


PubSub ——“发布/订阅”模式
订阅者(Sub)通过SUBSCRIBE 命令和PSUBSCRIBE命令向redis 服务订阅频道(channel),当发布者通过PUBLISH 命令向chinnel发布命令时,订阅该频道的客户端都会受到此消息。
##PUB/SUB 机制
三个客户端都订阅channel1频道
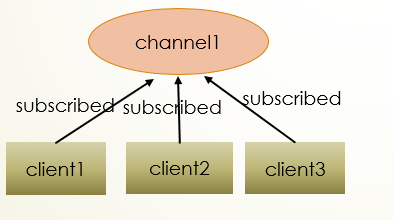
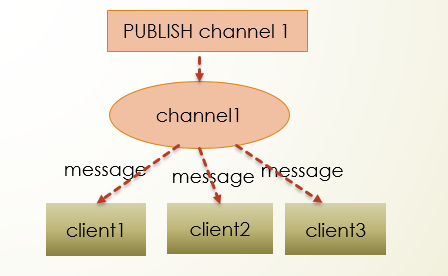
当有新消息通过PUBLISH命令发布到channel1时,这个消息会被发送给订阅这个频道的客户端。
redis中的pubsub机制:https://www.cnblogs.com/longjee/p/8668974.html
一个Redis client发布消息,其他多个redis client订阅消息,发布的消息“即发即失”,redis不会持久保存发布的消息;消息订阅者也将只能得到订阅之后的消息,通道中此前的消息将无从获得。
消息发布者,即publish客户端,无需独占链接,你可以在publish消息的同时,使用同一个redis-client链接进行其他操作(例如:INCR等)
消息订阅者,即subscribe客户端,需要独占链接,即进行subscribe期间,redis-client无法穿插其他操作,
此时client以阻塞的方式等待“publish端”的消息;因此这里subscribe端需要使用单独的链接,甚至需要在额外的线程中使用。
Tcp默认连接时间固定,如果在这时间内sub端没有接收到pub端消息,或pub端没有消息产生,sub端的连接都会被强制回收,
这里就需要使用特殊手段解决,用定时器来模拟pub和sub之间的保活机制,定时器时间不能超过TCP最大连接时间,具体根据机器环境来定;
一旦subscribe端断开链接,将会失去部分消息,即链接失效期间的消息将会丢失,所以这里就需要考虑到借助redis的list来持久化;
总结:pub发布的消息不会持久化,sub是阻塞等待消息,只能获取订阅之后的产生的消息,一段时间内sub没有收到消息或pub没有生产消息,sub连接会被回收(因为sub是阻塞的).
如果你非常关注每个消息,那么你应该基于Redis做一些额外的补充工作,如果你期望订阅是持久的,那么如下的设计思路可以借鉴:
1) subscribe端:
首先向一个Set集合中增加“订阅者ID”, 此Set集合保存了“活跃订阅”者,订阅者ID标记每个唯一的订阅者,此Set为 "活跃订阅者集合"
2) subcribe端开启订阅操作,并基于Redis创建一个以 "订阅者ID" 为KEY的LIST数据结构,此LIST中存储了所有的尚未消费的消息,此List称为 "订阅者消息队列"
3) publish端:
每发布一条消息之后,publish端都需要遍历 "活跃订阅者集合",并依次向每个 "订阅者消息队列" 尾部追加此次发布的消息.
4) 到此为止,我们可以基本保证,发布的每一条消息,都会持久保存在每个 "订阅者消息队列" 中.
5) subscribe端,每收到一个订阅消息,在消费之后,必须删除自己的 "订阅者消息队列" 头部的一条记录.
6) subscribe端启动时,如果发现自己的 "订阅者消息队列" 有残存记录, 那么将会首先消费这些记录,然后再去订阅.
以上方法可以保证成功到达的消息必消费不丢失;
pub/sub中消息发布者不需要独占一个Redis的链接,而消费者则需要单独占用一个Redis的链接,在java中便不得独立出分出一个线程来处理消费者。这种场景一般对应这多个消费者,此时则有着过高的资源消耗。
对于如上的几种不足,如果在项目中需要考虑的话可以使用JMS来实现该功能。JMS提供了消息的持久化/耐久性等各种企业级的特性。如果依然想使用Redis来实现并做一些数据的持久化操作,则可以根据JMS的特性来通过Redis模拟出来.
