
说一下条件编译以及编译中的引用和指针
通常情况,我们想让程序选择性地执行,多会使用分支语句,比如if-else 或者switch-case 等。但有些时候,可能在程序的运行过程中,某个分支根本不会执行。
比如我们要写一个跨平台项目,要求项目既能在Windows下运行,也能在Linux下运行。这个时候,如果我们使用if-else,如下:
Windows 有专有的宏_WIN32,Linux 有专有的宏__linux__
if(_WIN32)
printf("Windows下执行的代码\n");
else if(__linux__)
printf("Linux下执行的代码\n");
else
printf("未知平台不能运行!\n");
这段代码存在两个问题:1、 在Windows下并没有定义__linux__,编译的时候会报错,同样在Linux中也没有定义_WIN32。2、 假定这段程序可以运行,那么在Windows环境下另外两个分支的代码根本不可能运行,同理在Linux下也一样。
处理这种情况我们可以使用条件编译。条件编译,顾名思义,就是根据一定的条件进行选择性的编译,我们要达到的效果,就是在Windows环境下另外两个分支的语句根本不会编译,这样生成的可执行文件中,也不会还有对应语句的机器码,这样既提高了编译效率,同时也减小了可执行文件的体积。
条件编译通常可以用三种方式实现:
1、 #if--#elif--#else--#endif语句实现
通过这种方法实现的代码为:

#if(_WIN32)
printf("Windows下执行的代码\n");
#elif (__linux__)
printf("Linux下执行的代码\n");
#else
printf("未知平台不能运行!\n");
#endif
使用这种方式时需要注意,宏定义为真实#if才会执行,也就是说:
假如有宏定义#define _WIN32 0 这个时候#if是不会执行的。需要定义为#define _WIN32 1才会执行
2、 通过#ifdef--#else--#endif语句实现
通过这种方式实现的代码为
#ifdef(_WIN32)
printf("Windows下执行的代码\n");
#else
printf("Linux下执行的代码\n");
#endif
这种方法下只需要定义了_WIN32就可以,没有必要为真,也就是说
如果有宏定义#define _WIN32 0 上面#ifdef语句也是可以执行的,甚至#define _WIN32 上面的#ifdef也可以运行
当然也可以加入第一种方法中的#elif语句
#ifdef(_WIN32)
printf("Windows下执行的代码\n");
#elif (__linux__)
printf("Linux下执行的代码\n");
#else
printf("未知平台不能运行!\n");
#end
但是需要注意的是,这种情况下,要想#elif语句执行__linux__的值必须为真!(同时没有定义_WIN32)
3、 使用#ifndef语句,这种情况类似第二种,ifndef就是如果没有定义宏,就执行。
在gcc编译工具中
我们可以使用-D选项,动态地定义程序所需要的宏
比如我们可以这样编译 gcc test.c -o test -D _WIN32 这样程序就可以在Windows下运行了(当然,实际情况是在Windows环境下,_WIN32已经被定义) gcc中的-D选项会默认将宏定义为1,如果要定义为其他的值使用等于号如:-D _WIN32=0
很多的时候,尤其是实际的项目中,我们会使用cmake工具来构建自己的程序。
在cmake中
我们可以在CMakeLists.txt中写入ADD_DEIFNITIONS(-D _WIN32)来添加程序运行时用到的宏。但是这样,一旦我们需要修改使用的宏,就要修改CMakeLists.txt文件,会很麻烦。
这时我们可以这样做:
在CMakeLists.txt中写入
IF(ENVIRO)
ADD_DEFINITIONS(-D _WIN32)
ENDIF(ENVIRO)
这样,我们可以在使用cmake命令的时候加入-D选项,定义ENVIRO 命令如下
cmake -D ENVIRO=1,或者 cmake -D ENVIRO=ON
如果要取消这个定义可以使用: cmake -D ENVIRO=OFF 或 cmake -D ENVIRO=0 或者cmake -U ENVIRO
