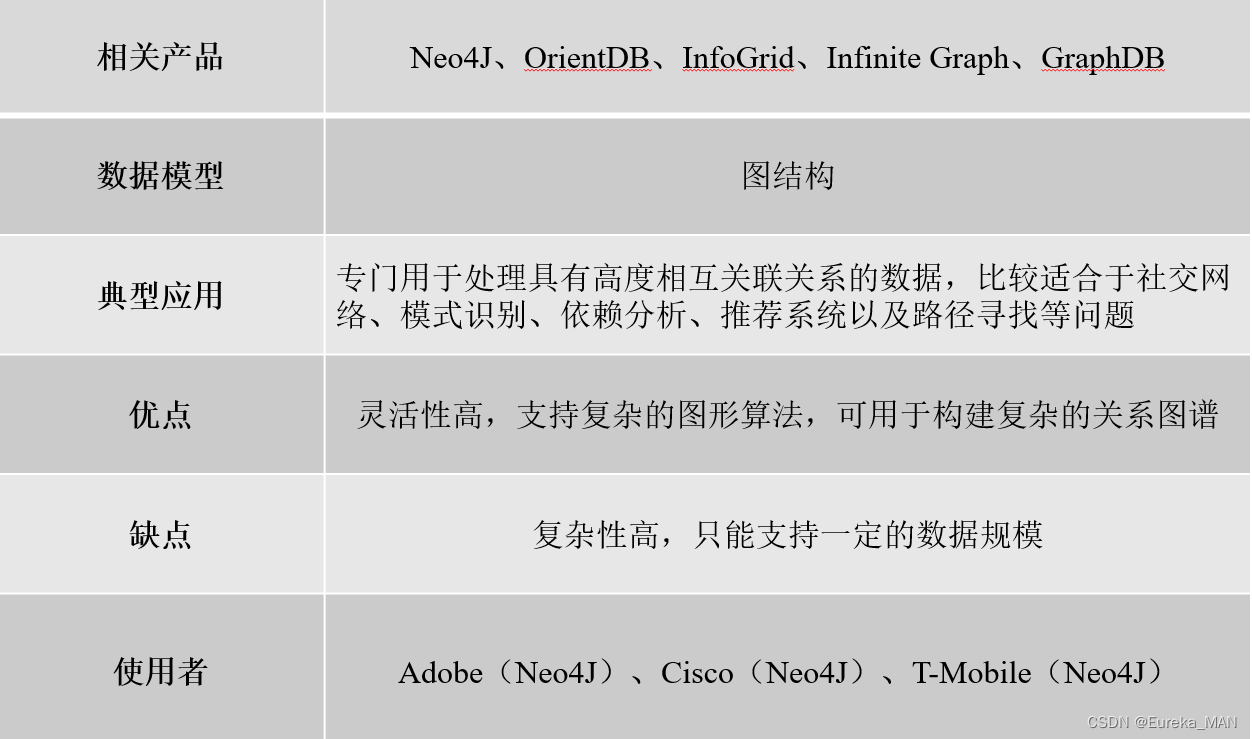
5.不同类型数据库比较分析
MySQL:产生年代较早,而且随着LAMP大潮得以成熟。尽管其没有什么大的改进,但是新兴的互联网使用的最多的数据库
MongoDB:是个新生事物,提供更灵活的数据模型、异步提交、地理位置索引等五花十色的功能
HBase:是个“仗势欺人”的大象兵。依仗着Hadoop的生态环境,可以有很好的扩展性。但是就像象兵一样,使用者需要养一头大象(Hadoop),才能驱使他
Redis:是键值存储的代表,功能最简单。提供随机数据存储。就像一根棒子一样,没有多余的构造。但是也正是因此,它的伸缩性特别好。就像悟空手里的金箍棒,大可捅破天,小能成缩成针
NoSQL的三大基石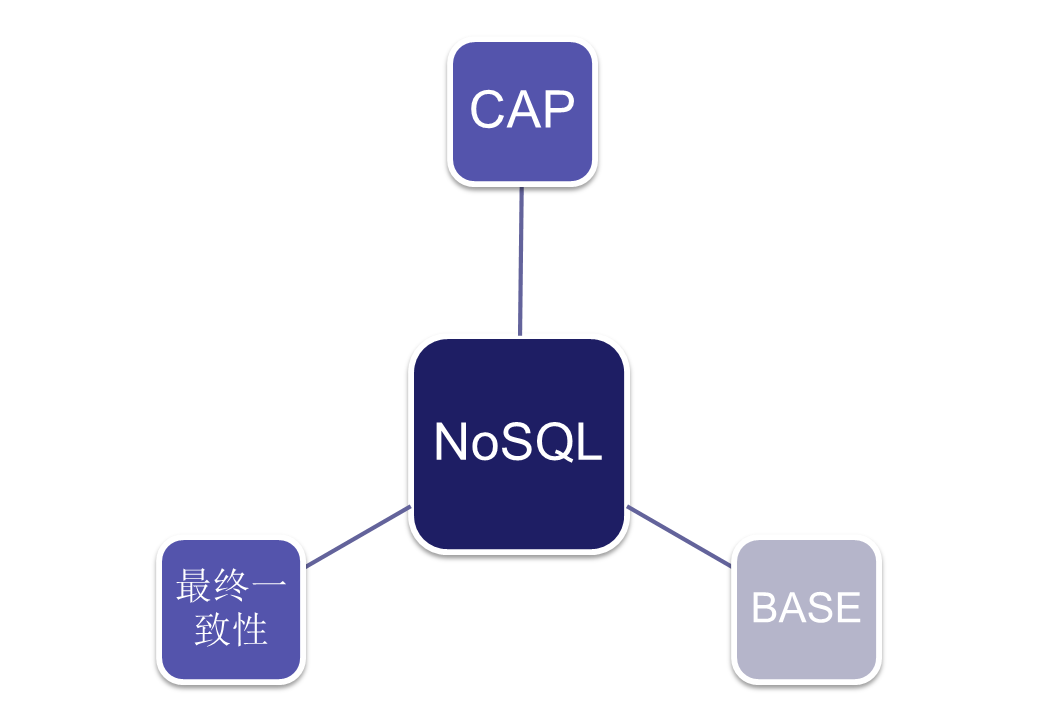
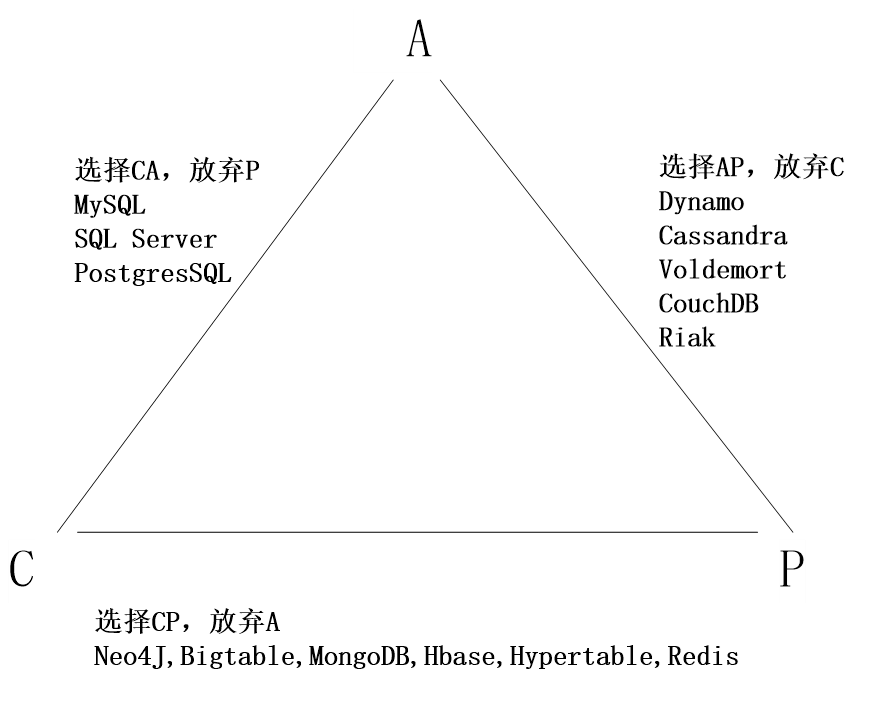
所谓的CAP指的是:
C(Consistency):一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
A:(Availability):可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应;
P(Tolerance of Network Partition):分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP理论告诉我们,一个分布式系统不可能同时满足一致性、可用性和分区容忍性这三个需求,最多只能同时满足其中两个,正所谓“鱼和熊掌不可兼得”。
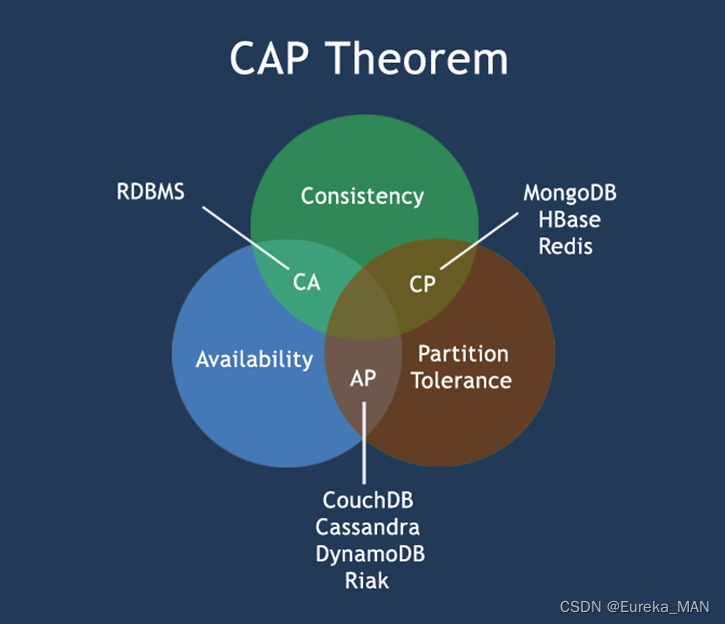
当处理CAP的问题时,可以有几个明显的选择:
CA:也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、SQL Server和PostgreSQL),都采用了这种设计原则,因此,扩展性都比较差