- subscribe端首先向一个Set集合中增加“订阅者ID”,此Set集合保存了“活跃订阅”者,订阅者ID标记每个唯一的订阅者,例如:sub:email,sub:web。此SET称为“活跃订阅者集合”
- subcribe端开启订阅操作,并基于Redis创建一个以“订阅者ID”为KEY的LIST数据结构,此LIST中存储了所有的尚未消费的消息。此LIST称为“订阅者消息队列”
- publish端:每发布一条消息之后,publish端都需要遍历“活跃订阅者集合”,并依次向每个“订阅者消息队列”尾部追加此次发布的消息。
- 到此为止,我们可以基本保证,发布的每一条消息,都会持久保存在每个“订阅者消息队列”中。
- subscribe端,每收到一个订阅消息,在消费之后,必须删除自己的“订阅者消息队列”头部的一条记录。
- subscribe端启动时,如果发现自己的自己的“订阅者消息队列”有残存记录,那么将会首先消费这些记录,然后再去订阅。
协程通信机制——Pub/Sub
新的协程框架VLCP。它使用的是一种Pub/Sub模型,即发布者、订阅者模型,这是常用于消息队列中的模型,熟悉消息队列用法就会非常熟悉这一套用法。接下来我们详细介绍一下这一套方法,并且看一下这种设计如何结合前几种方案的优点,弥补前几种方案的缺点。
在Pub/Sub模型中,主要分为三个不同的角色:
- 发送方:通过send方法发送一个事件
- 接收方:通过参数订阅并接收一个事件
- 管理:调整事件的优先顺序等
管理也可以由发送方或接收方中任意一个来兼任,主要目的是在许多事件同时存在时,调整优先级顺序,从而影响协程的执行先后次序。
在VLCP当中,发送通过scheduler.send(或者更高层的RoutinerContainer.waitForSend),接收则通过yield语句,可以非常容易的进行。管理则通过调整调度器队列设置进行。
VLCP中的事件是vlcp.event.Event的子类,它首先根据子类类型进行区分,但与其他框架不同,子类可以进一步携带一组索引,用来标识这个事件的不同性质,它与事件类型一起共同起着类似于Pub/Sub中的主题(Topic)的作用。比如说,我们处理OpenFlow协议中的PACKET_IN消息,现在希望定义一种事件来表示有一个PACKET_IN消息到来了,对于接收方来说,可能关心的信息有:消息来自于哪个datapath;来自于哪个连接对象;由哪个table中、cookies为多少的流表生成。我们可以将这些信息作为索引来定义这个事件:
from vlcp.event import Event, withIndices
@withIndices('datapath', 'connection', 'table' 'cookies')
class OpenFlowPacketInEvent(Event):
pass
如你所见,定义一个事件非常容易,而定义一个事件几乎就完成了通信需要进行的所有准备工作——不需要创建额外的Future或者Channel对象,甚至,不需要关心要进行通信的双方究竟是谁、在哪、有多少个。使用注解withIndices来定义一个Event的索引,这是必须的,即使Event没有可选的索引,也必须用@withIndices()来表明Event没有索引。
接下来,处理OpenFlow协议的协程会在这个事件发生时通知需要处理事件的协程,它只需要调用发送方的标准方法:
for m in container.waitForSend(OpenFlowPacketInEvent(
conn.datapath,
conn,
message.table,
message.cookies,
message = message
)):
yield m
在这个过程中,我们创建了一个新的Event的实例,并提供了相应的索引的值。除了规定的索引值以外,我们还可以给这个Event对象提供额外的属性,它可以直接通过keyword-argument在构造函数中初始化,也可以在创建后再进行属性赋值。所有的索引也会自动被赋给相应的属性,比如说newevent.datapath就会得到datapath索引的值。将这个对象传递给waitForSend过程就完成了发送,waitForSend是个协程过程,使用for来在外层协程中代理这个过程,在Python3当中也可以更简单写成yield from container.waitForSend(...)