欲分析指针和引用,则要分析变量名和地址之间的关系(两句话概括:1、 指针就是地址,2、引用就是给变量起个别名)
所以我们就要来分析分析变量名和地址之间的关系。这就要从编译原理中的符号表说起,我们上编译原理的时候老师就没有将那一章,所以对于符号表,我的认识比较浅显,不过应该已经能够解释地址和变量名之间的关系啦。
编译器中通常要维护一个符号表,而且这个符号表是要贯串整个编译过程的。引用一张图说明
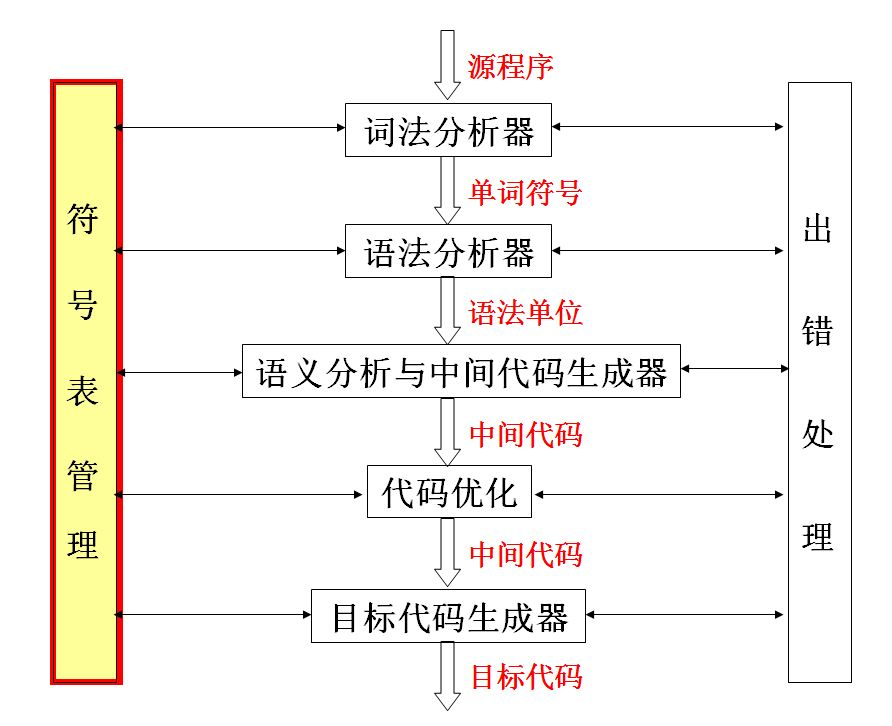
符号表在编译程序工作的过程中需要不断收集、记录和使用源程序中一些语法符号的类型和特征等相关信息。这些信息一般以表格形式存储于系统中。如常数表、变量名表、数组名表、过程名表、标号表等等,统称为符号表。对于符号表组织、构造和管理方法的好坏会直接影响编译系统的运行效率。
在编译过程中需要不断汇集和查证出现在源程序中的各种名字的属性和特征等信息编译器使用符号表来记录名字的作用域以及绑定信息编译程序中符号表用来存放语言程序中出现的有关标识符的属性信息,符号表中的信息在编译的不同阶段都用到在语义分析中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否一致)和产生中间代码在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。对一个多遍扫描的编译程序,不同遍所用的符号表也往往各有不同。因为每遍所关心的信息各有差异。
下面我们简化出一个符号表,专门用来解释变量名和地址之间的关系(重要,必须看)
假设我们定义了一个变量a :
int a = 10;
在编译器的编译的某个阶段(随着编译的进行,符号表是不断变化的)有如下符号表(我自己简化的,实际并不长这个样子)
|
变量名 |
首地址 |
类型 |
空间大小 |
值 |
|
a |
0x3333 |
int |
4字节 |
10 |
那么当我们将a++时,编译器会查找符号表,找到变量名为a的条目(符号表本质上就是一个表格,或者说是一个数据库),找到之后,根据a的首地址、类型、值等将a的值变为11
编译器将代码翻译成机器代码后,是没有变量名的,学过汇编的都知道,汇编语言都是直接操作地址的,根本没有变量名。
所以变量名可以理解为编译器符号表的一个索引,我们再做a++运算时,实际上编译器是根据变量名a找到了我们要操作的内存的首地址,然后在根据符号表中记录的属性,对该内存区域进行操作。
所以说变量名可以理解为地址的索引,或者说变量名代表了符号表中的一行。这一行中不进有首地址,还有类型、空间大小、值等。
所以我们要找到变量的地址需要用&(取地址)符号。(当然对于数组是不需要的)
所以我们可以这样说,变量名可以理解为被各种属性修饰的地址(这里的属性指类型、空间大小、值等)。进一步,变量名可以理解为一个受限制的地址(首各种属性的限制)
我们知道指针变量中存储的就是符号表中,某一行的首地址字段。然而只有这个首地址,没有那些属性(其他字段的限制),我们能做的事情就会很多:
我们可以人为的给这个首地址分配内存空间(malloc函数)、我们可以人为地给这个地址空间设定访问规则为按double类型访问(malloc时,强制类型转换成double),这也就是说我们可以人为规定首地址的类型和空间大小等属性
这也是指针的强大之处,指针中存的就是首地址,而这个首地址的各种属性都可以由程序员决定。
对吧!
但是通过变量名,我们可以访问到的地址是受限制的,因为在我们写int a= 10的时候,a的地址空间的大小、类型等都是编译器为我们分配和决定的!我们没有权利去做。但是通过声明一个指针,我们就可以自己决定这篇内存的属性!!!!
这也就是指针的强大之处,也是它的可怕之处。
所以一句话总结一下变量名和地址的关系就是:变量名可以理解为一个受各种属性限制的地址(而这些属性,是编译器决定的),指针就是地址,创建一个指针,就是创建一个不受各种属性限制的地址!!
再来说引用,引用就是变量的一个别名字,那我们写,比如int &b = a;这个时候编译器的符号表中就会多一个条目:
|
变量名 |
首地址 |
类型 |
空间大小 |
值 |
|
b |
0x3333 |
int |
4字节 |
10 |
发现没有,除了变量名不一样,其他的都一样!!!所以a和b就是一个东西
那么可以说,引用和指针的区别,就是变量名和指针的区别,进一步简单理解为变量名和首地址的区别!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号