over fit与underfit的区别与解决方法
overfit有两种情况:1.机器从样本数据中过度的学习了太多的局部特征,在测试集中会出现识别率低的情况。信息量过小,识别其他信息是缺少数据特征量,学习的东西太多了,特征也多,只要不是该特征的数据都不要,这个过度拟合是因为数据量太小但是学习的特征太多,只要没有其中任何的一个特征的数据都识别不了的一种过度拟合的情况。举个例子:
(1)打个形象的比方,给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“2”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。
(2)然后,很不巧你的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅.
(3)好,来分析一下上面这个例子:(1)中的规律都是对的,所有的天鹅都有的特征,是全局特征;然而,(2)中的规律:天鹅的羽毛是白的.这实际上并不是所有天鹅都有的特征,只是局部样本的特征。机器在学习全局特征的同时,又学习了局部特征,这才导致了不能识别黑天鹅的情况.
所以:(1)对于机器来说,在使用学习算法学习数据的特征的时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习的那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征.
(2)在学习算法的作用下,机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能习得一部分局部特征,而习得的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题.
(3)所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的.
(4)解决过拟合的方法,其基本原理就是限制机器的学习,使机器学习特征时学得不那么彻底,因此这样就可以降低机器学到局部特征和错误特征的几率,使得识别正确率得到优化.
(5)从上面的分析可以看出,要防止过拟合,训练数据的选取也是很关键的,良好的训练数据本身的局部特征应尽可能少,噪声也尽可能小。
2.过度拟合学习了太多的噪音,人们将噪声误认为信号的行为,在统计学上被称为「过度拟合」(overfit)。人类大脑的工作方式是捕捉规律,并且预测。一般来讲,智商高的人的神经网络学习能力更强,这意味着 ta 捕捉规律的能力也越强。捕捉规律能力强意味着对于很少的样本中隐含的不明显的「规律」他们也能捕捉出来。但从很少的样本或噪声过多的样本中总结出「规律」来是极为危险的事——自然界的运行很多时候并没有确定的规律,我们带着一双为了发现规律的眼睛去挖掘总结出了规律,结果却聪明反被聪明误了。
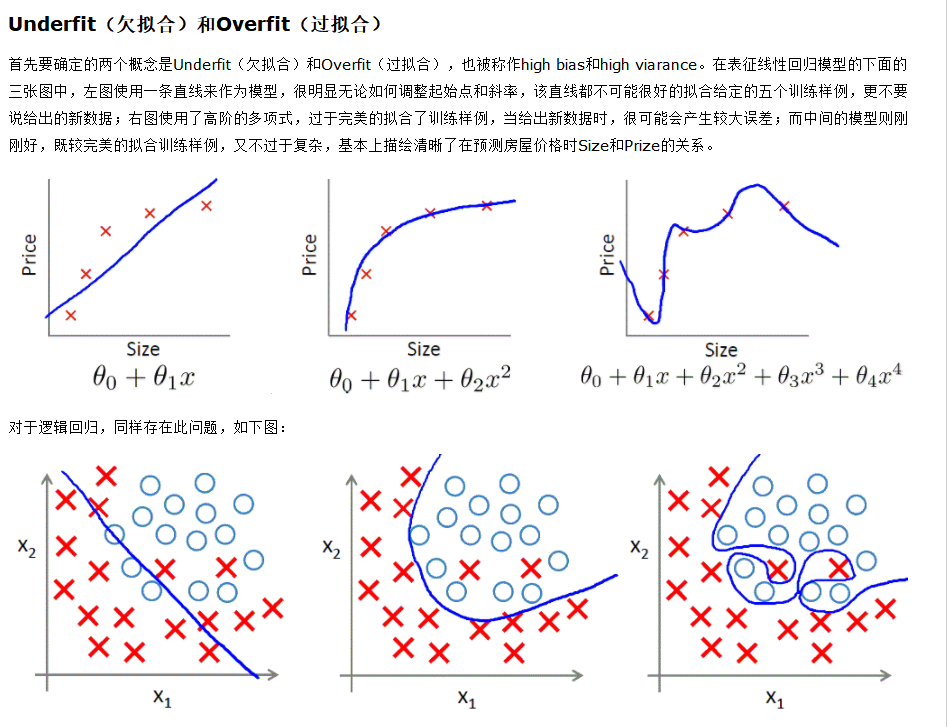
一句话概括:
过拟合:在训练数据上表现良好,在未知数据上表现差。
欠拟合:在训练数据和未知数据上表现都很差。
解决方法:
解决欠拟合或过拟合的思路
1、增减模型的参数维度。如利用线性回归预测房屋价格的例子中,增加“卧室数量”,“停车位数量”,“花园面积”等维度以解决欠拟合,或相应的减少维度去解决过拟合。
2、增减多项式维度,比如将加入高阶多项式来更好地拟合曲线,用以解决欠拟合,或者降阶去处理过拟合。
3、调整Regularization Parameter。在不改变模型参数维度和多项式维度的情况下,单纯的调整Regularization Parameter同样可以有效改变模型对数据的拟合程度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号