那么接下来是接收方的问题,接收方不需要关心事件何时由谁发出,当需要等待一个新的事件发生的时候,只需要简单使用:
packet_in_matcher = OpenFlowPacketInEvent.createMatcher(None, None, my_table, my_cookies)
# Or:
# packet_in_matcher = OpenFlowPacketInEvent.createMatcher(table = my_table, cookies = my_cookies)
yield (packet_in_matcher,)
在协程中使用yield会暂停协程执行,在VLCP中,yield返回的是一个EventMatcher构成的元组,它可以包含一个或多个EventMatcher。EventMatcher通过Event子类的createMatcher方法创建,它代表一种匹配规则,即匹配这个子类的Event中,相应索引匹配相应值的事件。返回多个EventMatcher时,yield语句会在某个事件匹配任意一个EventMatcher时返回。匹配到的EventMatcher会保存在container.matcher,而发生的事件会保存在container.event。
VLCP内部使用前缀树的数据结构对Event和EventMatcher进行匹配,这是一个很有效率的数据结构,将Event匹配到相应的EventMatcher只需要O(1)的时间。
对同一个事件,不同的协程可以通过createMatcher时的不同参数,来匹配事件集合的不同的子集,这在处理量非常大的时候可以有效提高处理效率,同时不增加程序复杂度。除了使用索引以外,还可以增加一个自定义的筛选过程:
customized_matcher = OpenFlowPacketInEvent.createMatcher(
table = my_table,
cookies = my_cookies,
_ismatch = lambda x: len(x.message.data) < 100)
_ismatch的keyword参数用来指定一个函数用于筛选,它接受Event作为唯一的参数,返回True或者False表示是否应当匹配这个Event。_ismatch只有指定索引值已经匹配的情况下才会进行计算。
Event的子类可以进一步派生。进一步派生的Event会继承父类的类型和索引,但也会有自己的类型和索引。子类的子类遵循一般的继承派生的规则:父类的EventMatcher可以匹配子类的Event,但子类的EventMatcher不能匹配父类的Event。比如:
@withIndices('a', 'b')
class MyEventBase(Event):
pass
@withIndices('c', 'd')
class MyEventChild(MyEventBase):
pass
MyEventChild(1,2,3,4) # a = 1, b = 2, c = 3, d = 4
MyEventBase.createMatcher(1,2).isMatch(MyEventChild(1,2,3,4)) # True
MyEventChild.createMatcher(1,2).isMatch(MyEvent(1,2)) # False
利用这种特殊的继承关系可以拓展原有逻辑,在兼容以前代码的情况下提供新的功能。
VLCP的事件循环结构
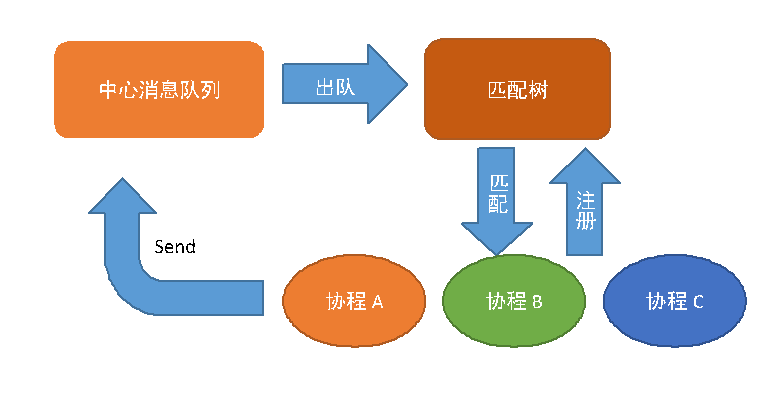
VLCP的事件循环结构可以用上图表示。所有在调度器中运行的协程,都会在暂停运行时将自己注册到匹配树中,与一个或多个EventMatcher进行关联,这个过程通过yield语句完成。在事件循环运行过程中,调度器每次从中心队列中取出一个事件,在匹配树中查找与这个事件匹配的EventMatcher和相关联的协程,然后依次唤醒这些协程,通知它们等待的事件已经发生;协程在运行时,可以将事件通过send过程发送到中心消息队列。在协程停止运行时,协程重新使用yield语句将自己注册到匹配树中,等待下一个循环。
当消息队列为空或无法出队时,调度器会调用Poller(在Linux当中由EPoll实现,其他操作系统当中使用Select)等待socket活动。Poller会将socket的活动返回成PollEvent,这同样是Event的子类,这些事件会由负责处理socket活动的协程进行处理,然后进一步产生后续的事件。当没有活动的socket时,调度器会开始引导整个框架退出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号