CP:也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
AP:也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
BASE
前面说到ACID ,现在浅谈一下BASE(Basically Availble, Soft-state, Eventual consistency)
ACID
BASE
原子性(Atomicity)
基本可用(Basically Available)
一致性(Consistency)
软状态/柔性事务(Soft state)
隔离性(Isolation)
最终一致性 (Eventual consistency)
持久性 (Durable)
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency):
基本可用
基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现
软状态
“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性
最终一致性
一致性的类型包括强一致性和弱一致性,二者的主要区别在于高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据;反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。而最终一致性只不过是弱一致性的一种特例,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。
MongoDB基本操作
1.打开或者创建一个表,表名为xmu0134
use xmu0134
2.创建集合student
MongoDB没有单独创建集合名的命令,在插入数据的时候,Mongodb会自动创建对应的集合。MongoDB也不用去设计表,避免了像关系型数据库设计表时的麻烦和复杂。
3.插入数据
这里举个实例,插入集合Student,代码如下:
var data = [
... ... {Sno:95001,Sname:"李勇",Ssex:"男",Sage:20,Sdept:"CS"},
... ... {Sno:95002,Sname:"刘晨",Ssex:"女",Sage:19,Sdept:"IS"},
... ... {Sno:95003,Sname:"王敏",Ssex:"女",Sage:18,Sdept:"MA"},
... ... {Sno:95004,Sname:"张立",Ssex:"男",Sage:19,Sdept:"IS"}
... ... ]
db.Student.insert(data)
4.查询数据
db.Student.find();//查询所有数据
db.Student.find({Sno:95001});//条件查询
id是MongoDB自有产物,存储在集合中每个文档都有一个默认的主键_id,名称固定,同一个集合中文档_id的值必须是唯一的,不能重复。
5.增加数据
给学号为95003的学生添加课程成绩信息,Cno:2,Grade:68;Cno:3,Grade:75;
给学号为95004的学生添加课程成绩信息,Cno:3,Grade:97
6.查询数据
查询拥有课程3的学生,其中还有其他的逻辑表达查询这里不一一列出,可以自行搜索
Redis基本操作
1.增添数据
为学号为95001的学生选择三门课
2.查询数据
查询学号为95001学生选择的课程
3.条件查询
查询李勇和刘晨所选的公共课程名
4.更多
更多详细的shell命令,可以看这篇文章,点赞👍http://t.csdn.cn/vw7sI
参考:https://blog.csdn.net/wulj666/article/details/125380286
https://blog.csdn.net/qq_35005735/article/details/123895607

 浙公网安备 33010602011771号
浙公网安备 33010602011771号