
Python中fnmatch模块的功能
该模块提供了对Unix shell风格的通配符的支持,这不同于日常的同名表达(这是针对re模块的文档中说明的)。shell风格通配符中的特殊字符如下:
|
模式 |
含义 |
|
* |
匹配所有 |
|
? |
匹配所有单个字符 |
|
[seq] |
匹配seq中的任何字符 |
|
[!seq] |
匹配不出现在seq中的任意字符 |
对于线性匹配,包括括号中的元字符。例如,’[?]’匹配字符’?’。
注意:文件名分隔符(Unix中为’/’)不会在该模块中指定。参见glob模块中关于路径名部分(glob使用fnmatch()去匹配路径名片段)。同样的,文件名开始与一个该模块中未指定的周期,并且使用*和?模式进行匹配。
fnmatch. fnmatch(filename, pattern)
测试filename字符串是否匹配pattern字符串,返回True或False。所有的参数使用os.path.normcase().fnmatchcase()进行实例归一化,因此它们可以被用于执行区分大小的比较,无论再那种操作系统中都可以。
fnmatch 模块主要用于文件名称的匹配,其能力比简单的字符串匹配更强大,但比使用正则表达式相比稍弱。。如果在数据处理操作中,只需要使用简单的通配符就能完成文件名的匹配,则使用 fnmatch 模块是不错的选择。
Python fnmatch模块常用函数及功能
fnmatch 模块匹配文件名的模式使用的就是 UNIX shell 风格,其支持使用如下几个通配符:
*:可匹配任意个任意字符。
?:可匹配一个任意字符。
[字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。比如 [a-c] 可代表 a、b 和 c 字符中任意一个。
[!字符序列]:可匹配不在中括号里字符序列中的任意字符。
下面程序演示表 1 中一些函数的用法及功能:
import fnmatch
#filter()
print(fnmatch.filter(['dlsf', 'ewro.txt', 'te.py', 'youe.py'], '*.txt'))
#fnmatch()
for file in ['word.doc','index.py','my_file.txt']:
if fnmatch.fnmatch(file,'*.txt'):
print(file)
#fnmatchcase()
print([addr for addr in ['word.doc','index.py','my_file.txt','a.TXT'] if fnmatch.fnmatchcase(addr, '*.txt')])
#translate()
print(fnmatch.translate('a*b.txt'))
程序执行结果为:
['ewro.txt']
my_file.txt
['my_file.txt']
(?s:a.*b\.txt)\Z
原文链接:https://blog.csdn.net/ccc369639963/article/details/124012918
保存数据到excel文件中
1. 背景
xlwt是python中用于处理表格文件的第三方包,其中xlwt用于写,xlrt用于读。由于这里只需要写数据到excel文件中,故而这里就简单使用xlwt包。
安装:pip install xlwt -i https://pypi.douban.com/simple
参考:here
数据还是上篇的。
def saveUserInfo2EXCEL():
# 1. 创建一个工作簿workbook
xl = xlwt.Workbook(encoding='utf-8')
# 创建一个sheet对象,第二个参数是指单元格是否允许重设置,默认为False
sheet = xl.add_sheet('总用户信息', cell_overwrite_ok=True)
header_row = ["用户ID", "用户姓名", "性别", "电话", "QQ", "微信", "用户角色", "所属部门", "直接领导"]
datas = list(UserDB().getAllUserInfo())
for i in range(len(datas)):
data = [str(i+1), datas[i]['username'], datas[i]['sex'], datas[i]['phone'], datas[i]['qq'], datas[i]['weichat'], datas[i]['role'], datas[i]['department'], datas[i]['superior']]
if i==0:
for j in range(len(header_row)):
# 第一个参数代表行,第二个参数是列,第三个参数是内容,第四个参数是格式
sheet.write(i, j, header_row[j])
for k in range(len(data)):
sheet.write(i+1, k, data[k])
xl.save('download/UserInfo.xls')
然后,可以添加一个下载的链接:
from savepdf import saveUserInfo2PDF, saveUserInfo2EXCEL
@app.route("/download/excel/userinfo")
def downloadUserInfoEXCEL():
saveUserInfo2EXCEL()
return send_from_directory("download", filename="UserInfo.xls", as_attachment=True)
@app.route("/download/pdf/userinfo")
def downloadUserInfoPDF():
saveUserInfo2PDF()
return send_from_directory("download", filename="UserInfo.pdf", as_attachment=True)
注:download是项目路径下新建的文件夹。
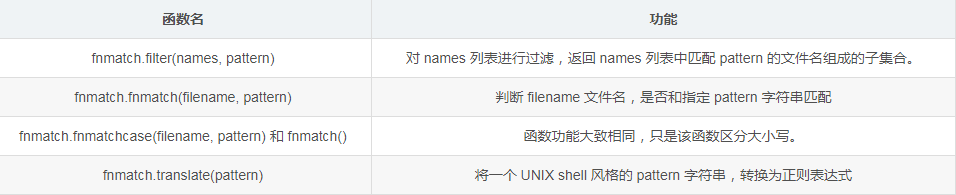
fnmatch 模块中,常用的函数及其功能如表 1 所示。
Python fnmatch模块常用函数及功能
函数名功能fnmatch.filter(names, pattern)对 names 列表进行过滤,返回 names 列表中匹配 pattern 的文件名组成的子集合。fnmatch.fnmatch(filename, pattern)判断 filename 文件名,是否和指定 pattern 字符串匹配fnmatch.fnmatchcase(filename, pattern) 和 fnmatch()函数功能大致相同,只是该函数区分大小写。fnmatch.translate(pattern)将一个 UNIX shell 风格的 pattern 字符串,转换为正则表达式fnmatch 模块匹配文件名的模式使用的就是 UNIX shell 风格,其支持使用如下几个通配符:
*:可匹配任意个任意字符。
?:可匹配一个任意字符。
[字符序列]:可匹配中括号里字符序列中的任意字符。该字符序列也支持中画线表示法。比如 [a-c] 可代表 a、b 和 c 字符中任意一个。
[!字符序列]:可匹配不在中括号里字符序列中的任意字符。————————————————版权声明:本文为CSDN博主「睿科知识云」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/ccc369639963/article/details/124012918

 浙公网安备 33010602011771号
浙公网安备 33010602011771号