

LIRE教程之源码分析 | LIRE Tutorial of Analysis of the Source Code
LIRE教程之源码分析 |LIRE Tutorial of Analysis of the Source Code
最近在做地理图像识别和检索的研究,发现了一个很好用的框架LIRE,遂研究了一通。网上的教程不算很多,而且LIRE更新比较快,一些方法已经更新或废弃,故想写几篇文章重新总结一下框架内的多种方法,方便他人使用。
LIRE(Lucene Image Retrieval)是一个开源的轻量级图像识别Java框架,提供了多种简单易用的图片检索方法。事实上,LIRE是基于Lucene这个全文检索引擎修改的,也沿用了该检索引擎的思路。
LIRE相关资料:
官网首页:http://www.lire-project.net/
下载地址:http://www.itec.uni-klu.ac.at/~mlux/lire-release/
Github:https://github.com/dermotte/LIRE
官方文档:https://github.com/dermotte/LIRE/blob/master/src/main/docs/developer-docs/docs/index.md
官方教程:http://www.semanticmetadata.net/wiki/
在进入正文之前,再推荐一下DaveBobo的博客,作者已经总结了不少方法,可以参考:https://blog.csdn.net/davebobo/article/category/6466512
在下载LIRE之后,同时也要确保Lucene相关的jar包没有缺失。
接下来进入正题。本文的内容是结合官方给出的Sample Application,完成图片的提取特征、索引生成、图片检索。下载地址:[LIRE Sample Application]

笔者使用的是Intellij Idea。首先导入工程。从左边的文件夹中,可以发现LIRE的class都在net.semanticmetadata.lire这个文件夹中,而官方给出的案例则在net.semanticmetada.sampleapplication中。
图片特征提取和索引生成
打开案例中的Index.java文件(Github),点击右上角的三角,修改Idea的配置文件,输入图片文件夹的路径。
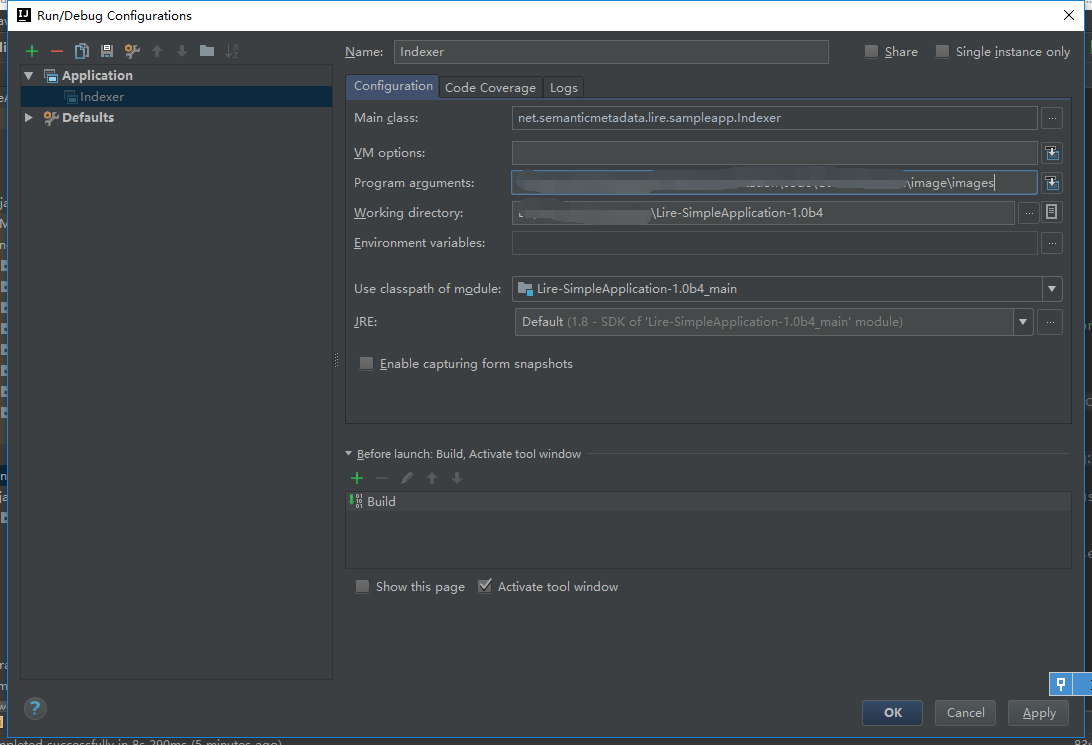
运行,等待程序结束后发现右边文件夹多出了一个index文件。
事实上,这个程序是最基本的索引文件。其步骤是:
(1) 读取输入文件夹下所有的照片文件。
(2) 设置提取图片要素的方法和descriptors。
(3) 对图片进行特征提取并写入索引。
其中,重点在于图片特征的提取方法。根据源码,可以发现首先建立了一个GlobalFeatureBuilder。这相当于图片提取的容器,再设置了图片提取要素的方法,在这段源码中包括CEDD,FCTH,AutoColorCorrelogram这三种方法。事实上,除了这些方法之外,还可以参考lib/net.semanticmetadata.lire/imageanalysis/features/global这个文件夹下的其他类,这个文件夹下包括了LIRE中包含的全局要素提取方法。
GlobalDocumentBuilder globalDocumentBuilder = new GlobalDocumentBuilder(false, false);
globalDocumentBuilder.addExtractor(CEDD.class);
globalDocumentBuilder.addExtractor(FCTH.class);
globalDocumentBuilder.addExtractor(AutoColorCorrelogram.class);
接下来,只要使用GlobalDocumentBuilder.createDocument()方法就可以完成图片的特征提取。提取之后还需要建立索引,从而方便之后的图片检索。LIRE是建立在Lucene的基础上的,通过Lucene可以非常快速建立文档及其索引。新建一个IndexWriter,并将图片的特征写入其中。具体代码是下面这一段:
BufferedImage img = ImageIO.read(new FileInputStream(imageFilePath));
Document document = globalDocumentBuilder.createDocument(img, imageFilePath);
iw.addDocument(document);
即从本地上读取图片,再进行图片的特征提取,最后生成索引文件。
图片检索
在完成图片的特征提取之后,下一步是进行图片的检索,即给定一张图片,找出与这张图片最相似的图片。
打开案例中的Searcher.java文件(Github)。修改Idea配置文件,传入给定图片的路径。
运行之后可以发现输出了一串从小到大的分数及其具体的图片路径。分数越小说明该图片与给定图片越相似。如果分数为0说明两者一样。

这个程序是最基本的检索文件。其步骤是:
(1) 读取给定的图片。
(2) 读取之前生成的图片索引,寻找与给定图片最相似的图片。
(3) 输出相似度分数及具体的图片。
根据源码,可以发现使用了IndexReader读取了索引文件,之前是使用IndexWriter将这些索引文件写入了硬盘。
IndexReader ir = DirectoryReader.open(FSDirectory.open(Paths.get("index")));
接下来使用了ImageSearcher.search()方法寻找最相似的图片。其方法是使用CEDD方法对给定的图片进行特征提取,之后在索引中进行搜索。在这段代码中,返回与给定图片最相似的30张图片。ImageSearchHits即为最相似的图片,可以从中获取相似度分数和图片路径等。
ImageSearcher searcher = new GenericFastImageSearcher(30, CEDD.class);
ImageSearchHits hits = searcher.search(img, ir);
以上构成了一个完整的图片特征提取-生成索引-图片检索步骤,使用这两份代码已经满足基础的使用了。
